概要:
- cookie反爬处理机制
- 代理机制
1、cookie反爬处理机制
案例1:
爬取雪球网站中相关的新闻数据
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61'
}
url = 'https://xueqiu.com/statuses/hot/listV2.json?since_id=-1&max_id=66208&size=15'
json_data = requests.get(url=url,headers=headers).json()
print(json_data)
结果:
{'error_description': '遇到错误,请刷新页面或者重新登录帐号后再试',
'error_uri': '/statuses/hot/listV2.json',
'error_data': None,
'error_code': '400016'}
上述代码没有获取想要的数据,问题原因?
- 通过requests模块模拟浏览器发请求,模拟的程度不够
- 重点体现在请求头信息中。
方式一解决:
手动处理将cookice信息添加到请求头中即可
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
'Cookie':'aliyungf_tc=AQAAANW0eGAa9gsAWFJ5eyKzKfjHGKly; acw_tc=2760824315924751287984449e7480f71707bc6a5df30bb7aa7b4a2af287e9; xq_a_token=ea139be840cf88ff8c30e6943cf26aba8ad77358; xqat=ea139be840cf88ff8c30e6943cf26aba8ad77358; xq_r_token=863970f9d67d944596be27965d13c6929b5264fe; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTU5NDAwMjgwOCwiY3RtIjoxNTkyNDc1MDcxODU5LCJjaWQiOiJkOWQwbjRBWnVwIn0.lQ6Kp8fZUrBSjbQEUpv0PmLn2hZ3-ixDvYgNPr8kRMNLt5CBxMwwAY9FrMxg9gt6UTA4OJQ1Gyx7oePO1xJJsifvAha_o92wdXP55KBKoy8YP1y2rgh48yj8q61yyY8LpRTHP5RKOZQITh0umvflW4zpv05nPr7C8fHTME6Y80KspMLzOPw2xl7WFsTGrkaLH8yw6ltKvnupK7pQb1Uw3xfzM1TzgCoxWatfjUHjMZguAkrUnPKauEJBekeeh3eVaqjmZ7NzRWtLAww8egiBqMmjv5uGMBJAuuEBFcMiFZDIbGdsrJPQMGJdHRAmgQgcVSGamW8QWkzpyd8Tkgqbwg; u=161592475128805; device_id=24700f9f1986800ab4fcc880530dd0ed; Hm_lvt_1db88642e346389874251b5a1eded6e3=1592475130,1592475300; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1592475421'
}
url = 'https://xueqiu.com/statuses/hot/listV2.json?since_id=-1&max_id=66208&size=15'
json_data = requests.get(url=url,headers=headers).json()
print(json_data)
方式二解决:
自动处理
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36',
}
sess = requests.Session() #返回一个session对象
#第一次调用session一定是为了捕获cookie
main_url = 'https://xueqiu.com/'
sess.get(url=main_url,headers=headers) #目的:尝试捕获cookie,cookie就会被存储到session
url = 'https://xueqiu.com/statuses/hot/listV2.json?since_id=-1&max_id=65993&size=15'
#已经表示携带cookie发起了请求
json_data = sess.get(url=url,headers=headers).json()
print(json_data)
爬虫中cookie的处理方式有两种
- 手动处理
- 将抓包工具中的cookie写入到headers中即可
- 自动处理
- session对象。该对象可以像requests一样进行get和post请求的发送。唯一的不同之处在于,如果使用session进行请求发送的,如果在请求中产生了cookie,则cookie会被自动保存到该session对象中。
- 在爬虫使用session对象,该对象至少要被爬虫程序调用两次。
2、代理机制
-
什么是代理
- 代理服务器
-
代理的作用
- 转发请求&响应。
-
代理和爬虫之间的关联
- 如果短时间内,向服务器端发起了高频的网络请求,服务器端会检测到这样的异常现象,可能就会将客户端的ip禁掉,表示当前客户端就无法再次访问该服务器端。
-
代理的基本概念
- 代理的匿名度
- 透明:目的服务器可以知道你使用了代理,也知道你的真实ip
- 匿名:知道你使用了代理,不知道你的真实ip
- 高匿:不知道使用了代理,也不知道真实ip
- 代理的类型:
- http:该代理只可以转发http协议的请求
- https:只可以转发https协议的请求
- 代理的匿名度
-
如何获取代理?
- 收费代理平台:http://http.zhiliandaili.cn/
智连HTTP使用
1、注册账号,添加当前本机的IP地址到白名单

2、土豪可自行购买,在这,我使用的免费的,每天有免费的代理IP
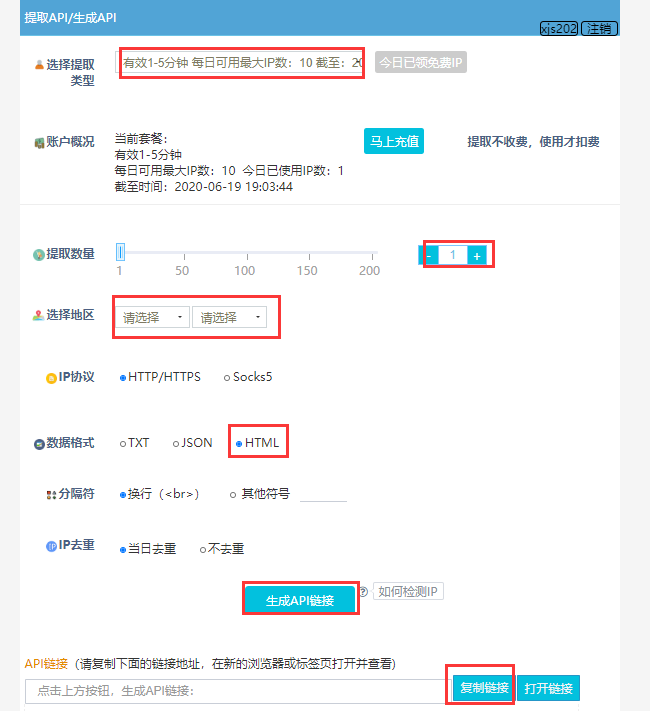
3、浏览器访问生成的代理ip链接,有1条代理IP

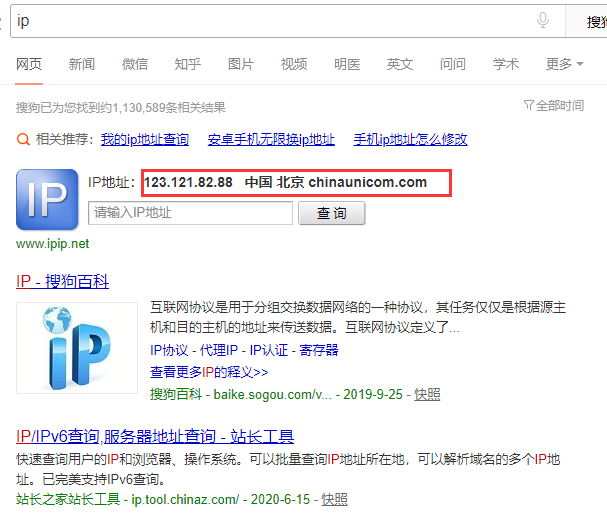
4、没有使用代理ip,查询本机ip
手动查询:
代码查询:
from lxml import etree
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36',
'Cookie':'BIDUPSID=E7A59AC0805CB60E79CF4C235E336D22; PSTM=1591782404; BAIDUID=C4749F7C59E75CCF5509B5A8E38221E9:FG=1; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BDUSS=GVTdU1jWlZ1ZzRxOVhmT29rdmVNWnFrUTE2bW41VkxQUEp-Z0FDaGJjVjhkUkpmSVFBQUFBJCQAAAAAAAAAAAEAAADaHpEpzOG~qcrH0afPsLXEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHzo6l586Opee; BDUSS_BFESS=GVTdU1jWlZ1ZzRxOVhmT29rdmVNWnFrUTE2bW41VkxQUEp-Z0FDaGJjVjhkUkpmSVFBQUFBJCQAAAAAAAAAAAEAAADaHpEpzOG~qcrH0afPsLXEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHzo6l586Opee; BDSFRCVID=YuCOJexroG3_K8nugpyUb4TrBgKKe4oTDYLEptww7unQ1ttVJeC6EG0Pts1-dEu-EHtdogKK0gOTH6KF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF=tbIJVI-yfIvbfP0kM4r5hnLfbeT22-ustHcC2hcH0KLKMhbzDb8-5t-UBPO30j5baKkt2lbJJMb1MRjvyn6cjT8Nb4TXKMrGt6Pfap5TtUJaSDnTDMRhqtK7jq3yKMnitIj9-pnG2hQrh459XP68bTkA5bjZKxtq3mkjbPbDfn028DKuDT0ajjcbeausaI6B2Cvt3Rrj5njEDbIk-PnVept9yPnZKxtqtDjq0qTnbt5JftT_-6OxKxDQXHrAKR5nWncKWbO1bnnNbb55QMcvLRtg5lr405OTaaIO0KJc0RoNs5CwhPJvyT8DXnO7L4nlXbrtXp7_2J0WStbKy4oTjxL1Db3JKjvMtIFtVD8MtKDhMK8Gen6sMtu_MhOJbI6QM67O3tI8Kbu3JhrGXU6qLT5Xh-jD5j-qbCvtXl5tJUbKEx52M4oN5l0njxQybt7N0GuO_xt2tqvIo4LC3xonDh8e3H7MJUntKeCDQ-bO5hvvhb6O3M7lMUKmDloOW-TB5bbPLUQF5l8-sq0x0bOte-bQbG_EJ6nK24oa3RTeb6rjDnCrWJoTXUI82h5y05JdWbbXLR3MMx5DMMb4L4JvyPQ3hnORXx74-TnfLK3aafDaf-bKy4oTjxL1Db3Jb5_L5gTtsl5dbnboepvoD-Jc3MvByPjdJJQOBKQB0KnGbUQkeq8CQft20b0EeMtjW6LEK5r2SC05JCnP; H_PS_PSSID=32100_1432_31326_21114_31254_32046_31708_30824_32110_26350_22157; delPer=0; PSINO=3; ZD_ENTRY=baidu'
}
#没有使用代理获取的本机ip
url = 'https://www.baidu.com/s?ie=UTF-8&wd=ip'
# url = 'https://www.sogou.com/web?query=ip'
page_text = requests.get(url=url,headers=headers).text
tree = etree.HTML(page_text)
#在xpath表达式中不可以出现tbody标签,否则会解析出错
ip_data = tree.xpath('//*[@id="1"]/div[1]/div[1]/div[2]/table//tr/td/span/text()')
# ip_data = tree.xpath('//*[@id="ipsearchresult"]/strong/text()')
print(ip_data)
>>>
['本机IP:xa0123.121.82.88']
5、使用代理IP
from lxml import etree
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36',
}
url = 'https://www.sogou.com/web?query=ip'
#proxies参数:请求设置代理
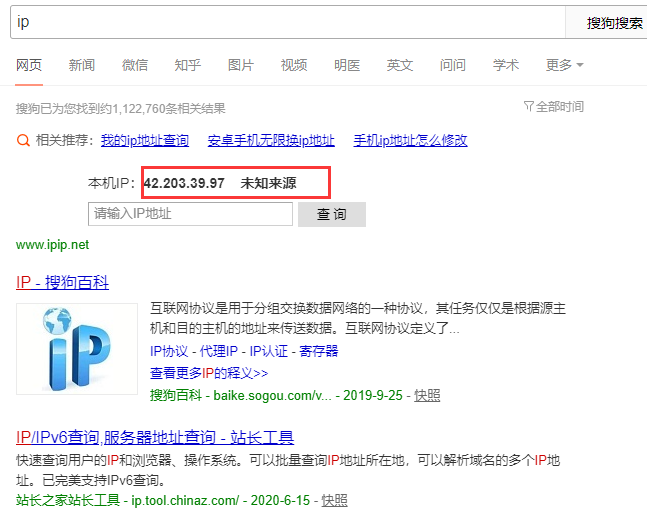
page_text = requests.get(url=url,headers=headers,proxies={'https':'42.203.39.97:12154'}).text
with open('./ip.html','w',encoding='utf-8') as fp:
fp.write(page_text)
6、打开生成的html文件查看IP信息
3、代理池构建
案例2:
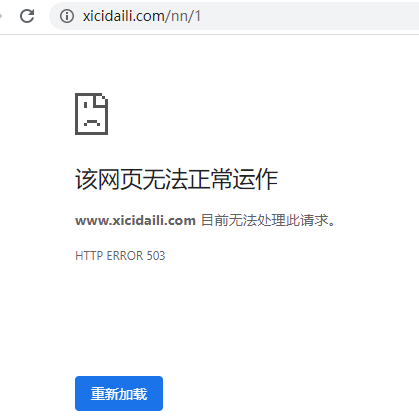
通过进行高频率数据访问爬取https://www.xicidaili.com/,结果本机IP被禁止访问,
from lxml import etree
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36',
}
#尝试发起高频请求,让对方服务器将本机ip禁掉
url = 'https://www.xicidaili.com/nn/%d'
ips = []
for page in range(1,30):
new_url = format(url%page)
page_text = requests.get(new_url,headers=headers).text
tree = etree.HTML(page_text)
#排除掉第一个tr标题标签属性
tr_list = tree.xpath('//*[@id="ip_list"]//tr')[1:]
for tr in tr_list:
ip = tr.xpath('./td[2]/text()')[0]
ips.append(ip)
print(len(ips)) #2900
#运行多次程序之后,发现本机ip已被禁掉,再次访问https://www.xicidaili.com/已经无法进行访问
解决方法:
使用代理池进行数据爬取次数限制破解
重新获取3个代理IP

构建一个代理池:大列表,需要装载多个不同的代理
from lxml import etree
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36',
}
proxy_list = [] #代理池
proxy_url = 'http://ip.11jsq.com/index.php/api/entry?method=proxyServer.generate_api_url&packid=1&fa=0&fetch_key=&groupid=0&qty=3&time=1&pro=&city=&port=1&format=html&ss=5&css=&dt=1&specialTxt=3&specialJson=&usertype=15'
page_text = requests.get(url=proxy_url,headers=headers).text
tree = etree.HTML(page_text)
ips_list = tree.xpath('//body//text()')
for ip in ips_list:
dic = {'https':ip}
proxy_list.append(dic)
print(proxy_list)
>>>
[{'https': '122.143.86.183:28803'}, {'https': '182.202.223.253:26008'}, {'https': '119.114.239.41:50519'}]
完整代码
import random
from lxml import etree
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36',
}
proxy_list = [] #代理池
proxy_url = 'http://ip.11jsq.com/index.php/api/entry?method=proxyServer.generate_api_url&packid=1&fa=0&fetch_key=&groupid=0&qty=3&time=1&pro=&city=&port=1&format=html&ss=5&css=&dt=1&specialTxt=3&specialJson=&usertype=15'
page_text = requests.get(url=proxy_url,headers=headers).text
tree = etree.HTML(page_text)
ips_list = tree.xpath('//body//text()')
for ip in ips_list:
dic = {'https':ip}
proxy_list.append(dic)
url = 'https://www.xicidaili.com/nn/%d'
ips = []
for page in range(1,5):
new_url = format(url%page)
page_text = requests.get(new_url,headers=headers,proxies=random.choice(proxy_list)).text
tree = etree.HTML(page_text)
tr_list = tree.xpath('//*[@id="ip_list"]//tr')[1:]
for tr in tr_list:
ip = tr.xpath('./td[2]/text()')[0]
ips.append(ip)
print(len(ips))
>>>400
windows也可对通过浏览器进行设置代理操作