Java中的集合
- 集合分为:List,Set,Map三种,其中List与Set是继承自Collection,而Map不是。

一、List与Set的区别:
List中的元素有存放顺序,并且可以存放重复元素,检索效率高,插入删除效率低;
Set没有存放顺序,而且不可以存放重复元素,后来的元素会把前面重复的元素替换掉,检索效率低,插入删除效率高。(Set存储位置是由它的HashCode码决定的,所以它存储的对象必须有equals()方法,而且Set遍历只能用迭代,因为它没有下标。)(参考1)
二、ArrayList与LinkList的区别:
ArrayList基层是以数组实现的,可以存储任何类型的数据,但数据容量有限制,超出限制时会扩增50%容量,把原来的数组复制到另一个内存空间更大的数组中,查找元素效率高。ArrayList是一个简单的数据结构,因超出容量会自动扩容,可认为它是常说的动态数组。
LinkList以双向链表实现,链表无容量限制,但双向链表本身使用了更多空间,每插入一个元素都要构造一个额外的Node对象,也需要额外的链表指针操作。允许元素为null,线程不安全。(参考2)
ArrayList和LinkList都实现了List接口,LinkList还额外实现了Deque接口。
综合比较结论:(参考3)
LinkList在增、删数据效率方面要优于ArrayList,而ArrayList在改和查方面效率要远超LinkList。
ArrayList查询直接根据下标查询,而LinkList需要遍历才能查到元素。增加时直接增加放在队尾,指定位置增加时,数组的元素会往后移动,而链表则需要进行先遍历到指定的位置。
但是,虽然综合比较之下LinkList的优势要比ArrayList要好,但是在java中,我们用的比较多的确实ArrayList,因为我们的业务通常是对数据的改和查用的比较多。线程是非安全的。
三、Map之间的区别
HashMap
数组
数组存储区间连续,占用内存比较严重,空间复杂度很大。但数组的二分查找时间复杂度小,为O(1);
数组的特点是:寻址容易,插入和删除困难;
链表
链表存储区间离散,占用内存比较宽松,空间复杂度很小,但时间复杂度很大,达O(N)。
链表的特点是:寻址困难,插入和删除容易。
HashMap
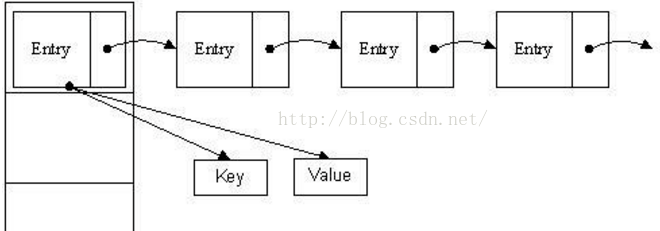
(1.7 数组+链表;1.8 数组+链表+红黑树)是用得最多的一种键值对存储的集合, 用一个数组来存储元素,但是这个数组存储的不是基本数据类型。HashMap实现巧妙的地方就在这里,数组存储的元素是一个Entry类,这个类有三个数据域,key、value(键值对),next(指向下一个Entry) 。
特点:HashMap允许空键值,并且它是非线程安全的,所以插入、删除和定位元素会比较快。
说一下HashMap的put方法
大体流程:
-
根据key通过哈希算法拿到一个HashCode结合与操作,与数组的长度-1进行运算,得到一个数组下标
-
如果得到的数组下标位置元素为空,则将key和value封装成Entry对象(1.7为Entry对象,1.8为Node对象)并放入该位置。
-
如果下标元素不为空,需要分情况讨论
a. 1.7 首先需要判断需不需要扩容,需要的话先扩容,如果不需要扩容则将Key和Value封装成Entry对象,采用头插法插入当前位置链表中。
b. 1.8 需要先判断是红黑树Node还是链表Node
- 如果是红黑树则需要将Key和Value封装成红黑树节点添加到红黑树中,在添加的过程中会判断是否包含节点,如果包含则更新
- 如果是链表则先将Key和Value封装成Node节点,采用尾插法进行插入,如果插入的过程中包含此节点则更新,如果没有则插入到最后。插入完之后如果节点个数大于等于8则转为红黑树存储。
- 插入完成之后则判断是否需要扩容,需要扩容则扩容,不需要则结束PUT方法。
Hashcode有什么作用
HashMap 的添加、获取时需要通过 key 的 hashCode() 进行 hash(),然后计算下标 ( n-1 & hash),从而获得要找的同的位置。当发生冲突(碰撞)时,利用 key.equals() 方法去链表或树中去查找对应的节点。
Hash
Hash是散列的意思,就是把任意长度的输入,通过散列算法变换成固定长度的输出,该输出就是散列值。关于散列值,有以下几个关键结论:
- 如果散列表中存在和散列原始输入K相等的记录,那么K必定在f(K)的存储位置上
- 不同关键字经过散列算法变换后可能得到同一个散列地址,这种现象称为碰撞
- 如果两个Hash值不同(前提是同一Hash算法),那么这两个Hash值对应的原始输入必定不同
HashCode
- HashCode的存在主要是为了查找的快捷性,HashCode是用来在散列存储结构中确定对象的存储地址的
- 如果两个对象equals相等,那么这两个对象的HashCode一定也相同
- 如果对象的equals方法被重写,那么对象的HashCode方法也尽量重写
- 如果两个对象的HashCode相同,不代表两个对象就相同,只能说明这两个对象在散列存储结构中,存放于同一个位置
总结
-
hashCode() 在散列表中才有用,在其它情况下没用
-
哈希值冲突了场景,hashCode相等,但equals不等
-
hashcode:计算键的hashcode作为存储键信息的数组下标用于查找键对象的存储位置
-
equals:HashMap使用equals()判断当前的键是否与表中存在的键相同。
-
如果两对象equals()是true,那么它们的hashCode()值一定相等,
-
如果两对象的hashCode()值相等,它们的equals不一定相等(hash冲突啦)
-
TreeMap
是基于红黑树实现的,适用于按自然顺序火兹定于顺序遍历key。
HashTable
是基于HashCode实现的(数组+链表),但它是线程安全的,无论key还是value都不能为null,所以会比HashMap效率低,而且不允许null值。
ConcurrentHashMap
(分段数组+链表),线程安全。
四、Set中最常用的集合:HashSet
HashSet是使用Hash表实现的,集合里面的元素是无序得,可以有null值,但是不能有重复元素。(参考1)
特点:因为相同的元素具有相同的hashCode,所以不能有重复元素
六、针对ArrayList的操作
- List 包含的方法(参考5)
-
add(Object element): 向列表的尾部添加指定的元素。
-
size(): 返回列表中的元素个数。
-
get(int index): 返回列表中指定位置的元素,index从0开始。
-
add(int index, Object element): 在列表的指定位置插入指定元素。
-
set(int i, Object element):
将索引i位置元素替换为元素element并返回被替换的元素。
-
clear(): 从列表中移除所有元素。
-
isEmpty():
判断列表是否包含元素,不包含元素则返回 true,否则返回false。
-
contains(Object o): 如果列表包含指定的元素,则返回 true。
-
remove(int index): 移除列表中指定位置的元素,并返回被删元素。
-
remove(Object o):
移除集合中第一次出现的指定元素,移除成功返回true,否则返回false。
-
iterator(): 返回按适当顺序在列表的元素上进行迭代的迭代器。
-
排序
Collections.sort(list); //针对一个ArrayList内部的数据排序 如果想自定义排序方式则需要有类来实现Comparator接口并重写compare方法 调用sort方法时将ArrayList对象与实现Commparator接口的类的对象作为参数 -- 调用 Collections.sort(list, new SortByAge()); -- 实现接口 class SortByAge implements Comparator { public int compare(Object o1, Object o2) { Student s1 = (Student) o1; Student s2 = (Student) o2; return s1.getAge().compareTo(s2.getAge()); } } 注:compareTo方法比较字符串,但是也可以比较数字(数字为String类型) 原理:先比较字符串长度,再逐一转成char类型去比较字符串里的每一个字符。 -
遍历
-- for循环的遍历方式 for (int i = 0; i < lists.size(); i++) { System.out.print(lists.get(i)); } -- foreach的遍历方式 for (Integer list : lists) { System.out.print(list); } -- Iterator的遍历方式 for (Iterator list = lists.iterator(); list.hasNext();) { System.out.print(list.next()); } -
删除
lists.remove(6); //指定删除 List 删除元素的逻辑是将目标元素之后的元素往前移一个索引位置, 最后一个元素置为 null,同时 size - 1。 遍历删除时,操作不当会导致异常, 原因:ArrayList 中两个 remove() 方法都对 modCount 进行了自增, 那么我们在用迭代器迭代的时候,若是删除末尾 的元素, 则会造成 modCount 和 expectedModCount 的不一致导致异常抛出。 Iterator 迭代遍历删除是最安全的方法。(参考4) -- 示例: public static void remove(List list, String target){ Iterator iter = list.iterator(); while (iter.hasNext()) { String item = iter.next(); if (item.equals(target)) { iter.remove(); } } System.out.println(list); } -
去重(参考6)
-
利用HashSet(不保证元素顺序一致)
-
利用LinkedHashSet (去重后顺序一致),继承的父类HashSet