1. 文件操作及相关函数
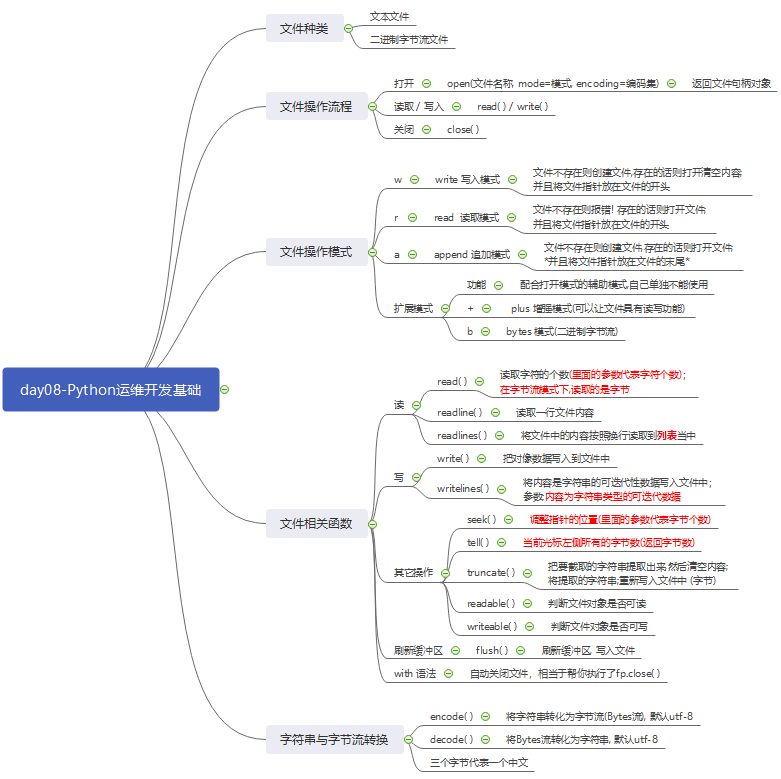


# ### 文件操作 """ fp = open("文件名称",mode=模式,encoding=编码集) fp 文件io对象 (文件句柄) i : input 输入 o : output 输出 """ # (1) 文件的写入操作 # 打开文件 fp = open("ceshi1.txt",mode="w",encoding="utf-8")# 打开冰箱 # 写入内容 fp.write("把大象塞进去") # 把大象放进去 # 关闭文件 fp.close()# 关上冰箱 # (2) 文件的读取操作 # 打开文件 fp = open("ceshi1.txt",mode="r",encoding="utf-8") # 读取内容 res = fp.read() # 关闭文件 fp.close() print(res) # (3) 转化成二进制字节流 # 将字符串和字节流(Bytes流)类型进行转换 (参数写成转化的字符编码格式) #encode() 编码 将字符串转化为字节流(Bytes流) #decode() 解码 将Bytes流转化为字符串 # encode strvar = "我爱你" res = strvar.encode("utf-8") print(res) # decode strnew = res.decode("utf-8") print(strnew) # 三个字节代表一个中文 res = b"xe7x88xb1".decode() print(res) # (4) 写入字节流 (不要指定字符编码encoding) fp = open("ceshi2.txt",mode="wb") str_bytes = "我爱你,亲爱你菇凉".encode("utf-8") fp.write(str_bytes) fp.close() # (5) 读取字节流 (不要指定字符编码encoding) fp = open("ceshi2.txt",mode="rb") res = fp.read() fp.close() print(res) content = res.decode("utf-8") print(content) # 复制图片操作 (图片,音乐,视频 ... 二进制字节流模式) # 读取旧图片 fp = open("集合.png",mode="rb") str_bytes = fp.read() fp.close() # 创建新图片 fp = open("集合2.png",mode="wb") fp.write(str_bytes) fp.close()
# ### 文件的扩展模式 + # (utf-8编码格式下 默认一个中文三个字节 一个英文或符号 占用一个字节) #read() 功能: 读取字符的个数(里面的参数代表字符个数) #seek() 功能: 调整指针的位置(里面的参数代表字节个数) # seek(0) 把文件指针移动到行首 # seek(0,2) 把文件指针移动到末尾 #tell() 功能: 当前光标左侧所有的字节数(返回字节数) # r+ 先读后写 """ fp = open("ceshi3.txt",mode="r+",encoding="utf-8") res = fp.read() print(res) fp.write("123") # 重新读取 fp.seek(0) # 把文件指针调整到开头 res = fp.read() print(res) fp.close() """ # r+ 先写后读 """ fp = open("ceshi3.txt",mode="r+",encoding="utf-8") fp.seek(0,2) fp.write("123") # 重新调整光标位置,移动到开头 fp.seek(0) res = fp.read() print(res) fp.close() """ # w+ 可写可读 """ fp = open("ceshi4.txt",mode="w+",encoding="utf-8") fp.write("色即是空,空即是色,受想行识,亦复如是") # 重新调整光标位置,移动到开头 fp.seek(0) res = fp.read() print(res) fp.close() """ """ # a+ 可写可读 [a模式下,在追加内容时,会强制把光标移动到末尾进行写入] fp = open("ceshi5.txt",mode="a+",encoding="utf-8") fp.write("无眼耳鼻舌身意") # 重新调整光标位置,移动到开头 fp.seek(0) res = fp.read() print(res) fp.close() """ # read seek tell 三个方法使用 """ fp = open("ceshi5.txt",mode="r+",encoding="utf-8") fp.read(3) # 当前光标左侧所有的字节数 res = fp.tell() print(res) # 移动光标到4个字节的位置 fp.seek(4) res = fp.tell() print(res) fp.close() """ # 注意点: 如果是中文字符串,移动seek时候,如果移动到一半,读取时会发生报错; fp = open("ceshi5.txt",mode="r+",encoding="utf-8") res = fp.read(2) print(res) res = fp.tell() print(res) #6 # 一个中文3个字节,但是移动了2个,会出现报错 """ res = fp.seek(2) res = fp.read() print(res) error """ fp.close() # with 语法 : 可以自动实现关闭文件操作 """ 语法: as 起别名 with open("ceshi5.txt",mode="r+",encoding="utf-8") as fp: 逻辑 """ with open(""ceshi5.txt",mode="r+",encoding="utf-8") as fp: res = fp.read() print(res) # 改写复制图片操作 with open("集合.png",mode="rb") as fp1 , open("集合3.png",mode="wb") as fp2: # 读取内容 str_bytes = fp1.read() # 写入内容 fp2.write(str_bytes)
# 刷新缓冲区 flush # 当文件关闭的时候自动刷新缓冲区 # 当整个程序运行结束的时候自动刷新缓冲区 # 当缓冲区写满了 会自动刷新缓冲区 # 手动刷新缓冲区 """ fp = open("ceshi6.txt",mode="w",encoding="utf-8") fp.write("abc") # flush 可以瞬间刷新缓冲区,把内容直接写入到文件中 fp.flush() while True: pass fp.close() """ #readline() 功能: 读取一行文件内容 ''' with open("ceshi7.txt",mode="r+",encoding="utf-8") as fp: # (1)读取一行 # res = fp.readline() # print(res) # (2)读取所有 """ res = fp.readline() while res: print(res) # 在读取一行 res = fp.readline() """ # (3)readline(字符的个数) """ 参数值 小于 当前行总个数 ,按照实际参数值进行读取 参数值 大于 当前行总个数 ,按照当前行进行读取; """ res = fp.readline(200000) print(res) ''' #readlines() 功能:将文件中的内容按照换行读取到列表当中 """ lst_new = [] with open("ceshi7.txt",mode="r+",encoding="utf-8") as fp: lst = fp.readlines() print(lst) # 循环把两边的空白符去掉 for i in lst: res = i.strip() # 把处理好的结果放到新列表中 lst_new.append(res) print(lst_new) """ #writelines() 功能:将内容是字符串的可迭代性数据写入文件中 参数:内容为字符串类型的可迭代数据 """ (1) 字符串 (2) 可迭代性数据: (容器类型数据,迭代器,range对象) """ """ with open("ceshi8.txt",mode="w+",encoding="utf-8") as fp: lst = ["三世诸佛 ","依般若波罗蜜多故 ","得阿耨多罗三藐三菩提 "] # strvar = "abcedf" fp.writelines(lst) """ #truncate() 功能: 把要截取的字符串提取出来,然后清空内容将提取的字符串重新写入文件中 (字节) """ with open("ceshi9.txt",mode="r+",encoding="utf-8") as fp: fp.truncate(3) """ fp = open("ceshi9.txt",mode="r",encoding="utf-8") #readable() 功能: 判断文件对象是否可读 res = fp.readable() print(res) #writable() 功能: 判断文件对象是否可写 res = fp.writable() print(res) # 文件的io对象 是一个可迭代对象: 默认是一行一行读取 for i in fp: print(i) """ read() readline() 一般情况下都是字符 [read在字节流模式下,读取的是字节] seek() truncate() 读取的是字节 """
2. 函数及普通与默认形参、普通实参与关键字实参

# ### 函数 # (1) 函数的定义 : 功能 (包裹一部分代码 实现某一个功能 达成某一个目的) # (3) 函数的基本格式: """ # 定义一个函数 def 函数名(): code1 code2 # 调用函数 函数名() """ # 定义一个函数 def func(): print("这是一个函数") # 调用函数 func() # (4)函数命名 """ 函数命名 字母数字下划线,首字符不能位数字 严格区分大小写,且不能使用关键字 函数命名有意义,且不能使用中文哦 驼峰命名法: (1) 大驼峰命名法: 每个单词首字符大小 (class 类) (2) 小驼峰命名法: 除了第一个单词的首字符小写之外,剩下单词首字符都大写 (函数 ) mycar => MyCar 大驼峰 mycar => myCar 小驼峰 mycar => my_car (推荐这个方法命名函数) """ # 定义一个函数 def cheng_fa_biao_99(): for i in range(1,10): for j in range(1,i+1): # print("%d*%d=%2d " % (i,j,i*j),end="") print("{:d}*{:d}={:2d} ".format(i,j,i*j),end="") print() # (2)函数特点: """可以反复调用,提高代码的复用性,提高开发效率,便于维护管理""" # 调用函数 # cheng_fa_biao_99() # cheng_fa_biao_99() # cheng_fa_biao_99() # cheng_fa_biao_99() # cheng_fa_biao_99() # cheng_fa_biao_99() # cheng_fa_biao_99() # cheng_fa_biao_99() # cheng_fa_biao_99() # cheng_fa_biao_99() for i in range(10): cheng_fa_biao_99()
# ### 函数的参数 : (函数运算时需要的值) """ 参数:两大类 (形参 , 实参) 形参: 形式参数 (普通形参 , 默认形参 , 普通收集参数 , 命名关键字参数 , 关键字收集参数) 实参: 实际参数 (普通实参 , 关键字实参) 形参 和 实参 要一一对应 形参在函数的定义处 实参在函数的调用处 普通形参 别名也叫 位置形参 """ # (1)普通形参 # 函数的定义处 """hang , lie 是普通形参""" def small_star(hang,lie): i = 0 while i<hang: j = 0 while j<lie: print("*",end="") j+=1 print() i+=1 # 函数的调用处 """10 和 10 在函数的调用处是实参""" small_star(10,10) small_star(5,8) # (2)默认形参 # 函数的定义处 """hang=10,lie=10 叫做默认形参""" """ 如果给与实际参数,那么使用实际参数 如果没有给与实际参数,那么使用默认参数 """ def small_star(hang=10,lie=10): i = 0 while i<hang: j = 0 while j<lie: print("*",end="") j+=1 print() i+=1 # 函数的调用处 small_star() # (3) 普通形参 + 默认形参 [普通形参 必须写在 默认形参的前面] """hang 普通形参 lie 默认形参""" def small_star(hang,lie=10): i = 0 while i<hang: j = 0 while j<lie: print("*",end="") j+=1 print() i+=1 small_star(6,2) small_star(6) # (4) 关键字实参 [在函数的调用处] """ (1) 关键字实参的顺序可以任意调整 (2) 定义时是普通形参,调用时用的是关键字实参,那么当前形参后面的所有参数都需要使用关键字实参; """ def small_star(hang,a,b,c,lie=10): i = 0 while i<hang: j = 0 while j<lie: print("*",end="") j+=1 print() i+=1 # small_star(hang=7,lie=3) # small_star(lie=3,hang=7) small_star(3,a=3,b=4,c=5,lie=8) small_star(3,a=3,b=4,c=5) small_star(3,c=5,b=4,a=3)
day08