https://www.zhihu.com/question/57770020
机器学习:一种实现人工智能的方法
机器学习最基本的做法,是使用算法来解析数据、从中学习,然后对真实世界中的事件做出决策和预测。与传统的为解决特定任务、硬编码的软件程序不同,机器学习是用大量的数据来“训练”,通过各种算法从数据中学习如何完成任务。
举个简单的例子,当我们浏览网上商城时,经常会出现商品推荐的信息。这是商城根据你往期的购物记录和冗长的收藏清单,识别出这其中哪些是你真正感兴趣,并且愿意购买的产品。这样的决策模型,可以帮助商城为客户提供建议并鼓励产品消费。
机器学习直接来源于早期的人工智能领域,传统的算法包括决策树、聚类、贝叶斯分类、支持向量机、EM、Adaboost等等。从学习方法上来分,机器学习算法可以分为监督学习(如分类问题)、无监督学习(如聚类问题)、半监督学习、集成学习、深度学习和强化学习。
传统的机器学习算法在指纹识别、基于Haar的人脸检测、基于HoG特征的物体检测等领域的应用基本达到了商业化的要求或者特定场景的商业化水平,但每前进一步都异常艰难,直到深度学习算法的出现。
深度学习:一种实现机器学习的技术
深度学习本来并不是一种独立的学习方法,其本身也会用到有监督和无监督的学习方法来训练深度神经网络。但由于近几年该领域发展迅猛,一些特有的学习手段相继被提出(如残差网络),因此越来越多的人将其单独看作一种学习的方法。
最初的深度学习是利用深度神经网络来解决特征表达的一种学习过程。深度神经网络本身并不是一个全新的概念,可大致理解为包含多个隐含层的神经网络结构。为了提高深层神经网络的训练效果,人们对神经元的连接方法和激活函数等方面做出相应的调整。其实有不少想法早年间也曾有过,但由于当时训练数据量不足、计算能力落后,因此最终的效果不尽如人意。
深度学习摧枯拉朽般地实现了各种任务,使得似乎所有的机器辅助功能都变为可能。无人驾驶汽车,预防性医疗保健,甚至是更好的电影推荐,都近在眼前,或者即将实现。
https://blog.csdn.net/wangyoujin321/article/details/90691112

三、对比机器学习和深度学习
上面我们大概了解了机器学习和深度学习的工作原理,下面我们从几个重要的方面来对比两种技术。
1.数据依赖
随着数据量的增加,二者的表现有很大区别:
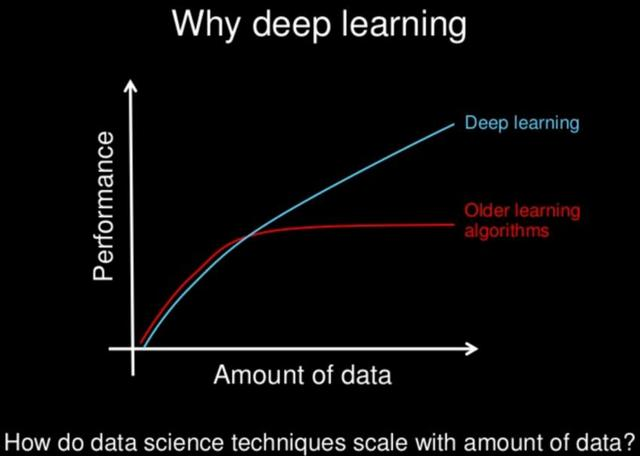
数据量对不同方法表现的影响
可以发现,深度学习适合处理大数据,而数据量比较小的时候,用传统机器学习方法也许更合适。
2.硬件依赖
深度学习十分地依赖于高端的硬件设施,因为计算量实在太大了!深度学习中涉及很多的矩阵运算,因此很多深度学习都要求有GPU参与运算,因为GPU就是专门为矩阵运算而设计的。相反,普通的机器学习随便给一台破电脑就可以跑。
3.特征工程
特征工程就是前面的案例里面讲过的,我们在训练一个模型的时候,需要首先确定有哪些特征。
在机器学习方法中,几乎所有的特征都需要通过行业专家在确定,然后手工就特征进行编码。
然而深度学习算法试图自己从数据中学习特征。这也是深度学习十分引人注目的一点,毕竟特征工程是一项十分繁琐、耗费很多人力物力的工作,深度学习的出现大大减少了发现特征的成本。
4.解决问题的方式
在解决问题时,传统机器学习算法通常先把问题分成几块,一个个地解决好之后,再重新组合起来。但是深度学习则是一次性地、端到端地解决。如下面这个物体识别的例子:

物体识别
如果任务是要识别出图片上有哪些物体,找出它们的位置。那么传统机器学习的做法是把问题分为两步:发现物体 和 识别物体。首先,我们有几个物体边缘的盒型检测算法,把所有可能的物体都框出来。然后,再使用物体识别算法,例如SVM在识别这些物体中分别是什么。
但是深度学习不同,给它一张图,它直接给出把对应的物体识别出来,同时还能标明对应物体的名字。这样就可以做到实时的物体识别。例如YOLO net就可以在视频中实时识别:

实时检测
5.运行时间
深度学习需要花大量的时间来训练,因为有太多的参数需要去学习。顶级的深度学习算法ResNet需要花两周的时间训练。但是机器学习一般几秒钟最多几小时就可以训练好。
但是深度学习花费这么大力气训练处模型肯定不会白费力气的,优势就在于它模型一旦训练好,在预测任务上面就运行很快。这才能做到我们上面看到的视频中实时物体检测。
6.可理解性
最后一点,也是深度学习一个缺点。其实也说不上是缺点吧,那就是深度学习很多时候我们难以理解。一个深层的神经网络,每一层都代表一个特征,而层数多了,我们也许根本就不知道他们代表的啥特征,我们就没法把训练出来的模型用于对预测任务进行解释。例如,我们用深度学习方法来批改论文,也许我们训练出来的模型对论文评分都十分的准确,但是我们无法理解模型到底是啥规则,这样的话,那些拿了低分的同学找你质问“凭啥我的分这么低啊?!”,你也哑口无言····因为深度学习模型太复杂,内部的规则很难理解。
但是机器学习不一样,比如决策树算法,就可以明确地把规则给你列出来,每一个规则,每一个特征,你都可以理解。
但是这不是深度学习的错,只能说它太牛逼了,人类还不够聪明,理解不了深度学习的内部的特征。
P:或许可以首先从解决脑电问题出发——需要可解释的特征,另外特征量不需要太大,所以使用的机器学习
另:确认FS是为了提高acc还是更快的去除冗余特征
前俩个问题结合:是否可以从加入范数后使得,原本应该通过学习acc逐渐增加的网络,在特征量很少的时候就有很高的acc