CNN原理和结构
观点提出
关于照片的三种观点引出了CNN的作用。
- 局部性:某一特征只出现在一张image的局部位置中。
- 相同性: 同一特征重复出现。例如鸟的羽毛。
- 不变性:subsampling下图片性质不变。类似于图片压缩。
相比与Fully Connected,减少了权重数目。
组成结构
卷积层
使用一个集合的滤波器在输入数据上滑动,得到内积,形成K张二维的激活图,作为该层卷积层的输出。
- 每类的滤波器寻找一种特征进行激活。
- 一个滤波器的高度必须与输入数据体的深度一致。
- 卷积层的输出深度是一个超参数,它与使用的滤波器的数量一致。
例如:
一张28 * 28 * 3的照片,(W_1=28, H_1=28, D_1=3),故感受野的尺寸可以是 5 * 5 * 3的。
若有16个滤波器同时运算,则输出层数为16。
4个超参数:滤波器数量(K),空间尺寸(F),滑动步长(S),零填充数量(P)。
一次过滤后输出体的尺寸 (W_2 * H_2 * D_2)
[W_2 = frac{W_1 - F + 2P}{S} + 1 quad quad H_2 = frac{H_1 - F + 2P}{S} + 1
]
步长必须是整数,零填充数量$ frac{F - step}{2}$
参数共享:相同的滤波器可以检测出不同位置的相同特征,可以有效减少参数。
小滤波器的有效性:多个卷积层首先与非线性激活层交替的结构,比单一卷积层的结构更能提取出深层的特征;小滤波器组合使用参数更少,但不足的是反向更新参数时,可能会使用更多的内存。
池化层
逐渐降低数据体的空间尺寸,这样能够减少网络中参数的数量。
2个超参数:空间尺寸(F),滑动步长(S)。
最常用的池化层形式是尺寸为2*2的窗口,滑动步长为2,对图像进行采样,将其中75%的激活信息都丢掉,只选择其中最大的保留,以此去掉一些噪声信息。
平均池化一般放在CNN的最后一层。
CNN模块等
参数列表
卷积层参数:
in_channels: 当图片为RGB时为3,否则为1。对应的是输入数据体的深度。out_channels:输出数据体的深度。kernel_size:滤波器的大小,单位pixel。stride:步长padding:=0表示四周不进行0填充,=1表示进行1个像素点的填充。
池化层参数:
kernel_size:=2表示 2*2的小矩阵中选max。
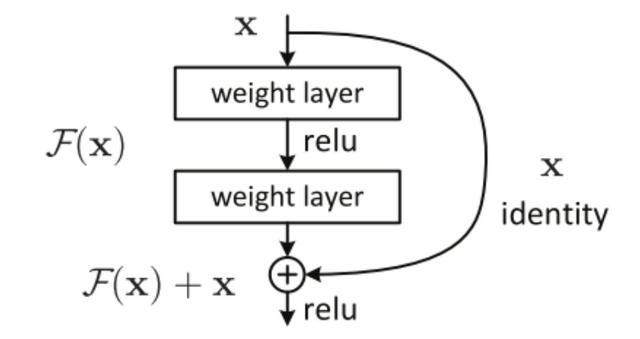
CNN模型:ResNet
若将输入设为X,将某一有参网络层设为H,那么以X为输入的此层的输出将为H(X)。一般的CNN网络如Alexnet/VGG等会直接通过训练学习出参数函数H的表达,从而直接学习X -> H(X)。
而残差学习则是致力于使用多个有参网络层来学习输入、输出之间的参差即H(X) - X即学习X -> (H(X) - X) + X。其中X这一部分为直接的identity mapping,而H(X) - X则为有参网络层要学习的输入输出间残差。
class CNN(nn.Module):
..
def forward(self, x):
residual = x
# 代入层结构
if self.downsample is not None:
residual = self.downsample(x)
out += residual
#...