ID3决策树
ID3决策树分类的根据是样本集分类前后的信息增益。
假设我们有一个样本集,里面每个样本都有自己的分类结果。
而信息熵可以理解为:“样本集中分类结果的平均不确定性”,俗称信息的纯度。
即熵值越大,不确定性也越大。
不确定性计算公式
假设样本集中有多种分类结果,里面某一种结果的“不确定性”计算公式如下
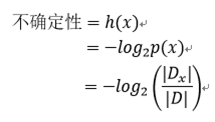
其中
x:为按照某特征分类后的第x种分类结果
p(x):表示该分类结果样本集在总样本集中的所占比例。
Dx:表示样本结果为x的样本数量。
D:表示样本的总数量
可看出某一种分类结果在总样本集中所占比例越少,其“不确定性”也越大。
信息熵计算公式
样本集的熵,就是他所有分类结果的平均不确定性,即所有分类结果不确定性求期望。公式如下:
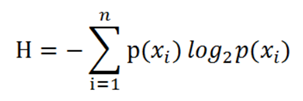
说白了,就是算出整个样本集中每一个分类结果的不确定性,然后求一个期望值,就作为这整个样本集的熵值。
信息熵增益
熵越大表示事件变数越多,我们要做的就是每一次分类都让事件集变的最稳定。所以当我们选择某一个特征进行分类后,样本集分类前后的熵的减小量就是熵的增益。
ID3算法的核心就是计算按照每一种特征分类后,其熵差大小,选择能使熵差最大的特征作为分类特征。
分类前的熵就是集群整个的熵。
分类后的熵其实是所有分类后的小样本集的熵的期望。
ID3算法缺陷
1、抗噪声性差,如果数据样本数量太少或噪声太大,就会产生过拟合的问题。
样本少,其树的构成基本上就是为少数样本量身定做的树,如果噪声太大,或样本少且有噪声的话,很多树枝都是噪声拟合出来的。
2、在选择最优特征时,很容易倾向于选择“特征值种类较多”的特征,作为分类特征。
我们举个极端点的例子,假设有100个样本集,现在有一个特征其数值种类也是100,如果按该特征分类,就能把这个样本集分成100份,每份一个样本。在用ID3算法做决策树时,肯定会选择这个特征作为第一个最优特征,因为这个特征分出来的样本集每一个纯度都是最高。
3、无法处理特征值为连续型数据的特征。(不过可以考虑把连续型数据转化成离散型数据)
即,可以处理像性别特征、boolen特征等离散型特征,但没法处理特征值在某个区间内可以任意取值的特征,如身高特征、年龄特征。
C4.5决策树
针对上面说的ID3算法的第二个缺点“最优特征选择倾向于特征种类较多的特征”。
我们先来看下特征种类较多时,分类会发生什么。
假设都是均分100个样本,
特征值有2种的特征会把样本集分成50和50.
特征值为4种的特征会把样本集分成25、25,25,25.
可见特征值越多,就会产生越多的“小数目”样本集,而小数目样本集在分类效果上是不如大样本集好的(如过拟合、抗噪差等问题),所以对于某特征分类后会产生“小数目”样本集的分类后的熵,我们需要有一个惩罚值,即:分类后产生的样本集越小,它的熵值也要惩罚性的增大。
这样虽然ID3算法中会因为很多分类后的小数量样本集而产生低值的期望熵,但做惩罚值处理后,熵值就会平衡性的增大。
信息增益率
在C4.5中惩罚小数量样本集的做法是,
在根据某特征分类,并计算出分类前后的熵差后,再计算该特征的惩罚值,用该分类特征的熵差除以惩罚值得出“信息增益率”,使信息增益率越大的特征,就是最优特征。即:

其中惩罚值实际上就是“信息熵”,只不过这里的信息指的不是计算信息增益时“样本集中分类结果的平均不确定性”,而是“总样本集中分类后子样本集数目的平均不确定性”,即:
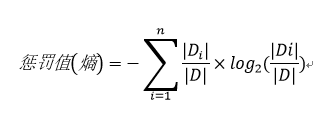
其中:
D:分类前的总样本数量。
i:按某特征分类后样本子集序号。
Di:按某特征分类后的第i个子集的数量。
由此看出,样本数量越少,惩罚值越大,相除后的信息增益率也就越小,依此做到了一定的平衡,由于“惩罚”了小样本数量集,其由于数量少带来信息增益抗噪性差的问题也得到一定程度的解决。
这就是C4.5算法最大的好处,解决了ID3算法第二个缺陷,缓解了ID3算法的第一个缺陷。
不过ID3算法的第三个不能处理连续型特征数据的问题。C4.5算法本身也不能直接处理连续数据。
另外C4.5和ID3算法还有一个特点,这俩算法的根本其实都要计算信息增益,而信息增益的一个大前提就是要先进行分类,然后才能计算增益,所以每计算一次增益也就代表进行了一次分类,分类用了的特征接下来就不能再用了,所以ID3和C4.5算法在分类时会不断消耗特征。
CART决策树
简单来讲就是,有一个类似于熵的指标叫Gini指数,其代表了分类结果的不确定性,所以自然是越小越好。
每次分类前计算分类前后的Gini指数,求差得出“Gini指数增益”,能使Gini指数增益最大的特征就是最优特征。
需要注意的是,CART算法分类时,即使特征有大于两个特征值,也还是会把样本集分成两类,最后形成的是标准二叉树。
Gini指数
首先计算分类前样本集的Gini指数,Gini指数想表达的东西和信息熵类似,都是想表达样本集分类结果的不确定性,Gini指数或熵越大,表示样本集分类结果不确定性也越大。
假设样本集数量为D,分类结果有n种,Dk表示总样本集中分类结果为第k种的样本数量。
那么从总样本集中选出分类结果为k的样本的概率为:

选出分类结果为k的样本的不确定性(即选出分类不为k的样本概率)为:
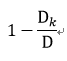
而总样本集的分类结果不确定性,就是计算n种分类结果的不确定性,然后取期望:

这个公式就是样本集的Gini指数,用于表达样本集分类结果的不确定性,Gini指数越大样本集越不确定,化简后得:
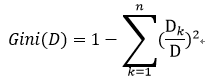
按照某特征分类后的Gini指数为,分类后各样本集Gini指数求期望,
假设分类前总样本集数量为D,按特征分类后得到两堆样本集数量分别为S1和S2(由于CART算法生成二叉树的特性,所以只能分成两堆),则样本集分类后的Gini指数为:
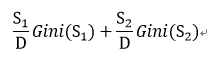
如果特征值大于两个,则列出所有可能的分类情况,依次分类并计算各分类后的Gini指数,选择分类后Gini指数最小的分类情况作为特征的分类方法。
如,特征有a,b,c三个特征值,
则可能的分类方法有:(a,(b,c)),(b,(a,c)),(c,(a,b))
假设(b,(a,c))这种分类方式分类后的Gini指数最小,则按照特征值为b的分为第一个树枝,特征值为a或c的分为第二个树枝,
第一个树枝里该特征只有b特征值,则后续分类时不需要再考虑该特征。
第二个树枝里该特征中还有a和c两种特征值,需要注意的是“后续分类时还是要考虑该特征,且特征值为a和c”。
Gini指数增益
最终,样本集D,按照某特征分类出S1样本集和S2样本集后,其Gini指数增益为:
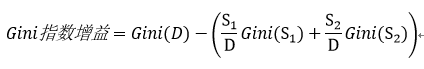
选取能使Gini指数增益最大的特征分类作为最优特征分类。
CART和C4.5算法区别
1.C4.5本质上还是基于信息熵得出的信息增益比,而CART算法的分类树是基于Gini指数得出的Gini指数增益。
2.CART是一颗二叉树,而C4.5算法没有这个特点。这是因为在进行特征分类上,C4.5算法每次选择一种特征进行分类后,每一个特征值都是一个树枝。而CART算法每次分类会把特征的所有特征值分成两堆,符合A堆里面的特征值的样本算A分支,符合B堆特征值的样本算B特征。
3.基于第二点不同,我们可看出C4.5算法每选择一个特征按各个特征值分类后,接下来的分类就不会再考虑该特征了(因为该特征已按特征值彻底划分完了)。而CART算法是把特征值分成两堆,假设有abcd四个特征,经过Gini增益计算后,ab为1堆,cd为2堆,那么按照此分类后1堆和2堆该特征都没有被完全划分,1堆样本还能对a和b特征值再进行划分。
所以CART算法的特征在分类过程中可能重复出现,而C4.5只能出现一次。
连续型特征离散化
连续型数据离散化的方法很多,最易懂的就是凭经验离散化,
比如一批样本集里有身高特征(cm),样本的数值有:162,164,165,166,168,170,173,180
这个时候我们就可以凭借经验或者想要统计的结果,对这组连续数据划分一个离散范围,如设定小于165的是一类,165到170的是一类,大于170的是一类,这样就把连续数据离散化成一个范围判断了。
但凭借经验进行范围划分明显不靠谱,
我们可以利用ID3、C4.5、CART这些算法,将连续数据离散化。
简单来讲思路就是:
依次设立划分点,然后数值小于该划分点的数据分为一类,大于的分为另一类。
分别计算根据各个划分点分类前后的信息增益(ID3)或信息增益率(C4.5)或Gini指数增益(CART),选出使得增益达到最大的划分点作为分类特征值。
至于划分点的选择,一般是将所有连续数值从小到大排序,每两点间取平均数建立一次划分点进行分类,并计算信息增益或信息增益率。