上一篇使用Docker搭建了Hadoop的完全分布式:使用Docker搭建Hadoop集群(伪分布式与完全分布式),本次记录搭建spark集群,使用两者同时来实现之前一直未完成的项目:网站日志流量分析系统(该系统目前用虚拟机实现了离线分析模块,实时分析由于资源问题尚未完成---这次spark集群用于该项目的实时分析)
一、根据架构图搭建基础环境

①Scala版本:2.13以及JDK版本:1.8.231,scala下载地址:https://www.scala-lang.org/download/(安装过程略)
②Docker版本:Docker version 19.03.5,下载地址:https://docs.docker.com/install/linux/docker-ce/centos/(安装过程略)
③搭建zookeeper集群(版本:3.4.14),下载地址:http://mirror.bit.edu.cn/apache/zookeeper/
④搭建hadoop集群(版本:2.7.7),下载地址:https://archive.apache.org/dist/hadoop/common/
⑤安装flume(版本:1.9.0),下载地址:http://flume.apache.org/download.html
⑥搭建Kafka集群(版本:2.4.0),下载地址:http://kafka.apache.org/downloads
⑦搭建HBase集群(版本:0.98.17),下载地址:https://archive.apache.org/dist/hbase/
⑧搭建Spark集群(版本:2.4.4),下载地址:https://www.apache.org/dyn/closer.lua/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz
基于以上环境来搭建Spark集群,最终实现网站流量的实时分析(离线分析模块已完成)--------网站日志流量分析系统,鄙人使用6个容器来实现以上环境的搭建,如下所示

二、启动容器并固定IP
可参考鄙人博客:使用Docker搭建Hadoop集群(伪分布式与完全分布式)里面有固定ip相关说明。
1、Dockerfile构建具备ssh的centos镜像
1.1编写Dockerfile


FROM centos # 镜像的作者 MAINTAINER xiedong # 安装openssh-server和sudo软件包,并且将sshd的UsePAM参数设置成no RUN yum install -y openssh-server sudo RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config #安装openssh-clients RUN yum install -y openssh-clients # 添加测试用户root,密码root,并且将此用户添加到sudoers里 RUN echo "root:root" | chpasswd RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key # 启动sshd服务并且暴露22端口 RUN mkdir /var/run/sshd EXPOSE 22 CMD ["/usr/sbin/sshd", "-D"]
1.2构建镜像
docker build -t 'xd/centos-ssh' . #注意别忘记末尾的点
2、Dockerfile构建具备JDK1.8的centos镜像
2.1编写Dockerfile
#基于上一个ssh镜像构建 FROM xd/centos-ssh #拷贝并解压jdk ADD jdk-8u231-linux-x64.tar.gz /usr/local/ RUN mv /usr/local/jdk1.8.0_231 /usr/local/jdk1.8 ENV JAVA_HOME /usr/local/jdk1.8 ENV PATH $JAVA_HOME/bin:$PATH
2.2构建镜像
docker build -t 'xd/centos-jdk' .
3、查看构建镜像
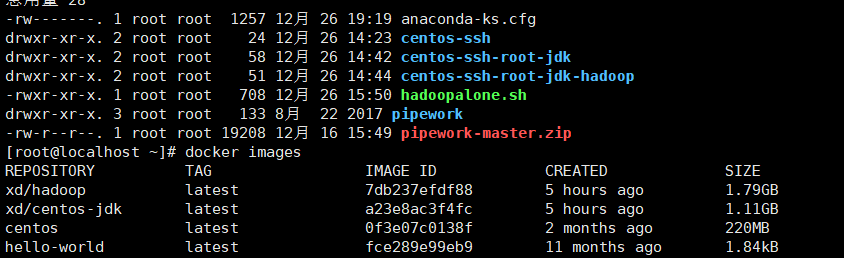
4、Docker容器数据卷共享文件
建议还是针对不同容器建立不同数据卷,鄙人为了方便,但是这样浪费空间了。
4.1 宿主机建立目录并上传软件
mkdir -p /home/container-softwares
4.2宿主机界面
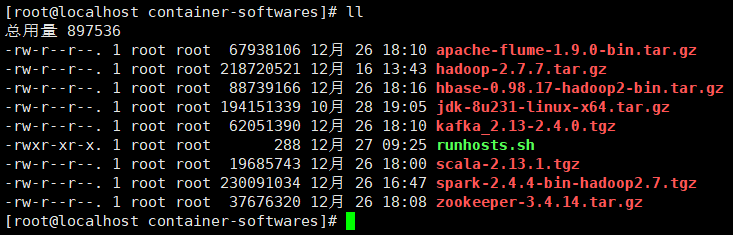
ps:runhosts.sh脚本用于配置hosts文件映射,后续需要ssh配置免密登录。
#!/bin/bash echo 192.168.2.10 hadoop0 >> /etc/hosts echo 192.168.2.11 hadoop1 >> /etc/hosts echo 192.168.2.12 hadoop2 >> /etc/hosts echo 192.168.2.20 spark0 >> /etc/hosts echo 192.168.2.21 spark1 >> /etc/hosts echo 192.168.2.22 spark2 >> /etc/hosts
5、启动容器并固定IP
由于每次开机重启Docker、重启容器比较麻烦,所以弄一个脚本最好
5.1容器初始化脚本(第一次执行)
#/bin/bash #启动Docker sudo systemctl restart docker echo "Docker restarts successfully!" #启动6个容器 #NameNode-zk-HBase-Flume docker run --name hadoop0 --hostname hadoop0 -v /home/container-softwares:/home/container-softwares -d -P -p 50070:50070 -p 8088:8088 -p 2181:2181 xd/centos-jdk echo "hadoop0 container start success=====" #DataNode--zk-HBase-Flume docker run --name hadoop1 --hostname hadoop1 -v /home/container-softwares:/home/container-softwares -d -P xd/centos-jdk echo "hadoop1 container start success=====" #DataNode-zk-HBase-Flume docker run --name hadoop2 --hostname hadoop2 -v /home/container-softwares:/home/container-softwares -d -P xd/centos-jdk echo "hadoop2 container start success=====" #spark0-kafka节点 docker run --name spark0 --hostname spark0 -v /home/container-softwares:/home/container-softwares -d -P xd/centos-jdk echo "spark0 container start success=======" #spark1-kafka节点 docker run --name spark1 --hostname spark1 -v /home/container-softwares:/home/container-softwares -d -P xd/centos-jdk echo "spark1 container start success=====" #spark2-kafka节点 docker run --name spark2 --hostname spark2 -v /home/container-softwares:/home/container-softwares -d -P xd/centos-jdk echo "spark2 container start success=====" #固定IP======== #pipework下载 yum install -y wget bridge-utils unzip #wget https://github.com/jpetazzo/pipework/archive/master.zip unzip pipework-master-old.zip mv pipework-master pipework cp -rp pipework/pipework /usr/local/bin/ -f #创建网络 brctl addbr br0 ip link set dev br0 up ip addr add 192.168.2.1/24 dev br0 echo "网络创建完成正在固定IP" pipework br0 hadoop0 192.168.2.10/24 pipework br0 hadoop1 192.168.2.11/24 pipework br0 hadoop2 192.168.2.12/24 pipework br0 spark0 192.168.2.20/24 pipework br0 spark1 192.168.2.21/24 pipework br0 spark2 192.168.2.22/24 echo "固定IP完成,正在测试" for i in {10,11,12,20,21,22} do ips=192.168.2.$i result=`ping -w 2 -c 3 ${ips} | grep packet | awk -F" " '{print $6}'| awk -F"%" '{print $1}'| awk -F' ' '{print $1}'` if [ $result -eq 0 ]; then echo ""${ips}" is ok !" else echo ""${ips}" is not connected ....." fi done echo "测试完成"
5.2 容器启动脚本(关机重启后执行)
注:该脚本用于已经初始化过的容器
#/bin/bash #启动Docker sudo systemctl restart docker echo "Docker restarts successfully!" #启动6个容器 docker start hadoop0 hadoop1 hadoop2 spark0 spark1 spark2 #固定IP brctl addbr br0 ip link set dev br0 up ip addr add 192.168.2.1/24 dev br0 pipework br0 hadoop0 192.168.2.10/24 pipework br0 hadoop1 192.168.2.11/24 pipework br0 hadoop2 192.168.2.12/24 pipework br0 spark0 192.168.2.20/24 pipework br0 spark1 192.168.2.21/24 pipework br0 spark2 192.168.2.22/24 echo "固定IP完成,正在测试" for i in {10,11,12,20,21,22} do ips=192.168.2.$i result=`ping -w 2 -c 3 ${ips} | grep packet | awk -F" " '{print $6}'| awk -F"%" '{print $1}'| awk -F' ' '{print $1}'` if [ $result -eq 0 ]; then echo ""${ips}" is ok !" else echo ""${ips}" is not connected ....." fi done echo "测试完成"
5.3容器停止脚本
#/bin/bash sudo docker stop hadoop0 hadoop1 hadoop2 spark0 spark1 spark2 echo "容器已停止" systemctl stop docker echo "docker 服务已停"
5.4执行初始化脚本,出现以下界面说明成功
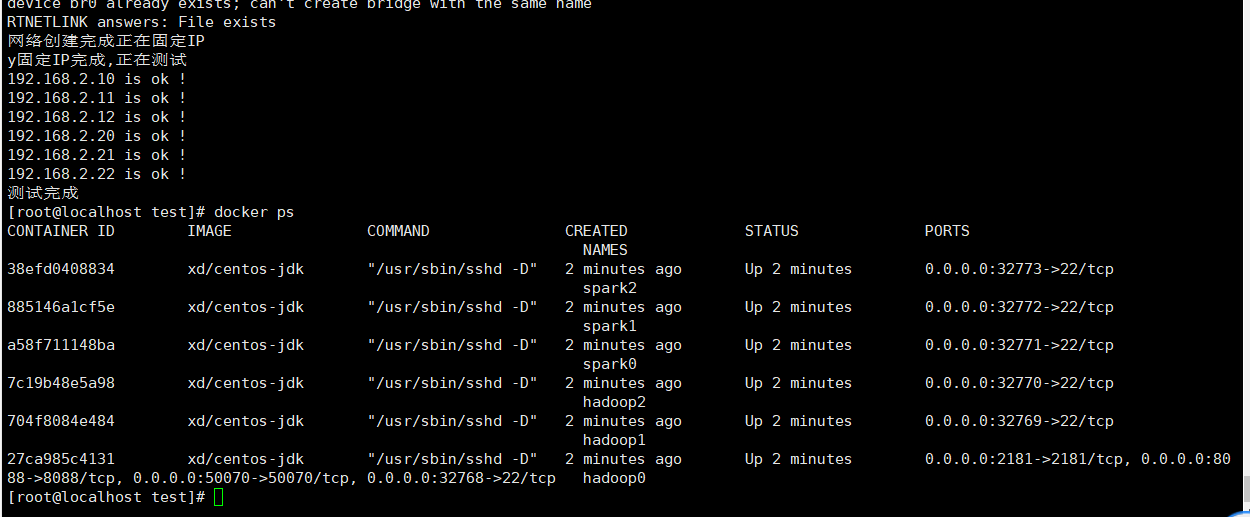
三、基础环境搭建
1、搭建Zookeeper集群
注:根据之前的部署结构,Zookeeper搭建在hadoop0、hadoop1、hadoop2这3个容器,安装过程可参考鄙人之前博客:zookeeper集群的搭建,其中Zookeeper的相关安装包已经通过容器数据卷共享到容器内部路径:/home/container-softwares(可通过初始化脚本看出),最终实现效果如下:
1.1Hadoop0容器zk角色为leader
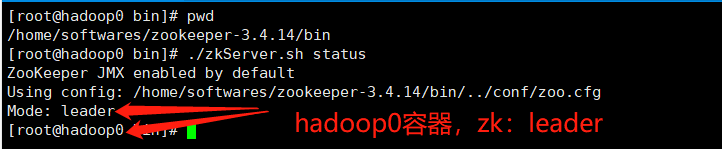
1.2Hadoop1容器zk角色为follower

1.3Hadoop2容器zk角色为follower

2、搭建Hadoop集群
注:根据之前的部署结构,Hadoop集群搭建在hadoop0、hadoop1、hadoop2这3个容器,安装过程可参考鄙人之前博客:使用Docker搭建Hadoop集群(伪分布式与完全分布式),其中Hadoop的相关安装包已经通过容器数据卷共享到容器内部路径:/home/container-softwares(可通过初始化脚本看出),最终实现效果如下:
2.1Hadoop0容器有以下进程
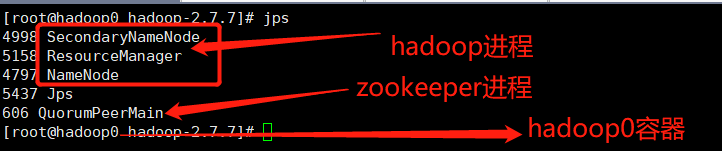
2.2Hadoop1容器有以下进程

2.3Hadoop2容器有以下进程

3、搭建HBase集群
注:根据之前的部署结构,HBase搭建在hadoop0、hadoop1、hadoop2这3个容器(安装过程可参考鄙人之前博客:HBase的完全分布式搭建),此HBase集群主要服务于Spark实时分析产生的中间临时数据(架构图中可查看),其中HBase的相关安装包已经通过容器数据卷共享到容器内部路径:/home/container-softwares(可通过初始化脚本看出),最终实现效果如下:
3.1Hadoop0容器有以下进程

3.2Hadoop1容器有以下进程

3.3Hadoop2容器有以下进程

4、搭建Kafka集群
注:根据之前的部署结构,Kafka搭建在spark0、spark1、spark2这3个容器(安装过程可参考鄙人之前博客:Kakfa概述及安装过程),Kafka负责接收Flume中心服务器产生的数据并对接spark用于实时分析,其中Kafka的相关安装包已经通过容器数据卷共享到容器内部路径:/home/container-softwares(可通过初始化脚本看出),最终实现效果如下:
4.1Spark0容器有以下进程

4.2Spark1容器有以下进程

4.3Spark2容器有以下进程

5、安装Flume
注:根据之前的部署结构,Flume搭建在hadoop0、hadoop1、hadoop2这3个容器(安装过程可参考鄙人之前博客:Flume学习笔记),Hadoop0的flume作为架构图中的FlumeAgent、另外2个容器中的flume作为中心日志服务器落地HDFS以及Kafka消息队列,其中Flume的相关安装包已经通过容器数据卷共享到容器内部路径:/home/container-softwares(可通过初始化脚本看出),最终实现效果如下:
5.1Hadoop0容器的FlumeAgent相关配置
#声明Agent a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 #声明source a1.sources.r1.type = avro a1.sources.r1.bind = 0.0.0.0 a1.sources.r1.port =44444 a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = regex_extractor a1.sources.r1.interceptors.i1.regex = ^(?:[^\|]*\|){14}\d+_\d+_(\d+)\|.*$ a1.sources.r1.interceptors.i1.serializers = s1 a1.sources.r1.interceptors.i1.serializers.s1.name = timestamp #声明sink a1.sinks.k1.type = avro a1.sinks.k1.hostname =hadoop1 a1.sinks.k1.port =44444 a1.sinks.k2.type = avro a1.sinks.k2.hostname =hadoop2 a1.sinks.k2.port =44444 a1.sinkgroups = g1 a1.sinkgroups.g1.sinks = k1 k2 a1.sinkgroups.g1.processor.type = load_balance a1.sinkgroups.g1.processor.backoff = true a1.sinkgroups.g1.processor.selector = random #声明channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 #绑定关系 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c1
ps:负责收集应用程序产生的日志并通过负载均衡分发给2个中心日志服务器
5.2Hadoop1与Hadoop2容器的Flume中心日志服务器相关配置
#声明Agent a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 c2 #声明source a1.sources.r1.type = avro a1.sources.r1.bind = 0.0.0.0 a1.sources.r1.port = 44444 #声明sink a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = hdfs://hadoop0:9000/logdemo/reportTime=%Y-%m-%d a1.sinks.k1.hdfs.rollInterval = 30 a1.sinks.k1.hdfs.rollSize = 0 a1.sinks.k1.hdfs.rollCount = 0 a1.sinks.k1.hdfs.fileType = DataStream a1.sinks.k1.hdfs.timeZone = GMT+8 a1.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k2.topic = fluxtopic a1.sinks.k2.brokerList = spark0:9092,spark1:9092,spark2:9092 #声明channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.channels.c2.type = memory a1.channels.c2.capacity = 1000 a1.channels.c2.transactionCapacity = 100 #绑定关系 a1.sources.r1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2
ps:中心日志服务器负责接收FlumeAgent客户端日志并落地HDFS以及分发Kafka(2个容器的配置相同)
6、搭建Spark集群
搭建好以上环境后,开始搭建Spark环境
注:根据之前的部署结构,Spark搭建在spark0、spark1、spark2这3个容器,其中Spark的相关安装包已经通过容器数据卷共享到容器内部路径:/home/container-softwares(可通过初始化脚本看出)
6.1配置环境变量
export SCALA_HOME=/usr/local/scala/scala-2.13.1 export PATH=$PATH:$SCALA_HOME/bin export JAVA_HOME=/usr/local/jdk1.8 export SPARK_HOME=/home/softwares/spark-2.4.4-bin-hadoop2.7 export PATH=$PATH:$SPARK_HOME/bin export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
6.2修改配置文件spark-env.sh(增加以下配置)
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
export JAVA_HOME=/usr/local/jdk1.8 export SCALA_HOME=/usr/local/scala/scala-2.13.1 export SPARK_MASTER_IP=192.168.2.20 export SPARK_WORKER_MEMORY=512m export HADOOP_CONF_DIR=/home/softwares/hadoop-2.7.7/etc/hadoop
6.3编辑slaves
cp slaves.template slaves
vim slaves
#增加如下配置
spark0
spark1
spark2
6.4拷贝至其他2个容器
scp -rq spark-2.4.4-bin-hadoop2.7 spark1:/home/softwares/ scp -rq spark-2.4.4-bin-hadoop2.7 spark2:/home/softwares/
6.5启动spark集群
sbin目录执行:./start-all.sh
6.6spark0容器有以下进程

6.7spark0容器有以下进程

6.8spark0容器有以下进程

至此、已经完成Spark集群的搭建,下一篇编写scala代码实现网站流量实时分析:Scala实现网站流量实时分析