一、前言
执行命令行操作es的方式有几种,比如使用postman,或者我们前面安装的kibana客户端,或者JavaApi等等,这篇文章重点介绍用kibana来操作我们的索引库。
DSL语句:领域专用语言,由叶子查询子句和复合查询子句两种子句组成。
Elasticsearch提供了基于JSON的DSL来定义查询。
二、索引部分
索引创建
#1、创建索引库,同时设置分词器【有梦想的肥宅】 PUT /zh_user { "settings": { "index": { "analysis.analyzer.default.type": "ik_max_word" } } }
PS:PUT请求具有幂等性,如果重复执行同样的语句创建索引库会报错
索引查询
查看所有索引
#2、查询所有索引【有梦想的肥宅】
GET /_cat/indices?v
查看单个索引
#3、查询单个索引【有梦想的肥宅】
GET /zh_user
索引删除
#4、删除索引库【有梦想的肥宅】
DELETE /zh_user
三、文档部分
创建文档
#5、创建文档【格式:POST /索引名称/类型(7.6.1版本默认是_doc)/id】 POST /zh_user/_doc/1/ { "name": "有梦想的肥宅", "sex": "男", "age": 27, "address": "广西南宁", "remark": "有趣又上进的灵魂~" }
PS:创建文档要用POST,如果没有指定id的话,es会自动生成,指定了就用我们指定的id
查询文档
主键查询
#6、根据主键查询文档(数据)【有梦想的肥宅】
GET /zh_user/_doc/1
全查询
#7、全量查询索引下文档(数据)【有梦想的肥宅】
GET /zh_user/_search
修改文档
全量修改
#8、全量修改文档【格式:PUT /索引名称/类型(7.6.1版本默认是_doc)/id】
PUT /zh_user/_doc/1/
{
"name": "有梦想的肥宅【更新】",
"sex": "男",
"age": 27,
"address": "广西南宁",
"remark": "有趣又上进的灵魂~"
}
局部修改
#9、局部修改文档【格式:PUT /索引名称/类型(7.6.1版本默认是_doc)/id】
POST /zh_user/_update/1/
{
"doc":{
"name": "有梦想的肥宅【更新】",
"sex": "男【更新】",
"address": "广西南宁【更新】"
}
}
删除
#10、删除索引库内的文档(数据)【有梦想的肥宅】
DELETE /zh_user/_doc/1
四、查询操作部分
条件查询
#11、条件查询【有梦想的肥宅】
GET /zh_user/_search
{
"query":{
"match":{
"sex":"男"
}
}
}
分页查询
#12、分页查询【有梦想的肥宅】
GET /zh_user/_search
{
"query":{
"match":{
"sex":"男"
}
},
"from":0,
"size":2
}
排序查询
#13、排序查询【有梦想的肥宅】
GET /zh_user/_search
{
"query":{
"match_all":{} #表示查询全部数据
},
"sort":{
"age":{
"order":"desc"
}
}
}
多条件查询
#14、多条件查询【有梦想的肥宅】
GET /zh_user/_search
{
"query":{
"bool":{ #表示需要进行条件过滤
"must":[{ #表示必须满足下面的条件,并且参与计算分值,常用的子句还有should,表示“或”的意思
"match":{
"address":"广西南宁"
}
},{
"match":{
"sex":"男"
}
}]
}
}
}
范围查询
#15、范围查询【有梦想的肥宅】
GET /zh_user/_search
{
"query": {
"bool": { #表示需要进行条件过滤
"filter": [{ #返回的文档必须满足filter子句的条件。但是跟Must不一样的是,不会计算分值,并且可以使用缓存。【不算分的场景使用这个效率会提升】
"range": {
"age": {
"gt": 1 #表示查询年龄大于1岁的小伙伴~
}
}
}]
}
}
}
查询分词结果
#16、查询分词结果【有梦想的肥宅】
GET /zh_user/_doc/1/_termvectors?fields=address
PS:这条语句的意思是,查询索引库zh_user下id为1的,字段为address的数据分词的结果
也可以直接对一段文字进行分词结果查询:
POST _analyze
{
"text": ["广西南宁青秀区"],
"analyzer": "ik_max_word" #分词器:standard【中文单字分词】、ik_smart【最粗粒度拆分】、ik_max_word【最细粒度的拆分】
}
完全匹配
为了更好理解完全匹配的概念,我们先看一个例子:
PS:match:分词后搜索。比如分词后有N个分词,只要匹配上其中一个就可以返回数据了。
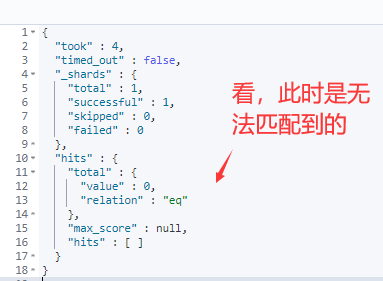
GET /zh_user/_search { "query":{ "match":{ "name" : "梦想哈" } } }

#17、完全匹配查询【有梦想的肥宅】
PS:match_phrase:分词后搜索。与match不同的是,match_phase分出来的词必须全部在搜索结果中,且位置顺序是一样的。
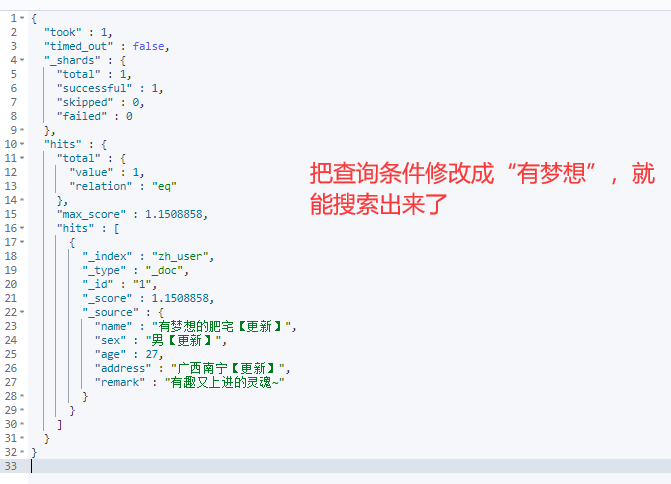
PS:这里说的完全匹配不是说必须输入“有梦想的肥宅【更新】”才能精确匹配出来,而是分词后顺序一致就可以查询出来
GET /zh_user/_search
{
"query":{
"match_phrase":{
"name" : "梦想哈"
}
}
}
高亮查询
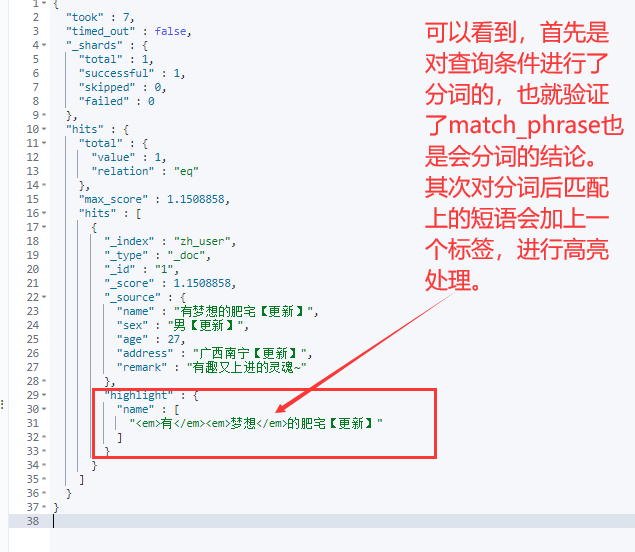
#18、高亮查询【有梦想的肥宅】
GET /zh_user/_search
{
"query": {
"match_phrase": {
"name": "有梦想"
}
},
"highlight": {
"fields": {
"name": {} #表示对当前字段进行高亮处理
}
}
}
聚合/分组查询
#19、聚合查询【有梦想的肥宅】
GET /zh_user/_search
{
"aggs":{ #表示聚合操作
"age_group":{ #分组名称,可以随便起
"terms":{ #表示分组操作,也可以使用avg来求平均值
"field":"age" #表示对哪一个字段进行分组
}
}
},
"size":0 #表示不查询原始数据,只查询分组结果
}
PS:ES进行聚合查询时,对应字段的类型只能是整形等,如果是“text”等类型是无法进行聚合分组查询的。

五、映射关系部分
映射关系可以理解成数据库中的表结构,那么我们来看一下怎么玩这个内容:
#20、创建索引库,并设置映射【有梦想的肥宅】
PUT /zh_user_new #创建索引库
PUT /zh_user_new/_mapping
{
"properties": {
"name":{
"type": "keyword", #关键字类型,不做分词操作
"index": true #表示此字段可以被用来查询
},
"sex":{
"type": "text", #text类型,可以分词
"index": true
},
"age":{
"type": "long", #long类型,表示数值
"index": true
},
"address":{
"type": "text",
"index": true
},
"reamrk":{
"type": "text",
"index": false #表示此字段不可以被用来查询
}
}
}