一、安装
在cmd中直接运行pip install beautifulsoup4进行安装
二、原理
BeautifulSoup4(html)
获取节点:find()、find_all()/select()
获取属性:attrs
获取文本:text
原理:beautifulsoup4将复杂的HTML文档转换成一个树形结构,每个节点都是Python对象。
三、使用
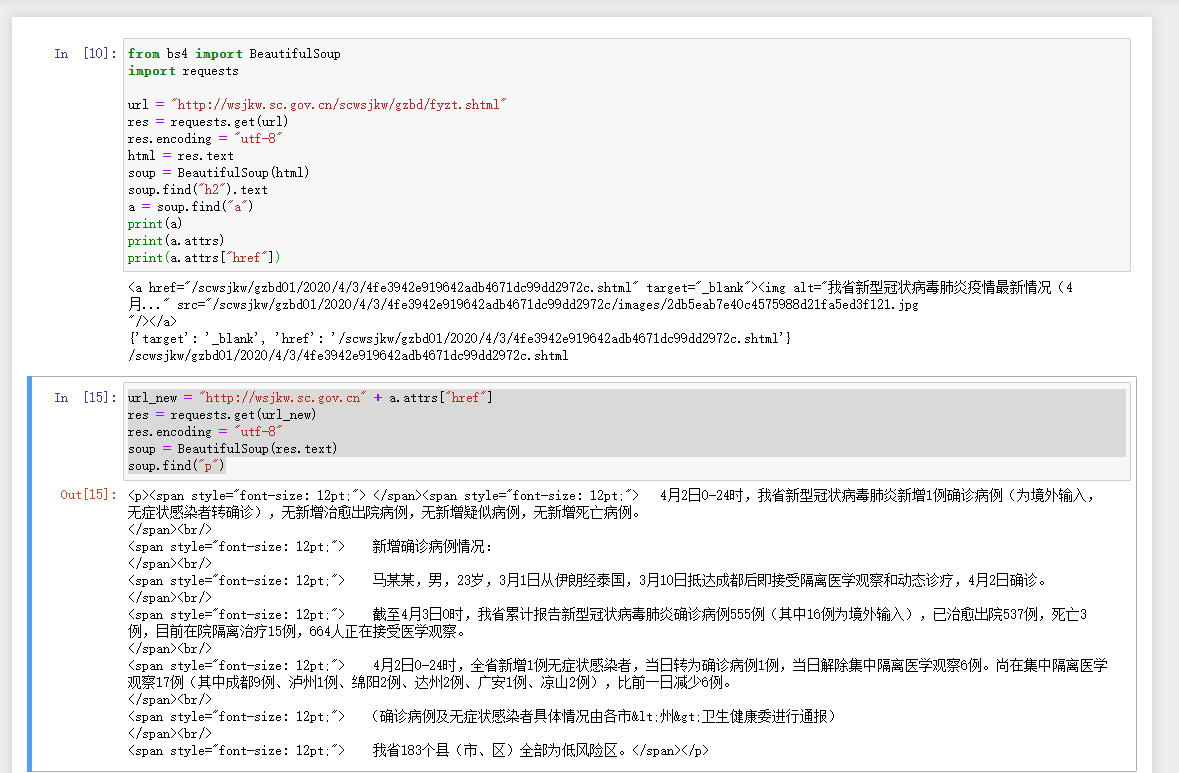
from bs4 import BeautifulSoup import requests url = "http://wsjkw.sc.gov.cn/scwsjkw/gzbd/fyzt.shtml" res = requests.get(url) res.encoding = "utf-8" html = res.text soup = BeautifulSoup(html) soup.find("h2").text a = soup.find("a") print(a) print(a.attrs) print(a.attrs["href"])
上面是通过BeautifulSoup(html)方法来解析得到的res.text信息,找到打印href
url_new = "http://wsjkw.sc.gov.cn" + a.attrs["href"] res = requests.get(url_new) res.encoding = "utf-8" soup = BeautifulSoup(res.text) soup.find("p")
用上面找到的href来进行url拼接,并且用过CSS样式的标签来找到需要的信息
四、效果展示
五、总结
beautifulsoup4是将requests请求的text信息进行解析,然后可以通过不同的CSS标签来取到想要的信息或者内容。