1、requests作用:
-
就是一个基于网络请求的模块,可以用来模拟浏览器发请求。
-
环境安装:
- pip install requests
-
requests模块的使用流程:
- 指定一个字符串形式url
- 发起请求
- 获取响应数据
- 持久化存储
-
实现一个简易的网页采集器
- 爬取到任意关键字对应的页面源码数据
简单需求:爬取搜狗首页的页面源码数据
import requests
#指定一个字符串形式url
url = 'https://www.sogou.com/'
#发起请求
response = requests.get(url=url) #get返回一个响应对象
#获取响应数据
page_text = response.text #获取字符串形式的响应数据
#持久化存储
with open('./sougou.html','w',encoding='utf-8') as fp:
fp.write(page_text)
2、案例需求1:实现简易的网页采集器,爬取到任意关键字对应的页面源码数据
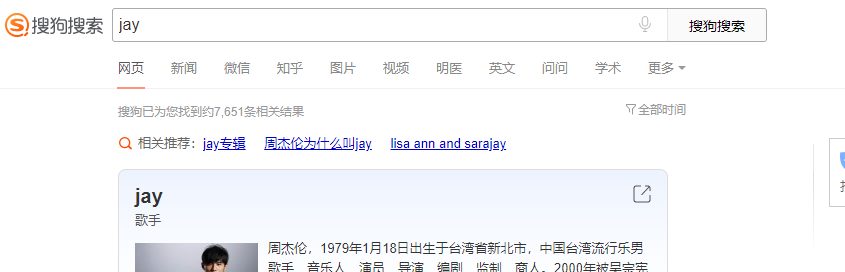
2.1过程1分析
import requests
url = 'https://www.sogou.com/web?query=jay'
response = requests.get(url=url)
page_text = response.text
with open('./jay.html','w',encoding='utf-8') as fp:
fp.write(page_text)

上述代码出现了问题:
- 出现了乱码问题
- 数据量级不对
2.2过程2分析
#解决乱码问题
url = 'https://www.sogou.com/web?query=jay'
response = requests.get(url=url)
# response.encoding#返回响应数据原始的编码格式
response.encoding = 'utf-8'
page_text = response.text
with open('./jay.html','w',encoding='utf-8') as fp:
fp.write(page_text)
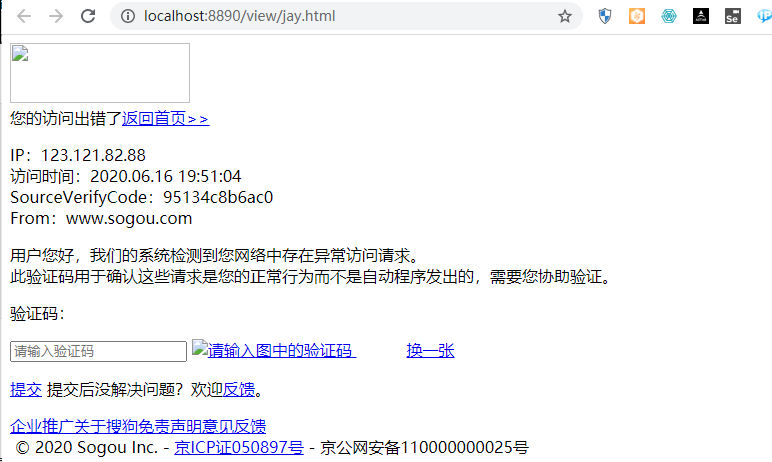
- 当前的请求被搜狗认定为是一个异常的请求
- 什么是异常的请求?
- 服务器端检测到该次请求不是基于浏览器访问。使用爬虫程序发起的请求就是异常的请求。
- User-Agent:
- 本身是请求头中的一个信息。
- 概念:请求载体的身份标识
- 请求载体:浏览器,爬虫程序
- 什么是异常的请求?
- 反爬机制:UA检测
- 对方服务器端会检测请求载体的身份标识,如果不是基于某一款浏览器的身份标识则认定为是一个异常请求,则不会响应会正常的数据。
- 反反爬策略:UA伪装
- 将爬虫程序发起的异常的请求载体标识伪装或者修改成某一款浏览器的身份标识即可
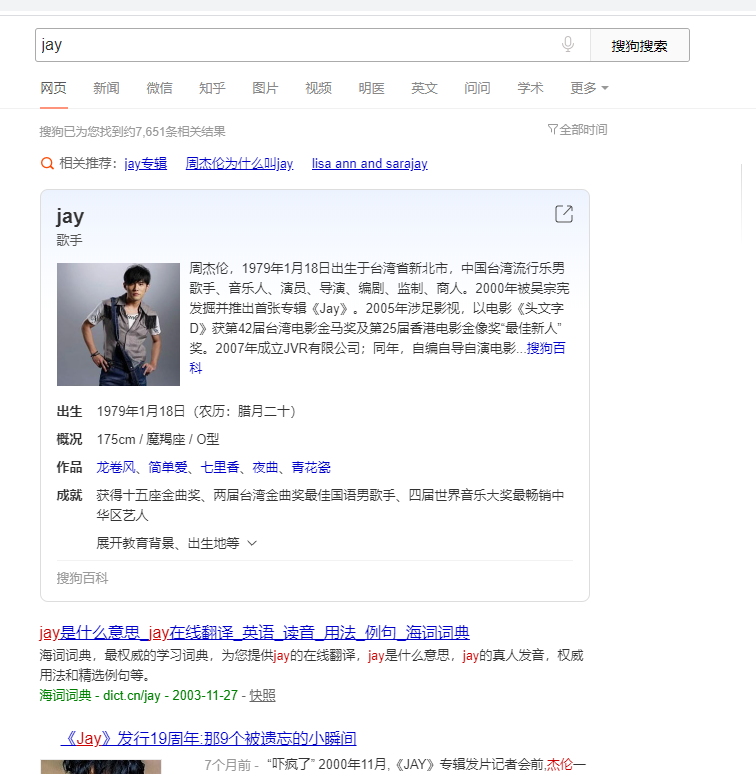
2.3正常拿到数据
加上 User-Agent:请求载体的身份标识
url = 'https://www.sogou.com/web?query=jay'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36
'
}
#UA伪装
response = requests.get(url=url,headers=headers)
# response.encoding#返回响应数据原始的编码格式
response.encoding = 'utf-8'
page_text = response.text
with open('./jay.html','w',encoding='utf-8') as fp:
fp.write(page_text)
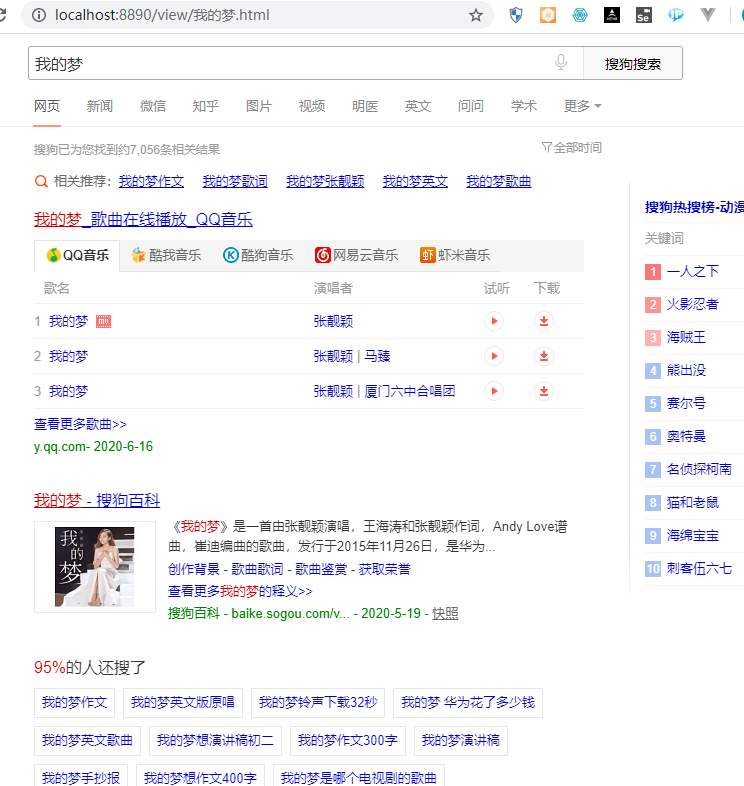
3、参数动态化
- 可以动态的给请求指定请求参数
key = input('enter a key word:')
#将请求参数封装成键值对
params = {
'query':key
}
url = 'https://www.sogou.com/web'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36
'
}
#参数动态化
response = requests.get(url=url,headers=headers,params=params)
# response.encoding#返回响应数据原始的编码格式
response.encoding = 'utf-8'
page_text = response.text
fileName = key+'.html'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
print(fileName,'爬取成功!!!')
>>>
enter a key word:我的梦
我的梦.html 爬取成功!!!
4、爬取动态加载的数据
- 所谓动态加载的数据是指不是通过浏览器地址栏的url请求到的数据。
- 如何检测我们爬取的数据是否为动态加载的数据?
- 基于抓包工具做局部搜索(在抓包工具中找到地址栏url对应的数据包,在其response这个选项卡下进行搜索爬取数据的关键字)
- 如何爬取动态加载的数据?
- 基于抓包工具做全局搜索,可以帮我们定位到动态加载的数据到底是存在于哪一个数据包中,定位到之后,就可以对该数据包的url进行请求发送捕获数据。
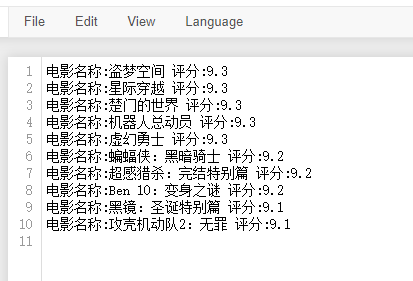
5、案例需求2:爬取豆瓣中前10名电影详情数据
- 当滚轮向下滑动的时候,会加载出更多的电影数据,说明当滚轮滑动到底部时,会发起一个ajax请求,该次请求会加载出更多的数据。

url = 'https://movie.douban.com/j/chart/top_list'
params = {
'type': '17',
'interval_id': '100:90',
'action': '',
'start': '0',
'limit': '10',
}
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'
}
#json()返回字典或者列表对象
data_list = requests.get(url=url,headers=headers,params=params).json()
for dic in data_list:
title = dic['title']
score = dic['score']
# print('电影名称:',title,' 评分:',score)
with open('./movie.txt','a+',encoding='utf-8') as f:
f.write(f'电影名称:{title} 评分:{score}
')
fp.close()
输出到文件中
- 动态加载数据的生成方式:
- ajax请求
- js
- 日后对一个陌生的网站进行数据爬取,在编码之前必须要做的一件事情是什么?
- 检测你要爬取的数据是否为动态加载的数据
- 如果不是动态加载数据就可以直接对地址栏的url发起请求爬取数据
- 如果是动态加载数据就需要基于抓包工具进行全局搜索爬取数据
- 检测你要爬取的数据是否为动态加载的数据
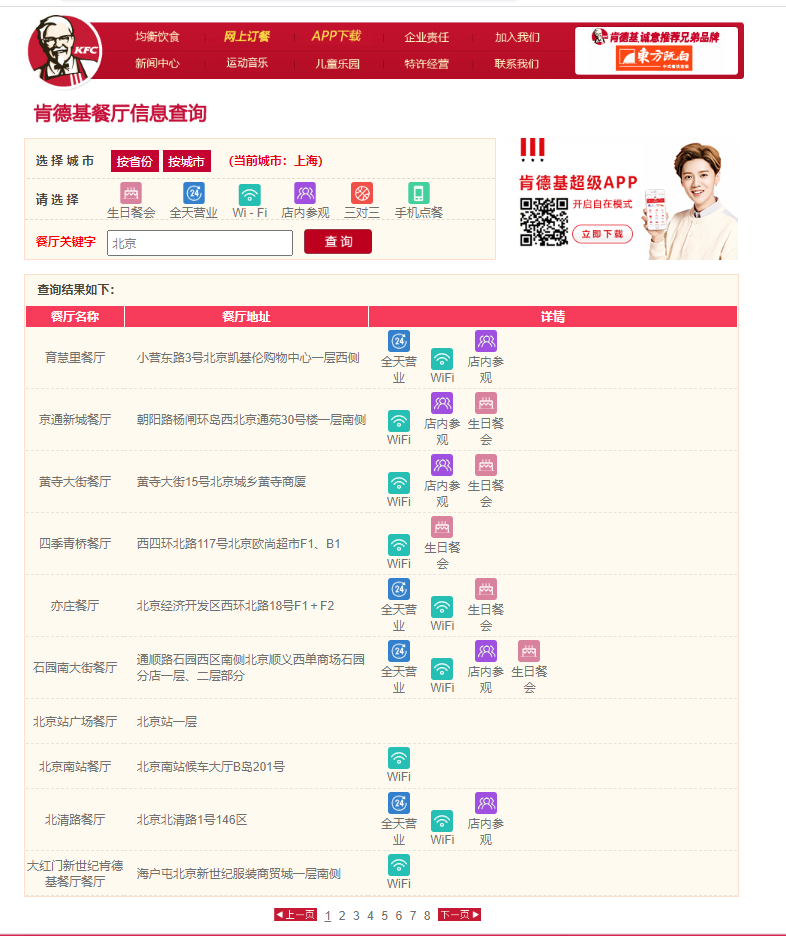
6、案例需求3:将北京所有肯德基餐厅的位置信息进行爬取:
数据爬取地址:http://www.kfc.com.cn/kfccda/storelist/index.aspx
import requests
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
city = input('enter a city name:')
# 获取3页数据
for page in range(4):
data = {
'cname': '',
'pid': '',
'keyword': city,
'pageIndex': str(page),
'pageSize': '10',
}
#参数动态化使用的是data参数
data_dict = requests.post(url=url,headers=headers,data=data).json()
for i in data_dict.get('Table1'):
storename = i.get('storeName')
addressDetail = i.get('addressDetail')
filename = 'KFC_address'
with open(f'./{filename}.txt','a+',encoding='utf-8') as f:
f.write(f'店名:{storename},地址:{addressDetail}
')
f.close()
print(filename,'爬取成功!!!')
>>>
enter a city name:北京
KFC_address 爬取成功!!!
输出到文件中

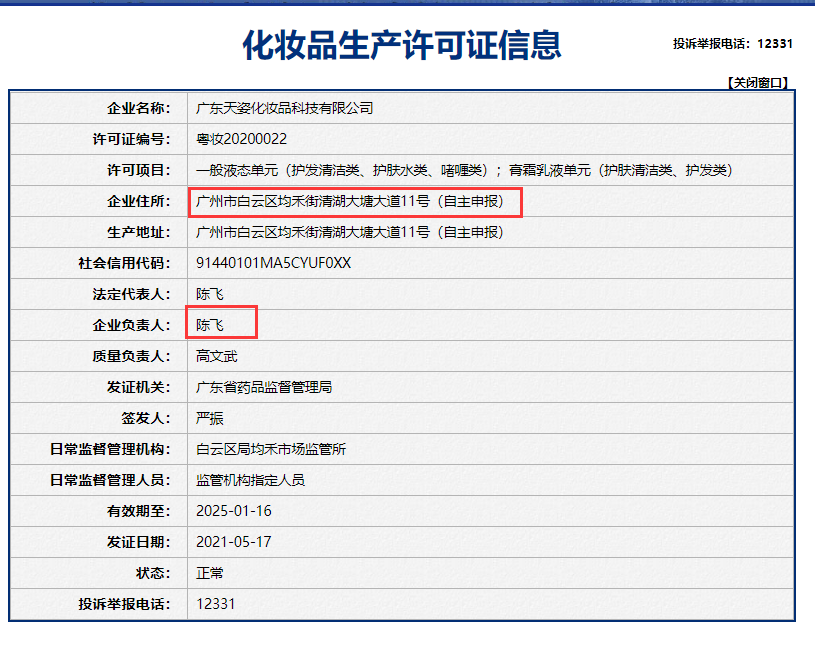
7、案例需求4:将所有企业的详情信息进行爬取保存
数据爬取地址:http://125.35.6.84:81/xk/
分析:
- 尝试着将某一家企业的详情数据爬取到,然后再把此操作作用到其他家企业爬取到所有企业的数据。
- 检测某一家企业详情数据是否为动态加载的数据
- 基于抓包工具实现局部搜索
- 结论:为动态加载数据
- 基于抓包工具实现局部搜索
- 基于抓包工具进行全局搜索定位动态加载数据的数据包,从数据包中提取url和请求参数
- url:http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById
- 请求方式:post
- 参数:id: ff83aff95c5541cdab5ca6e847514f88
- 通过对比不同企业的详情数据包的信息,发现请求的url,请求方式都一样,只有请求参数id的值不一样而已。

import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'
}
post_url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList'
fp = open('company_data.txt','w',encoding='utf-8')
#爬取两页数据
for page in range(1,3):
data = {
'on': 'true',
'page': str(page),
'pageSize': '15',
'productName': '',
'conditionType': '1',
'applyname': '',
'applysn':'',
}
json_data = requests.post(url=post_url,headers=headers,data=data).json()
for dic in json_data['list']:
company_id = dic['ID']
url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById'
data = {
'id':company_id
}
detail_json = requests.post(url=url,headers=headers,data=data).json()
per_name = detail_json['businessPerson']
addr = detail_json['epsAddress']
fp.write(f'企业负责人:{per_name},企业住所:{addr}
')
fp.close()
输出到文件

8、案例5:图片数据的爬取
两种方法:
- urllib
- requests
- urllib和requests的功能作用都几乎是一致。urllib是一个比较古老的网络请求模块,当requests问世后,就快速的替代了urllib。

爬取图片方式1
url = 'http://gss0.baidu.com/9vo3dSag_xI4khGko9WTAnF6hhy/zhidao/pic/item/3b292df5e0fe99257d8c844b34a85edf8db1712d.jpg'
#content返回二进制类型的响应数据
img_data = requests.get(url=url,headers=headers).content
with open('123.png','wb') as fp:
fp.write(img_data)
爬取图片方式2
from urllib import request
url = 'http://gss0.baidu.com/9vo3dSag_xI4khGko9WTAnF6hhy/zhidao/pic/item/3b292df5e0fe99257d8c844b34a85edf8db1712d.jpg'
request.urlretrieve(url=url,filename='./456.png')

图片两种爬取方式的区别:
- 方式1是可以进行UA伪装
- 方式2无法进行UA伪装