一、ORM
1-1 查询API:
all() # 查询所有结果
get(**kwargs) # 返回与所给筛选条件相匹配的对象,返回的结果有且只有一个,超过则报错
values(*field) # 返回一个valueQuerySet,一个特殊QuerySet(对象集合),返回结果是
一个可迭代的字典序列
exclude(**kwargs) # 它包含了与所给筛选条件不匹配的对象
order_by(*field) # 对查询结果进行排序
reverse() # 对查询结果进行反向排序
distinct() # 从返回结果中剔除重复记录
count() # 返回数据库中匹配查询(QuerySet)的对象数量
first() # 返回第一条记录
last() # 返回最后一条记录
exists() # 如果QuerySet包含数据,就返回True,否则返回False
1-2 双下划线查询
model.Tb1.objects.filter(id__in[11, 22, 33]) # 获取id等于11、22、33的数据
model.Tb1.objects.exclude(id__lt=10, id__gt=1)# 获取id不等于11、22、33的数据
model.Tb1.objects.filter(name_contains='ven') # 获取name值包含ven(区分大小写)
model.Tb1.objects.filter(name_icontains='ven') # 获取name值包含ven(不区分大小写)
model.Tb1.objects.filter(id__range=[1, 3]) # 获取id在区间1~3中的值(范围bettwen and)
1-3 多表操作(多对多):
创建多对多的关系 author = models.ManyToManyFiled("Author")
书籍对象它的所有关联作者 obj = book_obj.authors.all()
绑定多对多关系 obj.add(*QuerySet) 参数:一条或者多条(前面加*)
解除多对多关系 obj.remove(author_obj)
------------> 聚合查询和分组查询
<1> aggregate(*args, **kwargs):
通过对QuerySet进行计算,返回一个聚合值的字典。aggregate()中每一个参数指定一个包含在字典中的返回值。即在查询集上生产聚合
从整个查询生产统计值。比如,你想要计算所有在售书的平均值。Django的查询语法提供了一种方式描述
所有图书的集合
<2> annotate(*args, **kwargs):
通过计算查询结果中每一个对象所关联的对象集合,从而得出总计值(也可以是平均值或总和),
即为查询集的每一项生产聚合。
查询alex出的书总价格

查询各个作者出的书的总价格,这里就涉及到分组了,分组条件是authors_name

------------> 惰性机制
所谓惰性机制:Publisher.objects.all()或者.filter()等都只是返回了一个QuerySet(查询结果集对象),
它并不会马上执行sql语句,而是当调用QuerySet的时候才执行。
QuerySet 特点:
1、可迭代的
2、可切片
QuerySet: 可迭代
for obj in objs: # 每一个obj就是一行对象
print("obj:", obj)
QuerySet: 可切片
print(objs[1])
print(objs[1:4])
print(objs[::-1])
------------> 迭代器对象(iterator())
当QuerySet非常巨大时,cache会成为问题
让你的程序濒临崩溃。要避免在遍历数据的同时产生QuerySet cache(缓存),可以使用iterator()方法
来获取数据,处理完成就将其丢弃。
objs = Book.objects.all().iterator()
# iterator() 可以一次只从数据库获取少量数据,这样可以节省内存
for obj in objs:
print(obj.name)
# BUT,再次遍历就没有打印,因为迭代器已经在上一次遍历(next)到最后一次了,再次遍历就没有了数据
# 当然,使用iterator()方法来防止生产cache,意味着遍历同一个QuerySet是会重复执行查询。所有
# 用iterator()的时候要当心,确保你的代码在操作一个大的QuerySet是没有重复执行查询
总结:
QuerySet的cache是用于减少程序对数据库的查询,在通常的使用下会保证只有在需要的时候才会查询
数据库。使用exists()和iterator()方法可以优化程序对内存的使用。不过,由于它们并不会产生
QuerySet cache,可能会对造成额外的数据库查询。
总而言之,再执行代码中,需多次查询数据库时,使用cache中的exists;数据量较大时,使用
iterator迭代器对象
二 、 admin(数据库内容管理)
Django 提供了基于 web 的管理工具。
<1>生产迁移表

<2>创建超级用户

二、templates模板语言
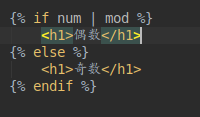
1-1自定义过滤器
自定义过滤器函数,至少有一个参数,最多两个参数
1)在应用里新建templatetags文件夹

2)设计代码逻辑
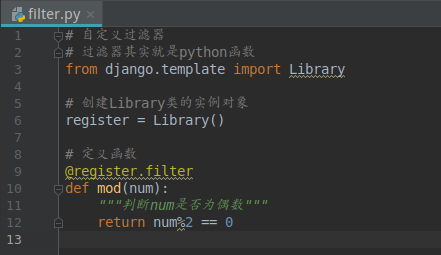
3)进入到模板页面中到导入刚创建的filter.py文件

4)调用自定义的过滤器