Nginx的访问日志轮询切割
通常什么情况Nginx会把所有的访问日志生成到一个制定的访问日志文件access.log里面,但时间一长,日志个头很大不利于日志的分析和处理。
有必要对Nginx日志进行按天或按小时进行切割,分成不同的文件保存。
[root@www logs]#cat /server/script/cut_nginx_log.sh
#!/bin/sh
Dataformat = `date +%Y%m%d`
Basedir = "/usr/local/nginx"
Nginxlogdir = "$Basedir/logs"
Logname = "access_www"
[ -d $Nginxlogdir ] && cd $Nginxlogdir || exit 1
[ -f ${Logname}.log] || exit 1
/bin/mv ${Logname}.log ${Dateformat}_${Logname}.log
$Basedir/sbin/nginx -s reload
注意:脚本实现切割Nginx日志的思想为讲正在写入的Nginx日志改名为(20161111_access_www.log),然后平滑重启生成新的nginx日志(access_www.log)
通过定时任务实现每天的00点整定时执行/server/script/cut_nginx_log.sh
00 00 * * * /bin/sh /server/script/cut_nginx_log.sh >/dev/null 2>&1
Nginx 的location语法
location的使用基本语法:
location [= | ~ | ~* | ^~] uri { .... } location 指令 [=|~|~*|@] 匹配标识 uri 匹配的网站网址 {。。。。} 匹配URI后要执行的配置段
~ 区分大小写(大小写敏感)
~* 不区分大小写匹配
!取反
^~ 的作用是用来进行常规的字符串匹配检查之后不做正则表达式的检查
匹配实例
location = / {
[ configuration A]
}
location / {
[ configuration B]
}
location /documents/ {
[ configuration C]
}
location ^~ /images/ {
[ configuration D]
}
location ~* .(gif|jpg|jpeg)$ {
[ configuration E]
}
用户请求的URL
http://www.abc.com/ 匹配A / http://www.abc.com/ 匹配B /index.html http://www.abc.com/documents/document.html 匹配C /documents/document.html http://www.abc.com/images/1.gif 匹配D /images/1.gif http://www.abc.com/documents/1.gif 匹配E /documents/1.gif
Nginxd rewrite
进行转义 ^ 匹配输入字符串的起始位置 $ 匹配输入字符串的结束位置 * 匹配0次或多次 + 匹配1次到多次 ? 匹配0次到1次 . 匹配除 以外的任意字符 (pattern) 匹配括号内的字符
rewrite 指令最后一项参数flag标记说明
last 本条规则匹配完成后,继续向下匹配新的location URI规则
break 本条规则匹配完成即终止,不在匹配后面的任何规则
redirect 返回302 临时重定向, 浏览器地址栏会显示跳转后的URI地址
permanent 返回301 永久重定向, 浏览器地址栏会显示跳转后的URI地址
实例:
rewrite ^/(.*) http://www.abc.com/$1 permanent;
Nginx负载均衡
负载均衡模块的组件
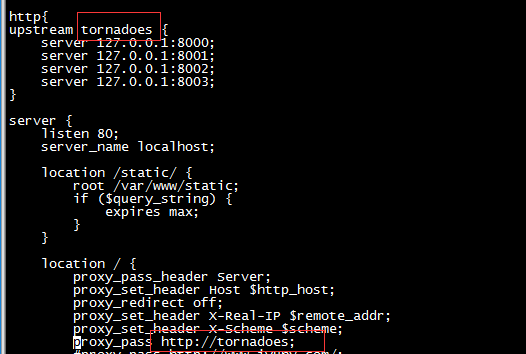
ngx_http_proxy_module proxy代理模块 ngx_http_upstream_module 负载均衡模块
upstream www_server_pools { #upstream 关键字 www_server_pools 集群组的名字,可以自己起名字
server 10.1.1.1:80 weight=5; #server关键字 ip/域名:端口, 默认80 weight权重
server 10.1.1.1:80 weight=5; #如果用域名解析,需要在hosts里面有域名解析;或者内网有DNS
server www.abc.com:80 weight=5 backup;
server unix:/temp/backend3; #指定socket文件/可以不写
}
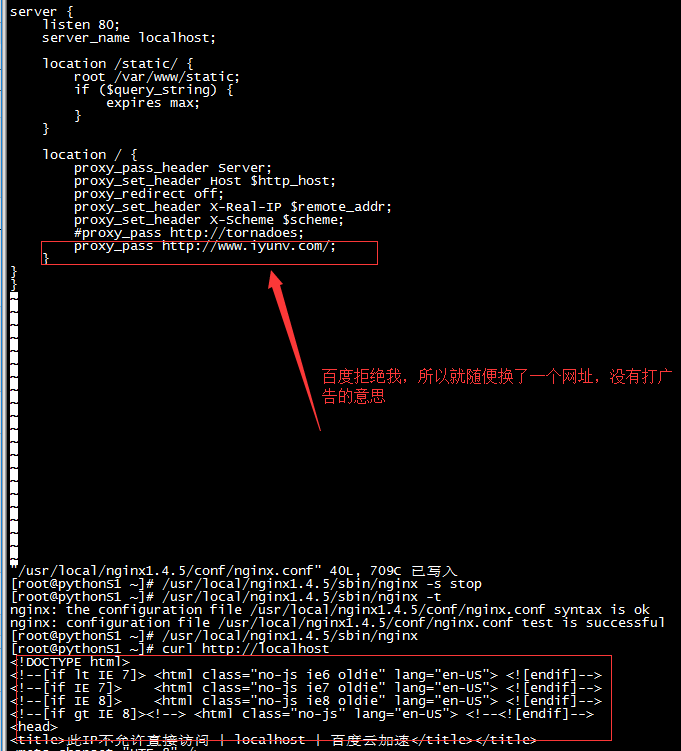
通过proxy_pass 功能把用户的请求交由上面反向代理upstream定义的tornadoes服务器池处理
weight = 1 代表服务器权重,默认值是1, 权重数字表示接受的请求比例越大;
max_fails = 1 nginx尝试连接主机失败的次数,这个值是配合proxy_next_upstream、fastcgi_next_upstram 和 memcached_mext_upstream三个参数来使用的。
backup 热备配置(RS节点的高可用),当当前激活的RS都失败后会自动启动热备RS。这标志这个服务器作为备份服务器,如果主宕机,就会向他转发请求。注意:
当负载调度算法为ip_hash时,后端服务器不能是weight和backup
fail_timeout = 10s 在max_fails定义失败次数后,距离下次检查的间隔时间,默认是10s;如果是5,就检测5次,如果5次都是502,那么就等待10s在去检查
down 标志这服务器永远不可用,这个参数可以配合ip_hash使用
upstream 模块调度算法
1.rr轮询(默认调度算法,静态调度算法)
相当于lvs的rr算法,如果后端节点服务器宕机(默认检测80),自动会从节点地址池剔除
2.wrr(权重轮询,静态调度算法)
例子:
upstream pools{
server 192.168.1.1 weight=1;
server 192.168.1.2 weight=2;
}
3.ip_hash(静态调度算法)
每个请求按客户端的IP的hash进行分配;缺点可能道士分配不均无法保证1:1的负载均衡。比如客户端的nat上网方式
例子:
upstream pools{
ip_hash;
server backend1.example.com; #可以用ip
server backend2.example.com down;
}
注意:ip_hash时,不能有weight和backup
4.fair(动态调度算法) 此算法会根据后端节点服务器的响应时间来分配请求,响应时间短的优先分配 nginx 本身不支持fair调度算法,需要下载nginx的相关模块upstram_fair 例子: upstream pool{ server 192.168.1.1; server 192.168.1.2; fair; }
5.least_conn
此算法会根据后端节点的连接数来决定分配情况,那个机器连接数少就分发。
6.url_hash算法
和ip_hash 类似,这个是根据访问 URL的hash分配的。同样也不能写入weight等
必须安装nginx的哈市模块软件包
例子:
upstream pools{
server queid1:1233;
server squid2:1233;
hash $request_uri;
hash_method crc32;
}
7.一致性hash算法
Nginx反向代理
http_proxy_module 模块
此模块可以将请求转发到另一台服务器,在实际的反向代理工作中,或通过location功能指定URL,然后在接受到的符合匹配的URI的请求通过proxy_pass 抛给定义好的upstream节点池
案例:
1.将匹配URI为name的请求抛给http://127.0.0.1/remote/
location /name/ { proxy_pass http://127.0.0.1/remote/; }
2.将匹配URI为name的请求应用指定的rewrite规则,然后抛给http://127.0.0.0.1.
location /name/ {
rewrite /name/([^/]+) /users?name=$1 break;
proxy_pass http://127.0.0.1;
}