本文大纲
- 进程
- 进程池
- 进程间通信
- 回调函数
- 进程锁
进程
之前一篇文章介绍了多线程编程,我们知道python的多线程适合IO密集型编程,对于计算密集型不太适合因为无法做到真正的并发,所以如果在一个计算密集型场景下还是使用多进程会更好。首先我们先看看如何使用一个进程。
(例子1)
#!/usr/bin/env python # -*- coding: utf-8 -*- import time import multiprocessing from atexit import register def task(name): print("我是子进程名称:" + p.name + " PID: " + str(p.pid)) time.sleep(1) # 加这个装饰器是为了在主程序退出 main 函数之前调用 @register def _atexit(): print("主程序代码与子进程均执行完毕,主程序即将退出。") if __name__ == '__main__': for i in range(5): # 进程开启必须放在main()下, name 是这个子进程的名称,可以不写。 p = multiprocessing.Process(target=task, args=(i,)) # 是否设置子进程为守护进程,默认是False,用法与含义同线程 # p.daemon = True p.start() # join 主线程阻塞等待子进程执行完毕后再继续执行,如果使用这个就不是并发的,可以设置一个超时 # 时间,超过这个时间子进程没有完成,该函数也会返回继续执行主线程,如果进程不会争抢资源 # 可以不设置阻塞。 # p.join(1) # print "CPU数量:" + str(multiprocessing.cpu_count()) print('主程序代码执行完毕。')
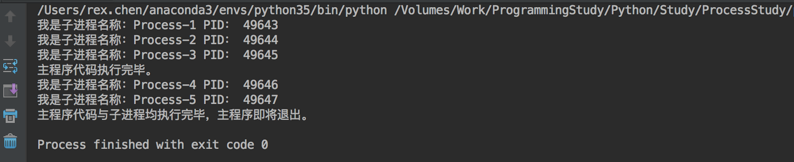
其实单一的这样使用一个子进程没有多大意义,这里也只做说明,它的用法其实和使用线程是类似的。下面我们看看进程池。
进程池
进程池就是每次每次允许并发的进程不能超过池子的大小,其实这也是为了控制进程数量。如果需要的进程数量大于池数量,那么也只能按照池子数量来创建进程,当池子中的进程执行完毕空闲一个位置之后,再向池子放一个进程进来。进程池大小不要超过CPU核心数量,不是说不能这样做,而是不规范,操作系统本身也需要CPU核心,所以要留一个给OS使用。尤其是当进程多计算任务量大,如果你不给OS留一个核心,系统本身也就慢了。
(例子2)
#!/usr/bin/env python # -*- coding: utf-8 -*- import time from multiprocessing import Pool from multiprocessing import cpu_count import os def task(name): time.sleep(3) print("子进程名称:" + name, "子进程ID:", os.getpid(), "父进程ID:", os.getppid()) if __name__ == '__main__': # 获取CPU数量 poolZize = cpu_count() - 1 # 建立进程池,并设置大小,默认是你主机的CPU核心数量,这个大小可以随意,但是不要超过CPU核心数量 p = Pool(poolZize) print("主进程ID:", os.getpid()) for i in range(5): # 非阻塞进程 p.apply_async(task, args=(str(i),)) # 调用close之后就不能再往池里添加进程了,如果使用死循环这里就不能调用这个方法,因为调用后第二次循环就无法向池子里添加进程了。 p.close() # 对 pool 调用join必须先调用 close(),这里的join的意思是等待所有子进程执行完毕,然后再执行主线程下面的代码,直到退出程序 p.join() time.sleep(1) print("主线程代码执行完毕。")

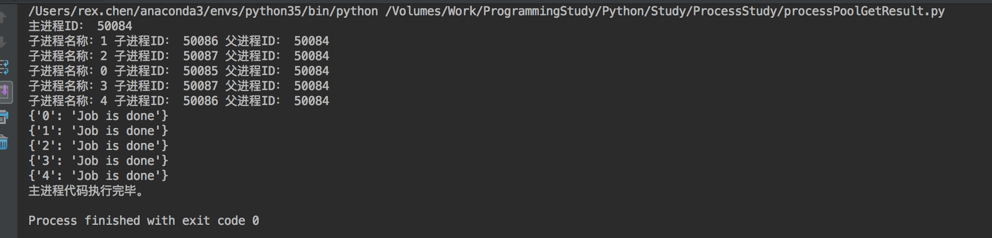
如果我们要关注每个进程执行结果怎么办?代码稍加改变。
(例子3)
#!/usr/bin/env python # -*- coding: utf-8 -*- import time from multiprocessing import Pool from multiprocessing import cpu_count import os def task(name): time.sleep(3) print("子进程名称:" + name, "子进程ID:", os.getpid(), "父进程ID:", os.getppid()) # 添加一个返回值表示每个子进程任务的执行结果 return {name: 'Job is done'} if __name__ == '__main__': processlist = [] # 获取CPU数量 poolZize = cpu_count() - 1 # 建立进程池,并设置大小,默认是你主机的CPU核心数量,这个大小可以随意,但是不要超过CPU核心数量 p = Pool(poolZize) print("主进程ID:", os.getpid()) for i in range(5): # 把进程添加到列表中 processlist.append(p.apply_async(task, args=(str(i),))) # 调用close之后就不能再往池里添加进程了,如果使用死循环这里就不能调用这个方法,因为调用后第二次循环就无法向池子里添加进程了。 p.close() # 对 pool 调用join必须先调用 close(),这里的join的意思是等待所有子进程执行完毕,然后再执行主线程下面的代码,直到退出程序 p.join() time.sleep(1) # 用于获取执行结果 for i in processlist: print(i.get()) print("主线程代码执行完毕。")
进程间通信
进程间通讯英文简写是IPC,它其实有多种方式,比如古老的管道、队列、信号量、共享内存。我们下面使用的你可以理解为队列。
进程间通信的实现和之前线程的通信类似都是使用一个队列,只是这里不是原来的队列,而是Manager里面的。
我这里的例子比较简单就是每个进程把自己获得的数添加到队列里面,然后在主程序中读取。
Queue
(例子4)
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 4 """ 5 进程之间进行通信,不同进程可以同时访问一个对象 6 """ 7 8 import sys, time 9 from multiprocessing import Queue, Process 10 11 12 def fun1(q, i): 13 q.put(i) 14 15 16 # 通过Queue()来实现进程间通信 17 def method1(): 18 queue = Queue() 19 pList = [] 20 for i in range(10): 21 p = Process(target=fun1, args=(queue, i,)) 22 pList.append(p) 23 p.start() 24 25 for p in pList: 26 p.join() 27 28 while not queue.empty(): 29 print(queue.get()) 30 31 32 def main(): 33 try: 34 method1() 35 except Exception as err: 36 print(err) 37 38 39 if __name__ == "__main__": 40 try: 41 main() 42 finally: 43 sys.exit()

说明:进程间通信使用的这个Queue()队列并不是共享的,而是把队列实例序列化后传给其他进程,其他进程反序列化后再使用。而线程中使用的队列是共享的,因为线程本身就是共享内存的。那么如何共享呢?就要用到下面这个。
Manager
Manager支持很多类型,字典、列表、队列、锁等。而且它本身就对数据进行加锁,你不用手动加锁。进程的通信的共享数据可以用Manager所支持的任何类型,比如我们使用列表,如下:
(例子5)
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 4 """ 5 进程之间进行通信,不同进程可以同时访问一个对象 6 """ 7 8 import sys, time 9 from multiprocessing import Manager, Process 10 11 12 def fun1(list1, i): 13 list1.append(i) 14 15 16 # Manager().Queue() 可共享的队列 17 # Manager().dict() 可共享的字典 18 # Manager().list() 可共享的列表 19 # Manager().Lock() 可共享的锁 20 21 def method1(): 22 # 定义可共享的列表 23 mList = Manager().list() 24 pList = [] 25 for i in range(5): 26 p = Process(target=fun1, args=(mList, i,)) 27 pList.append(p) 28 p.start() 29 30 for p in pList: 31 p.join() 32 33 print(mList) 34 35 36 def main(): 37 try: 38 method1() 39 except Exception as err: 40 print(err) 41 42 43 if __name__ == "__main__": 44 try: 45 main() 46 finally: 47 sys.exit()

其实原则上进程无法共享数据Manager其实也不是,什么是共享?数据只有一份,大家都能读取。进程的数据传递实际上是序列化之后发送给对方,这样同一个数据就有2份,A进程发给B,B修改完之后再发给A,A拿到后更新自己的,就这么回事。到底进程能不能共享数据,其实这就是进程间通信的几种方式,最接近共享的MMAP也就是内存映射,把A进程的内存地址影响到B进程中。
下面再给出一个进程池内进程共享数据的例子我这里的例子比较简单就是每个进程把自己获得的数添加到队列里面,然后在主线程中读取。
(例子6)
#!/usr/bin/env python # -*- coding: utf-8 -*- """ 进程之间进行通信,不同进程可以同时访问一个对象 Manager这里面支持很多类型,比如 字典、列表、Queue、锁等共享. """ import sys, time from multiprocessing import Manager, Pool def fun1(q, i): q.put(i) # 通过Manager().Queue()来实现进程共享的一个队列 def method1(): queue = Manager().Queue() pool = Pool(3) for i in range(10): pool.apply_async(fun1, args=(queue, i,)) pool.close() pool.join() while not queue.empty(): print(queue.get()) def main(): method1() # method2() if __name__ == "__main__": try: main() finally: sys.exit()

说明:from multiprocessing import Queue,这个Queue不能用在进程池里,在进程池中只能使用Manager()支持的类型。
回调函数
异步进程池可以设置一个回调函数,就是子进程执行完毕后回调该函数进行执行。需要注意的是这个回调函数是主进程调用的不是子进程调用的。
(例子7)
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 4 """ 5 进程之间进行通信,不同进程可以同时访问一个对象 6 Manager这里面支持很多类型,比如 字典、列表、Queue、锁等共享. 7 """ 8 9 import sys, time 10 from multiprocessing import Manager, Pool 11 12 import os 13 14 15 def fun1(i): 16 print(os.getpid()) 17 18 19 def cbFun(arg): 20 print(" ---> I am done.", arg) 21 22 23 def method1(): 24 pool = Pool(3) 25 for i in range(3): 26 # 进程执行完fun1后,执行callback设定的函数 27 pool.apply_async(fun1, args=(i,), callback=cbFun("A")) 28 pool.close() 29 pool.join() 30 31 32 def main(): 33 method1() 34 35 36 if __name__ == "__main__": 37 try: 38 main() 39 finally: 40 sys.exit()

回调干嘛用呢?回调能干的事情直接写在子进程代码里不也行嘛。我相信很多人都有这样的疑问,的确是这样,从功能角度讲没问题可以这样做,但是从性能用回调可能会更好,比如每个进程去做某些事情,完成之后需要向数据库插入一条记录表示该进程完成了这个工作。这时候向数据库写数据这个功能你可以放在子进程里也可以放在回调里,但如果放在子进程里那就是N个数据库连接,放在回调里则可以是1个数据库连接,你可以把这个功能做成一个类,初始化的时候就建立好连接,写数据的时候调用该实例的方法就可以。这样1个连接的开销肯定比N个连接要小。
还有就是回调函数其实是把函数当做参数由主进程去执行,如果你在子进程中执行回调函数的功能相当于硬编码画蛇添足,因为子进程本身有特定的任务,上面提到写入数据库,如果需求变了要求写入文件或者做其他的事情,那么你的子进程代码就要修改,通过回调函数就可以解耦,回调函数的函数名称不变至于里面干什么无所谓。还有一种情况就是你写一个功能让别人使用至于只能功能完成之后的是否做其他事情以及怎么做不是你能控制的,就是AJAX中的常常用到回调函数也就是执行完AJAX调用之后还要做什么由使用人来控制。在你编写程序的时候函数或者模块功能要单一化,所有的代码都是围绕这个功能写的。迅雷大家都用过,下载完成后会有提示音或者可以设置下载后关机这些动作,假设你设置了下载完成后关机,难道你要把关机功能写到下载功能里面去吗,显然不能。可是关机模块怎么知道下载完了呢?这时候就用到回调函数,下载完成后回调关机功能。
进程锁
进程本来就是独立的互不影响,那还要锁干嘛?锁的目的就是为了避免资源争抢,虽然数据是每个进程独立的,但是还有其他资源,比如显示器。需要注意在进程池的进程中不能用锁。
(例子8)
#!/usr/bin/env python # -*- coding: utf-8 -*- """ 进程之间进行通信,不同进程可以同时访问一个对象 """ import sys, time from multiprocessing import Manager, Process, Lock def fun1(lock, i): print("Hello world ", i) def method1(): pList = [] # lock = Lock() for i in range(50): p = Process(target=fun1, args=(lock, i,)) pList.append(p) p.start() for p in pList: p.join() def main(): try: method1() except Exception as err: print(err) if __name__ == "__main__": try: main() finally: sys.exit()

输出就会发生混乱,某个进程还没有打印完毕另外一个进程也来打印。我们加锁来看,使用方式和线程一样。
#!/usr/bin/env python # -*- coding: utf-8 -*- """ 进程之间进行通信,不同进程可以同时访问一个对象 """ import sys, time from multiprocessing import Manager, Process, Lock def fun1(lock, i): lock.acquire() print("Hello world ", i) lock.release() def method1(): pList = [] lock = Lock() for i in range(50): p = Process(target=fun1, args=(lock, i,)) pList.append(p) p.start() for p in pList: p.join() def main(): try: method1() except Exception as err: print(err) if __name__ == "__main__": try: main() finally: sys.exit()
这样在运行就不会出现错乱的问题。
进程池中的其他说明
进程池中的进程同步类的东西要使用Manager里面的,比如dic、lock等。如下图:

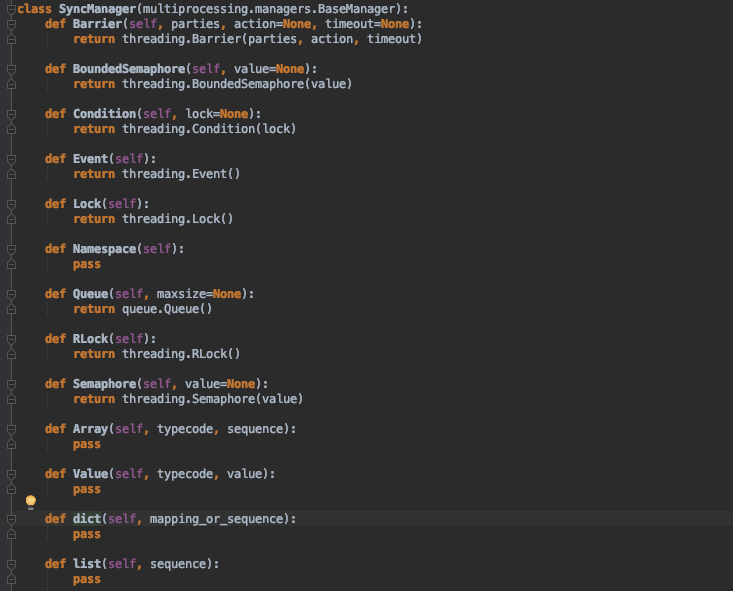
也就是说在进程池中的东西都是独有的,不过用法和线程的都一样。不过要注意使用Manager里面的数据比如dict、list、queue这些虽然可以共享数据但是要注意数据同步,你可能需要加锁。