JAVA只提供了指定分割符等最基本的数据读入功能,而其他常见功能都需要自己从底层去实现,比如:按列名读入指定列、指定列的次序、指定数据类型、无分割符等等。JAVA实现这类功能虽然不难,但代码很繁琐,很容易出错。
使用集算器来辅助Java编程,这些问题都不需要自己写代码解决。下面我们通过例子来看一下具体作法。
文本文件data.txt是tab分割的文本文件,有30个列,第一行是具有业务意义的列名,现在需要按列名读入这几列:ID、x1Shift、x2Shift、radio,并按业务公式“((x1Shift+x2Shift)/2)*radio”计算出新列value。文件的前几行前几列如下 :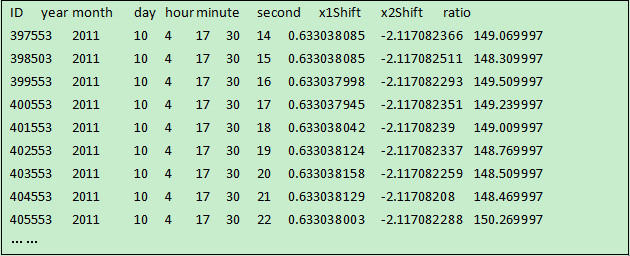
用JAVA解决时,我们必须将30个列都拆分出来,然后用下标引用特定的列进行计算,如果公式较多,计算较复杂,则出错的概率很大。为了减少误写的情况,我们只能用对象来存储每一条数据,并给每个字段赋予业务名称,再按业务名称进行公式计算。
集算器可以帮助JAVA避免这些麻烦,代码如下:

A1:函数import用来读入文件,但并非将30个列都读入内存,而是按列名读入指定列。参数选项@t表示将第一行读为列名。这一步的计算结果如下:

A2:直接按照业务名进行计算,计算结果如下:

实际使用中,上述计算结果有时要输出到文件中,使用这句代码可以实现这个目的:=file(“E:\result.txt”).export@t(A2.new(ID,value)),这表示将ID和value这两列写入文件result.txt,文件内容如下:

如果需要将计算结果传回JAVA继续使用,只需在集算器中书写代码:result A2.new(ID,value)),这表示将ID和result这两列通过JDBC接口返回JAVA,数据类型是resultSet。之后只需在JAVA代码中通过JDBC调用集算器脚本即可获得结果,代码如下。
//建立esProc jdbc连接
Class.forName(“com.esproc.jdbc.InternalDriver”);
con= DriverManager.getConnection(“jdbc:esproc:local://”);
//调用esProc,其中test是脚本文件名
st =(com.esproc.jdbc.InternalCStatement)con.prepareCall(“call test()”);
st.execute();//执行esProc存储过程
ResultSet set = st.getResultSet(); //获取结果集
读入数据时,有时候需要指定列的次序,以便更直观地操作数据。比如对于同样的文件data.txt,这次要按照x1Shift、x2Shift、radio、ID的新顺序读入数据。集算器可以直接指定顺序,只需书写如下代码:=file(“E:\data.txt”).import@t(xShift,yShift,ratio,ID)。
计算结果如下:

上述代码中,集算器会自动为数据设置合适的类型,比如xShift和yShift会设置为float型。但有时我们需要指定数据类型,比如ID虽然类似整数,但实际是字符串。如果要将ID的前4个字符单独取出,则集算器可通过如下代码来实现:

A1:强制类型转换,将ID列读为字符串,结果如下:

注意:集算器约定字符串在IDE中左对齐显示,数字右对齐显示,如上所示。
A2:截取前四个字符,结果如下:

读入数据时,有时候会遇到无分割符的情况,比如data2.txt有20个列,部分数据如下:

可以看到,data2.txt没有列分割符,且部分数据是无用的空行。集算器可以通过如下代码读取正确的数据:

A1:将数据读为单列序表,列名默认为“_1”。其中函数选项@s表示不拆分字段,直接读取。结果如下:

A2:A1.select(trim(_1)!=”"),过滤出非空行。函数select可以按照字段名或序号进行查询,结果如下:

A3:=A2.new(mid(_1,1,1),mid(_1,2,1),mid(_1,3,1),mid(_1,4,1),mid(_1,5,1),mid(_1,6,1), mid(_1,7,1),mid(_1,8,1),mid(_1,9,1),mid(_1,10,1),mid(_1,11,1),mid(_1,12,1),mid(_1,13,1),mid(_1,14,1),
mid(_1,15,1),mid(_1,16,1),mid(_1,17,1),mid(_1,18,1),mid(_1,19,1),mid(_1,20,1))
这句长代码用来将每行数据拆分为20个字段。函数mid有三个参数,分别是:被拆分的字段名,起始位置,截取的长度。拆分后的结果如下:

A3就是我们需要的计算结果。
A3中的代码太长,不利于错误检查和维护,可以使用集算器的动态代码予以简化,如下:
A4:=20.loops(~~+”mid(_1,” + string(~) + “,1),”)
A5:=exp=left(A4,len(A4)-1)
A6:=eval(“A2.new(“+ A5+”)”)
A4中,函数loops可用来进行循环计算,生成有规律的字符串,即“mid(_1,1,1),mid(_1,2,1),mid(_1,3,1),mid(_1,4,1),mid(_1,5,1),mid(_1,6,1),mid(_1,7,1),mid(_1,8,1),
mid(_1,9,1),mid(_1,10,1),mid(_1,11,1),mid(_1,12,1),mid(_1,13,1),mid(_1,14,1),mid(_1,15,1),
mid(_1,16,1),mid(_1,17,1),mid(_1,18,1),mid(_1,19,1),mid(_1,20,1),”
字符串A4在末尾多了一个逗号,用A5中的代码可以去掉逗号。
A6:执行动态脚本。函数eval可以将字符串动态解析为表达式,比如eval(“2+3”)相当于表达式2+3,其值为5。因此A5中的表达式实际和A3完全一样,计算结果自然也完全一样:
