贝叶斯定理(Bayes Theorem)
朴素贝叶斯分类(Naive Bayes Classifier)
贝叶斯分类算法(NB),是统计学的一种分类方法,它是利用贝叶斯定理的概率统计知识,对离散型数据进行分类的算法。
朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
tips:python中sklearn包的naive_bayes模块中,由三种贝叶斯算法类型:
- GaussuanNB 高斯贝叶斯 :适用于特征值符合正态分布的数据,不需要知道具体每个样本的数值,只需知道样本符合什么样的正态分布(均值、方差)即可计算;
- BernoulliNB 伯努利贝叶斯:适用于特征值符合伯努利分布的数据,即是/否,0/1;
- MultinomialNB 多项式贝叶斯:不知道特征值符合哪种分布的时候,使用多项式贝叶斯算法计算每个特征的概率,所以需要知道每个特征值的数值大小(最常用于文本分类)。
使用多项式贝叶斯进行分本分类的实现:
#构建语料库,需要包含文本分类
#进行分词
#文本向量化
#构建多项式贝叶斯模型
from sklearn.naive_bayes import MultinomialNB #多项式贝叶斯分类模型建立 MNBmodle = MultinomialNB() #将文本向量作为特征值传入,将分类序列作为目标序列传入 MNBmodle.fit(textVector,corpos['class']) MNBmodle.score(textVector,corpos['class'])
tips:多项式贝叶斯非常适用于文本分类
#针对新文本进行分类(需要进行分词和向量化操作),得到分类预测
MNBmodle.predict(newTextVector)
决策树(Decision Tree)
决策树通过对训练样本的学习,并建立分类规则,然后依据分类规则,对新样本数据进行分类预测,属于有监督学习。
决策树是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。
由于这种决策分支画成图形很像一棵树的枝干,故称决策树。
在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
优点:
决策树易于理解和实现
决策树可同时处理数值型和非数值型数据
缺点:
对连续性的字段较难预测
对有时间顺序的数据,需要很多的预处理工作
当类别较多时,错误可能增加的比较快
python实现决策树模型的构建
重点代码:
dtmodel = DecisionTreeClassifier(max_leaf_nodes=None) #最大叶子节点数
dtModel.fit(featureData, targetData) #特征数据、目标数据
#对离散型变量进行虚拟化
#设置特征变量、目标变量
#构建决策树模型
from sklearn.tree import DecisionTreeClassifier dtmodel = DecisionTreeClassifier(max_leaf_nodes=8) #最大叶数为8
#模型验证
from sklearn.model_selection import cross_val_score
cross_val_score(dtmodel,fdata,tdata,cv=10) #交叉验证10次
#模型训练
dtmodel.fit(fdata,tdata)
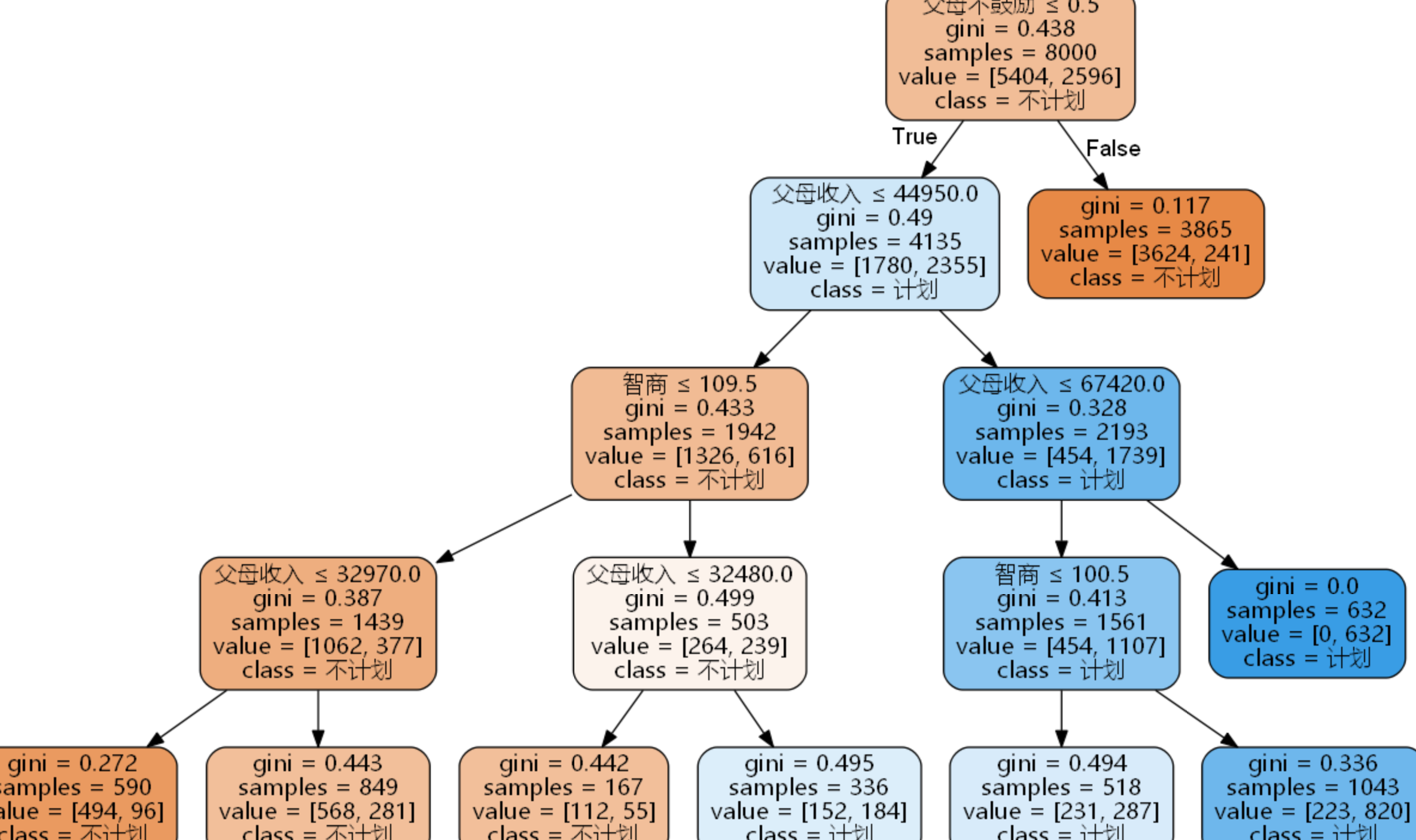
#绘制决策树模型 (需要下载安装graphviz软件 并 安装pydot包,可参考http://wenda.chinahadoop.cn/question/5518)
#绘制决策树图形 from sklearn.tree import export_graphviz with open(r'D:...data.dot','w') as f: f = export_graphviz(dtmodel, out_file=f) import pydot from sklearn.externals.six import StringIO dot_data = StringIO() export_graphviz( dtmodel, #模型名称 out_file=dot_data, #图形数据的输出路径 class_names=['A','B'], #目标属性的名称 feature_names=['a','b','c','d'], #特征属性的名称 filled=True, #是否使用颜色填充 rounded=True, #边框是否圆角 special_characters=True) #是否有特殊字符(含中文就算) graph = pydot.graph_from_dot_data(dot_data.getvalue()) graph.get_node('node')[0].set_fontname('Microsoft YaHei') graph.write_png(r'D:...决策树.png')
#最终在目标路径下得到决策树的图形