理解什么是字符编码?
计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
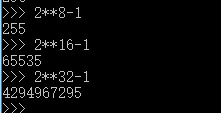
那么1字节能够转换的最大二进制位为:2**64-1
ASCII编码:
一个英文字母占一个字节空间
其实ascii编码就是一张表,早期的时候只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母 A 的编码是65,小写字母 z 的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。


Bin(二进制) Oct(八进制) Dec(十进制) Hex(十六进制) 缩写/字符 解释 0000 0000 0 0 00 NUL(null) 空字符 0000 0001 1 1 01 SOH(start of headline) 标题开始 0000 0010 2 2 02 STX (start of text) 正文开始 0000 0011 3 3 03 ETX (end of text) 正文结束 0000 0100 4 4 04 EOT (end of transmission) 传输结束 0000 0101 5 5 05 ENQ (enquiry) 请求 0000 0110 6 6 06 ACK (acknowledge) 收到通知 0000 0111 7 7 07 BEL (bell) 响铃 0000 1000 10 8 08 BS (backspace) 退格 0000 1001 11 9 09 HT (horizontal tab) 水平制表符 0000 1010 12 10 0A LF (NL line feed, new line) 换行键 0000 1011 13 11 0B VT (vertical tab) 垂直制表符 0000 1100 14 12 0C FF (NP form feed, new page) 换页键 0000 1101 15 13 0D CR (carriage return) 回车键 0000 1110 16 14 0E SO (shift out) 不用切换 0000 1111 17 15 0F SI (shift in) 启用切换 0001 0000 20 16 10 DLE (data link escape) 数据链路转义 0001 0001 21 17 11 DC1 (device control 1) 设备控制1 0001 0010 22 18 12 DC2 (device control 2) 设备控制2 0001 0011 23 19 13 DC3 (device control 3) 设备控制3 0001 0100 24 20 14 DC4 (device control 4) 设备控制4 0001 0101 25 21 15 NAK (negative acknowledge) 拒绝接收 0001 0110 26 22 16 SYN (synchronous idle) 同步空闲 0001 0111 27 23 17 ETB (end of trans. block) 结束传输块 0001 1000 30 24 18 CAN (cancel) 取消 0001 1001 31 25 19 EM (end of medium) 媒介结束 0001 1010 32 26 1A SUB (substitute) 代替 0001 1011 33 27 1B ESC (escape) 换码(溢出) 0001 1100 34 28 1C FS (file separator) 文件分隔符 0001 1101 35 29 1D GS (group separator) 分组符 0001 1110 36 30 1E RS (record separator) 记录分隔符 0001 1111 37 31 1F US (unit separator) 单元分隔符 0010 0000 40 32 20 (space) 空格 0010 0001 41 33 21 ! 叹号 0010 0010 42 34 22 " 双引号 0010 0011 43 35 23 # 井号 0010 0100 44 36 24 $ 美元符 0010 0101 45 37 25 % 百分号 0010 0110 46 38 26 & 和号 0010 0111 47 39 27 ' 闭单引号 0010 1000 50 40 28 ( 开括号 0010 1001 51 41 29 ) 闭括号 0010 1010 52 42 2A * 星号 0010 1011 53 43 2B + 加号 0010 1100 54 44 2C , 逗号 0010 1101 55 45 2D - 减号/破折号 0010 1110 56 46 2E . 句号 00101111 57 47 2F / 斜杠 00110000 60 48 30 0 数字0 00110001 61 49 31 1 数字1 00110010 62 50 32 2 数字2 00110011 63 51 33 3 数字3 00110100 64 52 34 4 数字4 00110101 65 53 35 5 数字5 00110110 66 54 36 6 数字6 00110111 67 55 37 7 数字7 00111000 70 56 38 8 数字8 00111001 71 57 39 9 数字9 00111010 72 58 3A : 冒号 00111011 73 59 3B ; 分号 00111100 74 60 3C < 小于 00111101 75 61 3D = 等号 00111110 76 62 3E > 大于 00111111 77 63 3F ? 问号 01000000 100 64 40 @ 电子邮件符号 01000001 101 65 41 A 大写字母A 01000010 102 66 42 B 大写字母B 01000011 103 67 43 C 大写字母C 01000100 104 68 44 D 大写字母D 01000101 105 69 45 E 大写字母E 01000110 106 70 46 F 大写字母F 01000111 107 71 47 G 大写字母G 01001000 110 72 48 H 大写字母H 01001001 111 73 49 I 大写字母I 01001010 112 74 4A J 大写字母J 01001011 113 75 4B K 大写字母K 01001100 114 76 4C L 大写字母L 01001101 115 77 4D M 大写字母M 01001110 116 78 4E N 大写字母N 01001111 117 79 4F O 大写字母O 01010000 120 80 50 P 大写字母P 01010001 121 81 51 Q 大写字母Q 01010010 122 82 52 R 大写字母R 01010011 123 83 53 S 大写字母S 01010100 124 84 54 T 大写字母T 01010101 125 85 55 U 大写字母U 01010110 126 86 56 V 大写字母V 01010111 127 87 57 W 大写字母W 01011000 130 88 58 X 大写字母X 01011001 131 89 59 Y 大写字母Y 01011010 132 90 5A Z 大写字母Z 01011011 133 91 5B [ 开方括号 01011100 134 92 5C 反斜杠 01011101 135 93 5D ] 闭方括号 01011110 136 94 5E ^ 脱字符 01011111 137 95 5F _ 下划线 01100000 140 96 60 ` 开单引号 01100001 141 97 61 a 小写字母a 01100010 142 98 62 b 小写字母b 01100011 143 99 63 c 小写字母c 01100100 144 100 64 d 小写字母d 01100101 145 101 65 e 小写字母e 01100110 146 102 66 f 小写字母f 01100111 147 103 67 g 小写字母g 01101000 150 104 68 h 小写字母h 01101001 151 105 69 i 小写字母i 01101010 152 106 6A j 小写字母j 01101011 153 107 6B k 小写字母k 01101100 154 108 6C l 小写字母l 01101101 155 109 6D m 小写字母m 01101110 156 110 6E n 小写字母n 01101111 157 111 6F o 小写字母o 01110000 160 112 70 p 小写字母p 01110001 161 113 71 q 小写字母q 01110010 162 114 72 r 小写字母r 01110011 163 115 73 s 小写字母s 01110100 164 116 74 t 小写字母t 01110101 165 117 75 u 小写字母u 01110110 166 118 76 v 小写字母v 01110111 167 119 77 w 小写字母w 01111000 170 120 78 x 小写字母x 01111001 171 121 79 y 小写字母y 01111010 172 122 7A z 小写字母z 01111011 173 123 7B { 开花括号 01111100 174 124 7C | 垂线 01111101 175 125 7D } 闭花括号 01111110 176 126 7E ~ 波浪号 01111111 177 127 7F DEL (delete) 删除
Unicode编码:
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
Utf-8编码:
新问题的出现:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
因此,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节
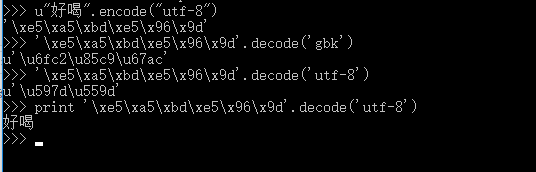
python2 Unicode 和UTF-8等编码的转换过程图解


# -*- coding:utf-8 -*-
python2 以Unicode为编码
In [34]: a ="账号" # --》 将汉字用16进制形式展示
In [35]: a
Out[35]: 'xe8xb4xa6xe5x8fxb7'
In [36]: print a
账号
>>> a = u"账号"
>>> a
u'u8d26u53f7'
su = "人生苦短" # : su是一个utf-8格式的字节串 u = s.decode("utf-8") # : s被解码为unicode对象,赋给u sg = u.encode("gbk") # : u被编码为gbk格式的字节串,赋给sg print sg # 打印sg
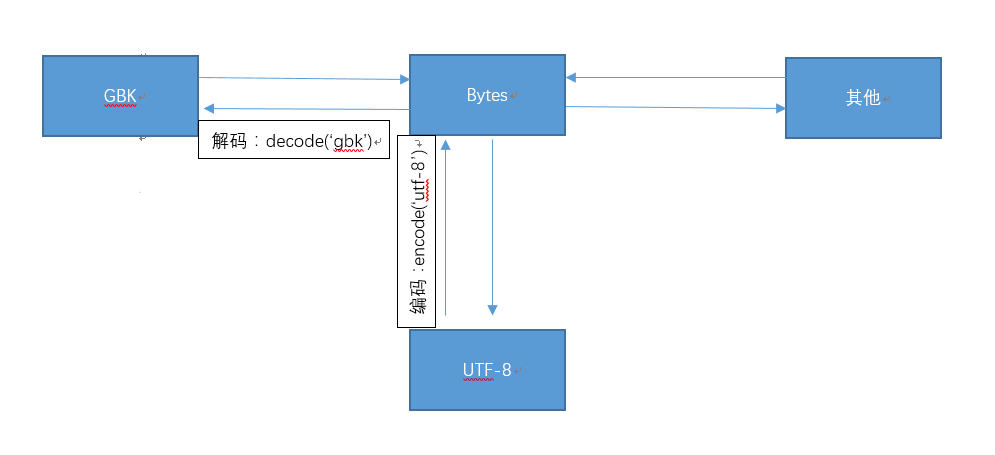
python3编码转换过程
filename = filename.encode('cp437').decode('gbk')
>>> a = "ads水电费"
>>> a.encode("utf-8").decode('cp437') 'adsµ░┤τö╡Φ┤╣' >>> a.encode("utf-8").decode('gbk') Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeDecodeError: 'gbk' codec can't decode byte 0xb9 in position 11: incomplete multibyte sequence >>> a.encode("utf-8").decode('gbk', 'ignore') 'ads姘寸數璐' >>>
>>> a.encode("utf-8").decode('utf-8')
'ads水电费'
注释: ignore 是忽略非法字符的意思
# -*- coding: utf-8 -*-的三个作用
顶部的:# -*- coding: utf-8 -*-目前看来有三个作用。
如果代码中有中文注释,就需要此声明
比较高级的编辑器(比如我的emacs),会根据头部声明,将此作为代码文件的格式。
程序会通过头部声明,解码初始化 u”人生苦短”,这样的unicode对象,(所以头部声明和代码的存储格式要一致)
set defaultcoding
默认的defaultcoding:ascii是许多错误的原因,所以早早的设置defaultencoding是一个好习惯。
如果你在Python中进行编码和解码的时候,不指定编码方式,那么python就会使用defaultencoding。 而python2.x的的defaultencoding是ascii,
这也就是大多数python编码报错:
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe8 in position 0: ordinal not in range(128)
设置defaultencoding的代码如下:
reload(sys) sys.setdefaultencoding('utf-8')
如果你在python中进行编码和解码的时候,不指定编码方式,那么python就会使用defaultencoding。
比如上一节例子中将str编码为另一种格式,就会使用defaultencoding。
s.encode("utf-8") 等价于 s.decode(defaultencoding).encode("utf-8")
再比如你使用str创建unicode对象时,如果不说明这个str的编码格式,那么程序也会使用defaultencoding。
u = unicode("人生苦短") 等价于 u = unicode("人生苦短",defaultencoding)
默认的defaultcoding:ascii是许多错误的原因,所以早早的设置defaultencoding是一个好习惯。