在此引出另一种模型:Locally weighted regression algorithm(LWLR/LWR),通过名字我们可以推断,这是一种更加关注局部变化的模型。的确如此,在普通的linear regression algorithm中,cost function是完全基于training set的,我们通过算法与training set求出h(x)的参数theta,然后训练结束,此后无论推测多少输出,theta和cost function的形式不再发生任何变化。cost function如下: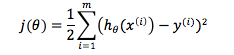
而LWR的完全不同之处在于,我们的cost function是由training set和要预测的数据共同决定的。我们从linear regression的cost function中看到,每个training example的权重都是相等的,而在LWR algorithm中,则是利用的权重项来给予预测值周边局部内的training sub-set更高关注,而基本忽略其他域内training examples的。其cost function为如下形式:
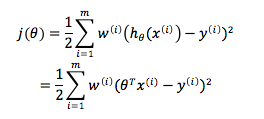
其中权重项的值为: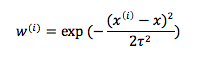
如果仔细观察,我们可以分析出这个函数是如何为局部范围内的训练样例加权而为局部范围外的训练样例除权的了:
a.x是要进行预测的数据,当训练样例与x无限接近,我们可以知道,此时的权重项无限接近于1,需要经过训练theta去拟合我们的数据集
b.当训练样例与x逐渐远离直至无穷远,此时的权重将无限接近于0,几乎可以无需或需要很小的权重去拟合数据集
c.w的表达式看起来很像Gaussian Distribution,虽然它和高斯分布没什么关系,但的的确确也是一个Bell-Shaped Curve,而分母处tow称为bandwidth parameter,其作用类似于高斯分布中均方差的作用,用以控制钟形曲线的宽窄陡峭程度,如果tow很大,则表明离散程度大,曲线平缓,如果tow小,说明分布比较集中,曲线比较陡峭。
从某种意义上讲,LWR基本忽略了远离局部域的训练样例,专注于在预测值周边的training sub-set中建立线性回归模型,并做局部拟合。普通的linear regression模型是一种parametric learning algorithm,也就是说,学习过程有明确的参数,一旦确定就不会改变,一旦学习就可以丢弃。但locally weighted linear regression是non-parametric learning algorithm,每次进行预估时,都需要进行重新学习。