一、Base64概念
什么是Base64?
按照RFC2045的定义,Base64被定义为:Base64内容传送编码被设计用来把任意序列的8位字节描述为一种不易被人直接识别的形式。(The Base64 Content-Transfer-Encoding is designed to represent arbitrary sequences of octets in a form that need not be humanly readable.)
百度百科中对Base64有一个很好的解释:“Base64是网络上最常见的用于传输8Bit字节码的编码方式之一,Base64就是一种基于64个可打印字符来表示二进制数据的方法”。
什么是“可打印字符”呢?为什么要用它来传输8Bit字节码呢?在回答这两个问题之前我们有必要来思考一下什么情况下需要使用到Base64?Base64一般用于在HTTP协议下传输二进制数据,由于HTTP协议是文本协议,所以在HTTP协议下传输二进制数据需要将二进制数据转换为字符数据。然而直接转换是不行的。因为网络传输只能传输可打印字符。什么是可打印字符?在ASCII码中规定,0~31、128这33个字符属于控制字符,32~127这95个字符属于可打印字符,也就是说网络传输只能传输这95个字符,不在这个范围内的字符无法传输。那么该怎么才能传输其他字符呢?其中一种方式就是使用Base64。
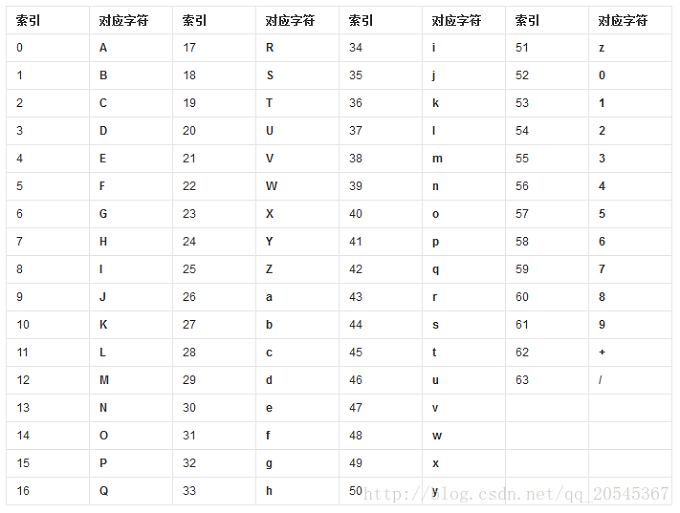
Base64,就是使用64个可打印字符来表示二进制数据的方法。Base64的索引与对应字符的关系如下表所示:
也就是说,如果将索引转换为对应的二进制数据的话需要至多6个Bit。然而ASCII码需要8个Bit来表示,那么怎么使用6个Bit来表示8个Bit的数据呢?6个Bit当然不能存储8个Bit的数据,但是4*6个Bit可以存储3*8个Bit的数据啊!如下表所示:

可以看到“Son”通过Base64编码转换成了“U29u”。这是刚刚好的情况,3个ASCII字符刚好转换成对应的4个Base64字符。但是,当需要转换的字符数不是3的倍数的情况下该怎么办呢?Base64规定,当需要转换的字符不是3的倍数时,一律采用补0的方式凑足3的倍数,具体如下表所示:
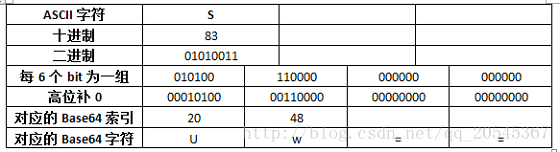
每6个Bit为一组,第一组转换后为字符“U”,第二组末尾补4个0转换后为字符“w”。剩下的使用“=”替代。即字符“S”通过Base64编码后为“Uw==”。这就是Base64的编码过程。
二、Base64作用
由于某些系统中只能使用ASCII字符。Base64就是用来将非ASCII字符的数据转换成ASCII字符的一种方法。
base64特别适合在http,mime协议下快速传输数据。
base64其实不是安全领域下的加密解密算法。虽然有时候经常看到所谓的base64加密解密。其实base64只能算是一个编码算法,对数据内容进行编码来适合传输。虽然base64编码过后原文也变成不能看到的字符格式,但是这种方式很初级,很简单。
三、Base64原理
Base64编码方法要求把每三个8Bit的字节转换为四个6Bit的字节,其中,转换之后的这四个字节中每6个有效bit为是有效数据,空余的那两个 bit用0补上成为一个字节。因此Base64所造成数据冗余不是很严重,Base64是当今比较流行的编码方法,因为它编起来速度快而且简单
举个例子,有三个字节的原始数据:aaaaaabb bbbbccccc ccdddddd(这里每个字母表示一个bit位)
那么编码之后会变成: 00aaaaaa 00bbbbbb 00cccccc 00dddddd
所以可以看出base64编码简单,虽然编码后不是明文,看不出原文,但是解码也很简单
四、为什么要使用Base64?
在设计这个编码的时候,我想设计人员最主要考虑了3个问题:
1.是否加密?
2.加密算法复杂程度和效率
3.如何处理传输?
加密是肯定的,但是加密的目的不是让用户发送非常安全的Email。这种加密方式主要就是“防君子不防小人”。即达到一眼望去完全看不出内容即可。
基于这个目的加密算法的复杂程度和效率也就不能太大和太低。和上一个理由类似,MIME协议等用于发送Email的协议解决的是如何收发Email,而并不是如何安全的收发Email。因此算法的复杂程度要小,效率要高,否则因为发送Email而大量占用资源,路就有点走歪了。
但是,如果是基于以上两点,那么我们使用最简单的恺撒法即可,为什么Base64看起来要比恺撒法复杂呢?这是因为在Email的传送过程中,由于历史原因,Email只被允许传送ASCII字符,即一个8位字节的低7位。因此,如果您发送了一封带有非ASCII字符(即字节的最高位是1)的Email通过有“历史问题”的网关时就可能会出现问题。网关可能会把最高位置为0!很明显,问题就这样产生了!因此,为了能够正常的传送Email,这个问题就必须考虑!所以,单单靠改变字母的位置的恺撒之类的方案也就不行了。关于这一点可以参考RFC2046。
基于以上的一些主要原因产生了Base64编码。
五、python中的base64
Base64是一种用64个字符来表示任意二进制数据的方法。
用记事本打开exe、jpg、pdf这些文件时,我们都会看到一大堆乱码,因为二进制文件包含很多无法显示和打印的字符,所以,如果要让记事本这样的文本处理软件能处理二进制数据,就需要一个二进制到字符串的转换方法。Base64是一种最常见的二进制编码方法。
Base64的原理很简单,首先,准备一个包含64个字符的数组:
['A', 'B', 'C', ... 'a', 'b', 'c', ... '0', '1', ... '+', '/']
然后,对二进制数据进行处理,每3个字节一组,一共是3x8=24bit,划为4组,每组正好6个bit:
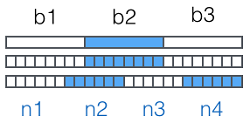
这样我们得到4个数字作为索引,然后查表,获得相应的4个字符,就是编码后的字符串。
所以,Base64编码会把3字节的二进制数据编码为4字节的文本数据,长度增加33%,好处是编码后的文本数据可以在邮件正文、网页等直接显示。
如果要编码的二进制数据不是3的倍数,最后会剩下1个或2个字节怎么办?Base64用x00字节在末尾补足后,再在编码的末尾加上1个或2个=号,表示补了多少字节,解码的时候,会自动去掉。
Python内置的base64可以直接进行base64的编解码:
>>> import base64 >>> base64.b64encode(b'binaryx00string') b'YmluYXJ5AHN0cmluZw==' >>> base64.b64decode(b'YmluYXJ5AHN0cmluZw==') b'binaryx00string'
由于标准的Base64编码后可能出现字符 + 和 /,在URL中就不能直接作为参数,所以又有一种"url safe"的base64编码,其实就是把字符 + 和 / 分别变成 - 和 _:
>>> base64.b64encode(b'ixb7x1dxfbxefxff') b'abcd++//' >>> base64.urlsafe_b64encode(b'ixb7x1dxfbxefxff') b'abcd--__' >>> base64.urlsafe_b64decode('abcd--__') b'ixb7x1dxfbxefxff'
还可以自己定义64个字符的排列顺序,这样就可以自定义Base64编码,不过,通常情况下完全没有必要。
Base64是一种通过查表的编码方法,不能用于加密,即使使用自定义的编码表也不行。
Base64适用于小段内容的编码,比如数字证书签名、Cookie的内容等。
由于 = 字符也可能出现在Base64编码中,但 = 用在URL、Cookie里面会造成歧义,所以,很多Base64编码后会把=去掉:
# 标准Base64: 'abcd' -> 'YWJjZA==' # 自动去掉=: 'abcd' -> 'YWJjZA'
去掉 = 后怎么解码呢?因为Base64是把3个字节变为4个字节,所以,Base64编码的长度永远是4的倍数,因此,需要加上=把Base64字符串的长度变为4的倍数,就可以正常解码了。
小结
Base64是一种任意二进制到文本字符串的编码方法,常用于在URL、Cookie、网页中传输少量二进制数据。