Chapter 7 Beyond the Fundamentals of Querying
window function是什么呢?就是你SELECT出来一个结果集,然后对于每一行,你都想给它对应一个标量(a scalar),而这个标量是通过a subset of rows计算得到的,而这个a subset of the rows其实就是你得到的结果集里面的一个subset(子集)。所以说就是把每一行都对应a subset of the rows,而这个对应关系通过OVER指定。举个例子:
SELECT empid, ordermonth, val,
SUM(val) OVER(PARTITION BY empid
ORDER BY ordermonth
ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW) AS runval
FROM Sales.EmpOrders;
结果:

讲解一下。OVER子句里面有三个部分:partitioning, ordering, and framing。partitioning就是PARTITION BY,其实就是分组,类似GROUP BY,如果不指定PARTITION BY,那么每行的对应就是整个结果集。ordering对应ORDER BY,但这里的ORDER BY跟数据展示没关系,它只是为了这个window函数服务的,也就是有些具体的计算需要根据顺序来计算。最后的ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW对应framing,UNBOUNDED PRECEDING表示分组的开始。所以说,比如对于上面的empid = 1的那几行,runval是根据ordermonth不断累积的。
Ranking Window Functions:
SELECT orderid, custid, val,
ROW_NUMBER() OVER(ORDER BY val) AS rownum,
RANK() OVER(ORDER BY val) AS rank,
DENSE_RANK() OVER(ORDER BY val) AS dense_rank,
NTILE(10) OVER(ORDER BY val) AS ntile
FROM Sales.OrderValues
ORDER BY val;
结果:
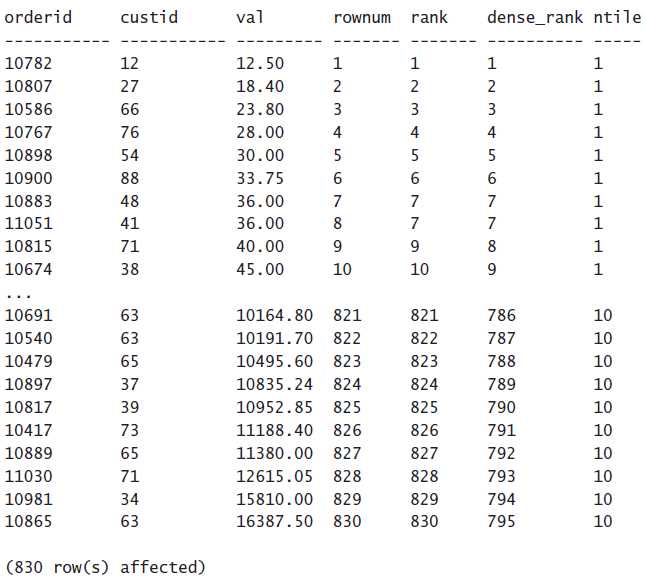
注意上面的val列里面有两行都为36,那么这时候ROW_NUMBER会给他们分配不同的编号。但是RANK和DENSE_RANK会给他们分配相同的编号,rank编号为9的意思是有8行的val比这行的val要小,dense rank为9的意思是有distinct的8行的val比这行的val要小。
NTILE(10)意思就是把结果分成十组,因为一共有830行,所以每组有83行。
注意,SELECT中如果用了DISTINCT,那么DISTINCT是在window函数之后进行的,如果你同时用了DISTINCT和ROW_NUMBER,那么你还不如不要这个DISTINCT。
Offset Window Functions:
先举个栗子:
SELECT custid, orderid, val,
LAG(val) OVER(PARTITION BY custid
ORDER BY orderdate, orderid) AS prevval,
LEAD(val) OVER(PARTITION BY custid
ORDER BY orderdate, orderid) AS nextval
FROM Sales.OrderValues;
结果:

讲解一下:PARTITION BY custid就相当于把范围定在custid是一样的这些行,LAG就是取当前行的前一行,LEAD就是取当前行的后一行,因为前后这个概念需要顺序作为前提,所以有个ORDER BY。其实LAG和LEAD还有两个可选参数,比如LAG(val, 3, 0)的意思就是,取向后的第三行,如果没有这样一行,就返回0。默认是LAG(column,1,NULL)。
然后是FIRST_VALUE和LAST_VALUE的例子:
SELECT custid, orderid, val,
FIRST_VALUE(val) OVER(PARTITION BY custid
ORDER BY orderdate, orderid
ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW) AS firstval,
LAST_VALUE(val) OVER(PARTITION BY custid
ORDER BY orderdate, orderid
ROWS BETWEEN CURRENT ROW
AND UNBOUNDED FOLLOWING) AS lastval
FROM Sales.OrderValues
ORDER BY custid, orderdate, orderid;
结果:

讲解一下:以FIRST_VALUE为例,其实就是返回这个分组中某个范围里的第一行,而那个名叫ROWS的window frame unit,我的理解就是继续缩小范围,比如ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW意思就是把范围定在分组的开始到当前行,ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING就是把范围定在当前行到分组的结束。如果不指定这样一个window frame unit,默认的范围的右边界是当前行。而且作者说应当显示指定一个window frame unit。
Aggregate Window Functions:
在SQL Server2012之前,window aggregate functions只支持PARTITION,举个例子:
SELECT orderid, custid, val,
SUM(val) OVER() AS totalvalue,
SUM(val) OVER(PARTITION BY custid) AS custtotalvalue
FROM Sales.OrderValues;
结果:

之前讲过,如果你不指定PARTITION那么范围就是整个结果集。当然,一般都会用window function的值和当前值做一个计算,比如:
SELECT orderid, custid, val,
100. * val / SUM(val) OVER() AS pctall,
100. * val / SUM(val) OVER(PARTITION BY custid) AS pctcust
FROM Sales.OrderValues;
从SQL Server 2012开始,聚合函数支持ordering和framing,例子参考这一章最开始的那个例子。其中的framing部分可以用很多种变化,比如ROWS BETWEEN 2 PRECEDING AND 1 FOLLOWING意思就是把范围缩小到当前行向前的两行和向后的一行之间。
考虑以下SQL:
SELECT empid, custid, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY empid, custid
UNION ALL
SELECT empid, NULL, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY empid
UNION ALL
SELECT NULL, custid, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY custid
UNION ALL
SELECT NULL, NULL, SUM(qty) AS sumqty
FROM dbo.Orders;
结果:

我们定义,上面被UNION ALL的四个query分别定义了四个grouping sets:(empid, custid)、(empid)、(custid),以及一个空的 grouping set: ()。但是你这么写很不好,第一是代码很长,第二是性能很差。咋整?用下面这种语法:
SELECT empid, custid, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY
GROUPING SETS
(
(empid, custid),
(empid),
(custid),
()
);
这种语法在逻辑上跟上面那个是一样的。但是SQL Server会做优化,提升性能。
还可以用CUBE,同构CUBE你可以得到基于输入参数的所有可能的grouping sets,比如CUBE(a, b, c)就相当于GROUPING SETS( (a, b, c), (a, b), (a, c), (b, c), (a), (b), (c), () )
语法如下:
SELECT empid, custid, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY CUBE(empid, custid);
ROLLUP类似,比如ROLLUP(a, b, c)就等于GROUPING SETS( (a, b, c), (a, b), (a), () )
有这么一个函数GROUPING:
SELECT
GROUPING(empid) AS grpemp,
GROUPING(custid) AS grpcust,
empid, custid, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY CUBE(empid, custid);
结果:

比如GROUPING(empid)的意思就是:当前这一行,如果empid是作为grouping set中的一员的话,就返回0,否则返回1。
还有个类似的函数GROUPING_ID,它可以接受所有你用在grouping sets里面的元素作为参数,然后返回一个整数(用二进制来看),每一位都代表一个你的元素,0代表是当前grouping set一员,1代表不是。比如你GROUPING_ID(a, b, c, d),如果当前的分组是(a,c)那么就返回0101(二进制)。