## # zookeeper的基本功能和应用场景
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
简单地说 zookeeper可以替用户管理 监听小体量的数据(当数据发生变化是,用户会得到通知),集中管理配置文件,以及容错、负载均衡机制。
## # zookeeper的整体运行机制
ZooKeeper集群安装在奇数台服务器上,集群最少台数应该为3台 最典型集群模式:Master/Slave 模式(主备模式)。在这种模式中,通常 Master 服务器作为主服务器提供写服务,其他的 Slave 服务器从服务器通过异步复制的方式获取 Master 服务器最新的数据提供读服务。但是,在 ZooKeeper 中没有选择传统的 Master/Slave 概念,而是引入了Leader、Follower 和 Observer 三种角色。在ZooKeeper集群启动时选举出Leader、Follower 和 Observer 三种角色
但是,在 ZooKeeper 中没有选择传统的 Master/Slave 概念,而是引入了Leader、Follower 和 Observer 三种角色
选举投票过程(以三台服务器为例):
- 第一台zk进程启动,会向局域网进行组播投票,投自己
- 第二台zk进程启动,会向局域网进行组播投票,投自己(id最大)
- 1和2两个zk进程各自得一票,那就继续投票
- 1在这一轮会投票给2,而2会投给自己 此时2得2票顺利当选为leader,1自动切换follower
- 第三台启动zk进程 上线发现已经有leader 自动切换到follower
## # zookeeper的数据存储机制
数据存储形式
zookeeper中对用户的数据采用kv形式存储 只是zk有点特别: key:是以路径的形式表示的,那就以为着,各key之间有父子关系,比如 / 是顶层key,用户建的key只能在/下作为子节点,比如建一个key: /aa,这个key可以带value数据. zookeeper中,对每一个数据key,称作一个znode 综上所述,zk中的数据存储形式如下:
znode类型
zookeeper中的znode有多种类型:
1.PERSISTENT 持久的:创建者就算跟集群断开联系,该类节点也会持久存在与zk集群中
2.EPHEMERAL 短暂的:创建者一旦跟集群断开联系,zk就会将这个节点删除
3.SEQUENTIAL 带序号的:这类节点,zk会自动拼接上一个序号,而且序号是递增的
组合类型: PERSISTENT :持久不带序号 EPHEMERAL :短暂不带序号 PERSISTENT 且 SEQUENTIAL :持久且带序号 EPHEMERAL 且 SEQUENTIAL :短暂且带序号
## # zookeeper的安装
安装zookeeper要求: 必须先安装jdk
上传zookeeper安装包,解压
[root@hdp-01 ~]# tar -zxvf zookeeper-3.4.6.tar.gz -C apps/
[root@hdp-01 ~]# cd apps/zookeeper-3.4.6/conf/
官方提供了一份模板配置文件zoo_sample.cfg 启动要求conf目录下加载zoo.cfg文件
[root@hdp-01 conf]# cp zoo_sample.cfg zoo.cfg
配置数据存放目录及集群ip和端口 默认临时目录/tmp下 修改为自己建立的数据目录
[root@hdp-01 conf]# vi zoo.cfg
dataDir=/root/zkdata clientPort=2181 server.1=hdp-01:2888:3888 server.2=hdp-02:2888:3888 server.3=hdp-03:2888:3888
配置文件修改完后,将安装包拷贝给hdp-02 和 hdp-03
scp -r zookeeper-3.4.6/ hdp-02:$PWD
scp -r zookeeper-3.4.6/ hdp-03:$PWD
hdp-01上,新建目录/root/zkdata,并在目录中生成一个文件myid,内容为1
[root@hdp-01 ~]# mkdir zkdata
[root@hdp-01 ~]# echo 1 > zkdata/myid
hdp-02上,新建目录/root/zkdata,并在目录中生成一个文件myid,内容为2
[root@hdp-02 ~]# mkdir zkdata
[root@hdp-02 ~]# echo 2 > zkdata/myid
hdp-03上,新建目录/root/zkdata,并在目录中生成一个文件myid,内容为3
[root@hdp-03 ~]# mkdir zkdata
[root@hdp-03 ~]# echo 3 > zkdata/myid
配置一键启动zookeeper集群:
[root@hdp-01 ~]# vi zkmanage.sh #!/bin/bash for host in hdp-01 hdp-02 hdp-03 do echo "${host}:${1}ing....." ssh $host "source /etc/profile;/root/apps/zookeeper-3.4.6/bin/zkServer.sh $1" done sleep 2 for host in hdp-01 hdp-02 hdp-03 do ssh $host "source /etc/profile;/root/apps/zookeeper-3.4.6/bin/zkServer.sh status" done
chmod: 无法访问: 没有那个文件或目录
[root@hdp-01 ~]# chmod 777 ./zkmanage.sh [root@hdp-01 ~]# ./zkmanage.sh start //一键启动zookeeper集群
启动ok
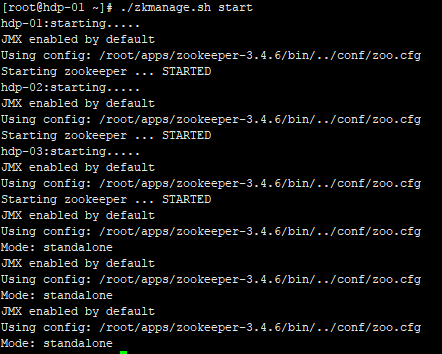
bin/zkServer.sh status 能看到角色模式:为leader或follower,即正常了。
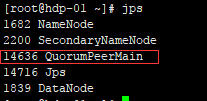
用jps应该能看到一个进程:QuorumPeerMain
## # zookeeper客户端
连接本机客户端
[root@hdp-01 zookeeper-3.4.6]# ./bin/zkCli.sh
连接集群其他节点客户端
[root@hdp-01 zookeeper-3.4.6]# ./bin/zkCli.sh -server hdp-02:2181
创建节点:
[zk: localhost:2181(CONNECTED) 0] create /aaa 'ppppp'
Created /aaa
查看节点下的子节点: ls /aaa
[zk: localhost:2181(CONNECTED) 7] ls /aaa
获取节点的value:
[zk: localhost:2181(CONNECTED) 5] get /aaa 'ppppp' cZxid = 0x2 ctime = Sat Aug 31 15:06:28 CST 2019 mZxid = 0x2 mtime = Sat Aug 31 15:06:28 CST 2019 pZxid = 0x2 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 7 numChildren = 0
修改节点的value:
[zk: localhost:2181(CONNECTED) 8] set /aaa 'mmmmm' cZxid = 0x2 ctime = Sat Aug 31 15:06:28 CST 2019 mZxid = 0x3 mtime = Sat Aug 31 15:10:01 CST 2019 pZxid = 0x2 cversion = 0 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 7 numChildren = 0
删除节点:rmr /aaa
[zk: localhost:2181(CONNECTED) 9] rmr /aaa
ls /aaa watch
查看/aaa的子节点的同时,注册了一个监听节点的子节点变化事件的监听器
get /aaa watch 获取/aaa的value的同时,注册了一个监听节点value变化事件的监听器
[zk: localhost:2181(CONNECTED) 0]get /aaa watch
另起一个客户端修改aaa节点的数据
[zk: localhost:2181(CONNECTED) 10]set /aaa 999
[zk: localhost:2181(CONNECTED) 1] WATCHER:: WatchedEvent state:SyncConnected type:NodeDataChanged path:/aaa
监听到了节点数据发生了变化
### zookeeper客户端api
import java.util.List; import org.apache.zookeeper.CreateMode; import org.apache.zookeeper.KeeperException; import org.apache.zookeeper.ZooDefs.Ids; import org.apache.zookeeper.ZooKeeper; import org.junit.Before; import org.junit.Test; public class ZookeeperClientDemo { ZooKeeper zk = null; @Before public void init() throws Exception{ // 构造一个连接zookeeper的客户端对象 zk = new ZooKeeper("hdp-01:2181,hdp-02:2181,hdp-03:2181", 2000, null); } @Test public void testCreate() throws Exception{ // 参数1:要创建的节点路径 参数2:数据 参数3:访问权限 参数4:节点类型 String create = zk.create("/eclipse", "hello eclipse".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); System.out.println(create); zk.close(); } @Test public void testUpdate() throws Exception { // 参数1:节点路径 参数2:数据 参数3:所要修改的版本,-1代表任何版本 zk.setData("/eclipse", "我爱你".getBytes("UTF-8"), -1); zk.close(); } @Test public void testGet() throws Exception { // 参数1:节点路径 参数2:是否要监听 参数3:所要获取的数据的版本,null表示最新版本 byte[] data = zk.getData("/eclipse", false, null); System.out.println(new String(data,"UTF-8")); zk.close(); } @Test public void testListChildren() throws Exception { // 参数1:节点路径 参数2:是否要监听 // 注意:返回的结果中只有子节点名字,不带全路径 List<String> children = zk.getChildren("/cc", false); for (String child : children) { System.out.println(child); } zk.close(); } @Test public void testRm() throws InterruptedException, KeeperException{ zk.delete("/eclipse", -1); zk.close(); } }