一、使用request发送请求
安装:pip install requests(cmd命令行下执行)
二、requests的基本使用
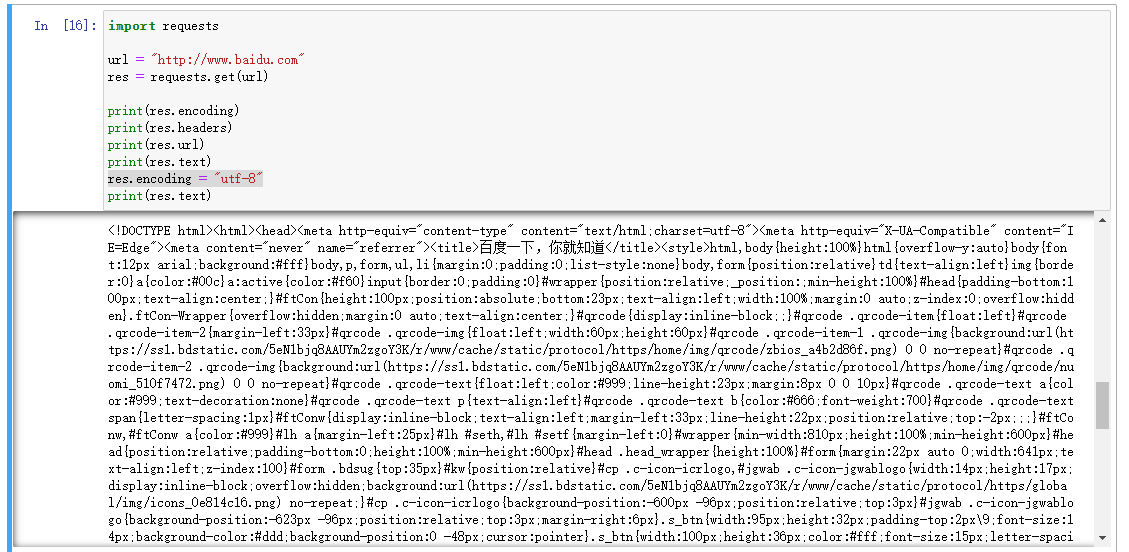
import requests
url = "http://www.baidu.com"
res = requests.get(url)
print(res.encoding)
print(res.headers) #里面如果没有Content-Type,encoding=utf-8 ,否则如果charset,就以设置为准,否则就是ISO-8859-1
print(res.url)
运行结果:

print(res.text)是打印内容如果不设置encoding = "utf-8"就会有乱码,反之设置了就不会出现乱码了。
三、添加Headers来进行反爬
import requests
url = "http://www.dianping.com"
#下面的是开发者模式下百度的User-Agent
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36"
}
res = requests.get(url,headers=header)
print(res.encoding)
print(res.headers)
print(res.url)
print(res.text)
print(res.status_code)
四、总结
requests请求和urllib请求方式大同小异,都是获取网站信息的请求方式。