可以先较为完整的了解下递归特性;
递归思想来由:
递归思想的数学模型其实就是归纳法;而归纳法适用于想解决一个问题转化为解决他的子问题,而他的子问题又变成子问题的子问题,而且我们发现这些问题其实都是一个模型,也就是说存在相同的逻辑归纳处理项;
当然有一个是例外的,也就是递归结束的哪一个处理方法不适用于我们的归纳处理项,当然也不能适用,否则我们就无穷递归了。这里又引出了一个归纳终结点以及直接求解的表达式。
如果运用列表来形容归纳法就是:
步进表达式:问题蜕变成子问题的表达式
结束条件:什么时候可以不再是用步进表达式
直接求解表达式:在结束条件下能够直接计算返回值的表达式
逻辑归纳项:适用于一切非适用于结束条件的子问题的处理,当然上面的步进表达式其实就是包含在这里面了。
什么时候可以使用递归?
遇到一个问题,如何判断是否能用递归来解决; 很明显的,用递归来解决的问题必须满足两个条件:
- 可以通过递归调用来缩小问题规模,且新问题与原问题有着相同的形式。
- 存在一种简单情境,可以使递归在简单情境下退出。
为了方便理解,还是拿斐波那契数列来说下:求斐波那契数列的第N项的值。
这是一个经典的问题,说到递归一定要提到这个问题。斐波那契数列这样定义:f(0) = 0, f(1) = 1, 对n > 1, f(n) = f(n-1) + f(n-2)
这是一个明显的可以用递归解决的问题。让我们来看看它是如何满足递归的两个条件的:
- 对于一个n>2, 求f(n)只需求出f(n-1)和f(n-2),也就是说规模为n的问题,转化成了规模更小的问题;
- 对于n=0和n=1,存在着简单情境:f(0) = 0, f(1) = 1。
int fib(n){ if(n == 0) return 0; else if(n == 1) return 1; else return f(n-1) + f(n-2); }
递归的使用模型:
根据归纳法的总结,递归的模型可以用以下结构来解释:
void func( mode) { if(endCondition) { constExpression //基本项 } else { accumrateExpreesion //归纳项 mode=expression //步进表达式 func(mode) //调用本身,递归 } }
二叉树的递归特性:
由于二叉树的左右结点的特性,对于二叉树的递归求解通常可以归纳为以下步骤:
S1: 对根结点求解;
S2: 递归求解左子树;
S3: 递归求解右子树;
S4 : 合并根结点、左子树、右子树的解,进而得到原问题的解;
例子一:
二叉树的遍历 --- 前序、中序、后序
//前序
void pre_traverse(BTree pTree)
{
if(pTree)
{
printf("%c ",pTree->data);
if(pTree->pLchild)
pre_traverse(pTree->pLchild);
if(pTree->pRchild)
pre_traverse(pTree->pRchild);
}
}
//中序
void in_traverse(BTree pTree)
{
if(pTree)
{
if(pTree->pLchild)
in_traverse(pTree->pLchild);
printf("%c ",pTree->data);
if(pTree->pRchild)
in_traverse(pTree->pRchild);
}
}
//后序 void beh_traverse(BTree pTree) {
if(pTree) {
if(pTree->pLchild);
beh_traverse(pTree->pLchild);
if(pTree->pRchild) beh_traverse(pTree->pRchild);
printf("%c ",pTree->data);
} }
例子二:二叉树的最大深度
归纳法:对于任意一个节点,depth = Max(left.depth, right.depth)+ 1;
根据这个结论:
class Solution { public int maxDepth(TreeNode root) { if (root == null) { return 0; } else { int left_height = maxDepth(root.left); int right_height = maxDepth(root.right); return java.lang.Math.max(left_height, right_height) + 1; } } }
递归的效率及开销:
递归由于其反复的函数的调用,开销是很大的,系统要为每次函数调用分配存储空间,并将调用点压栈予以记录。而在函数调用结束后,还要释放空间,弹栈恢复断点。所以说,函数调用不仅浪费空间,还浪费时间;
普通的线性递归,以斐波那契数列为例,调用过程为:
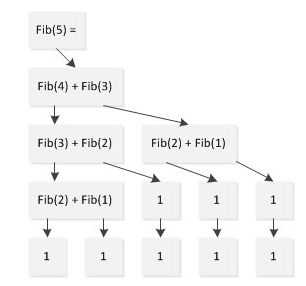
可以看到Fib(1)、Fib(2)、Fib(3)都被计算了多次,而如果可以采用一种将这次的计算结果传递到下次计算,实现一种迭代计算的方法,可以消除冗余计算,提高效率;这就是所谓的“尾递归”。
所以,凡是可以通过固定数量状态来描述中间计算过程的递归过程都可以通过线性迭代来表示。
def Fib(n,b1=1,b2=1,c=3): if n <= 2: return 1 else: if n==c: return b1+b2 else: return Fib(n,b1=b2,b2=b1+b2,c=c+1)
迭代过程:
fib(6) fib 0,0,1 fib 0,1,2 fib 1,2,3 fib 2,3,4 fib 3,5,5 fib 5,8,6
尾递归其实是一种可以转换成一种迭代:
function fib(n){ var a=0, b=1; for(var i=0;i<=n;i++){ var temp = a+b; a = b; b = temp; } return b; }
同样的,阶层的实现可以这么理解:
// 迭代计算过程
function factorial(n){
return factIterator(1, 1, n);
}
function factIterator(result, counter, maxCount){
if(counter > maxCount){
return result;
}
return factIterator((counter * result), counter + 1, maxCount);
}
(factorial (6)) (factIterator(1, 1, 6)) (factIterator(1, 2, 6)) (factIterator(2, 3, 6)) (factIterator(6, 4, 6)) (factIterator(24, 5, 6)) (factIterator(120, 6, 6)) (factIterator(720, 7, 6))
有时候需要减少递归的使用是因为在一定的计算规模下会导致大量的开销, 可是递归的实现思维是比较直观简单的,基本等同于数学公式,所以在考虑是否使用递归or迭代的时候,需要放到具体计算场景下;
没有绝对冗余的递归,也没有绝对高效的迭代;
内容摘自:
1:http://www.nowamagic.net/librarys/veda/detail/2314
2:https://blog.csdn.net/ns_code/article/details/12977901
等