【简介】


#coding:utf-8 import sys from numpy import * import operator import matplotlib.pyplot as plt def classify(input,dataSet,label): dataSize = dataSet.shape[0] ####计算欧式距离 tarry=tile(input,(dataSize,1));#生成dataSet一样的矩阵,进行剪发运算 diff = tarry - dataSet sqdiff = diff ** 2 #各参数平方(X²,Y²),得到距离 squareDist = sum(sqdiff,axis = 1)#行向量分别相加,从而得到新的一个行向量 X²,Y²相加, dist = list(squareDist ** 0.5) #开放,得到欧式距离 return label[dist.index(min(dist))] #返回最近邻 //找到距离最小值,并得与之对应的类型 dataSet = array([[0.1,2.8],[1.9,0.6],[1.0,2.0], [3.0,2.5],[2.0,2.5],[1.8,3.0], [0.1,0.1],[0.5,0.5],[1.5,0.5], [1.5,1.5],[1.7,0.1],[2.5,0.2], ]) labels = ['A','A','A','B','B','B','C','C','C','D','D','D'] input = array([1.9,0.5]) print("input = ",input) output = classify(input,dataSet,labels) print("class = ",output) plt.figure(figsize=(5,5)) for i,j in enumerate(dataSet): if labels[i] == 'A': plt.scatter(j[0],j[1],marker ="^",c="blue",s=80) elif labels[i] == 'B': plt.scatter(j[0],j[1],marker ="D",c ="green",s=80) elif labels[i] == 'C': plt.scatter(j[0],j[1],marker ="o",c ="darkorange",s=80) elif labels[i] == 'D': plt.scatter(j[0],j[1],marker ="s",c ="purple",s=80) plt.scatter(input[0],input[1],marker ="*",c ="red",s=200) plt.axis('tight') plt.show()
结果:
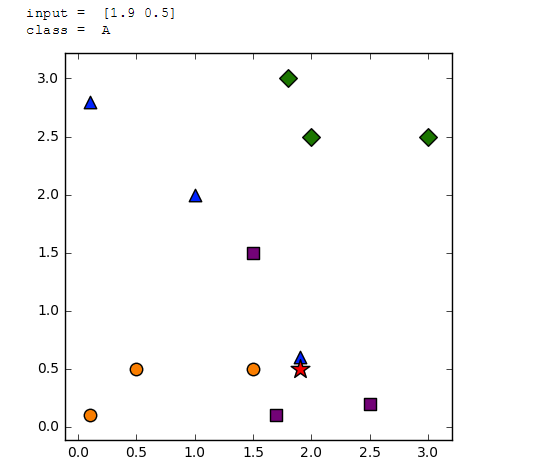
【K近邻算法】
最近邻算法的最大缺陷是对干扰数据过于敏感,为了解决这个问题,我们可以把未知样本周边的多个邻近样本计算在内,扩大参与决策的样本量,以避免个别数据直接决定决策结果。由此,我们引进K-最近邻算法(KNN)。K近邻算法是最近邻算法的一个延伸。思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。一般情况下,在分类时较大的K值能够减小干扰数据的影响。
#coding:utf-8 import sys from numpy import * import operator import matplotlib.pyplot as plt ###通过KNN进行分类 def classify(input,dataSet,label,k): dataSize = dataSet.shape[0] ####计算欧式距离 diff = tile(input,(dataSize,1)) - dataSet sqdiff = diff ** 2 squareDist = sum(sqdiff,axis = 1)###行向量分别相加,从而得到新的一个行向量 dist = squareDist ** 0.5 ##对距离进行排序 sortedDistIndex = argsort(dist)##argsort()根据元素的值从大到小对元素进行排序,返回下标 classCount={} for i in range(k): voteLabel = label[sortedDistIndex[i]] ###对选取的K个样本所属的类别个数进行统计 classCount[voteLabel] = classCount.get(voteLabel,0) + 1 ###选取出现的类别次数最多的类别 maxCount = 0 for key,value in classCount.items(): if value > maxCount: maxCount = value classes = key return classes dataSet = array([[0.1,2.8],[1.9,0.6],[1.0,2.0], [3.0,2.5],[2.0,2.5],[1.8,3.0], [0.1,0.1],[0.5,0.5],[1.5,0.5], [1.5,1.5],[1.7,0.1],[2.5,0.2], ]) labels = ['A','A','A','B','B','B','C','C','C','D','D','D'] input = array([1.9,0.5]) print("input = ",input) for K in range(1,13): output = classify(input,dataSet,labels,K) print("K = ",K,"class = ",output) plt.figure(figsize=(5,5)) for i,j in enumerate(dataSet): if labels[i] == 'A': plt.scatter(j[0],j[1],marker ="^",c="blue",s=80) elif labels[i] == 'B': plt.scatter(j[0],j[1],marker ="D",c ="green",s=80) elif labels[i] == 'C': plt.scatter(j[0],j[1],marker ="o",c ="darkorange",s=80) elif labels[i] == 'D': plt.scatter(j[0],j[1],marker ="s",c ="purple",s=80) plt.scatter(input[0],input[1],marker ="*",c ="red",s=200) plt.axis('tight') plt.show()
结果:
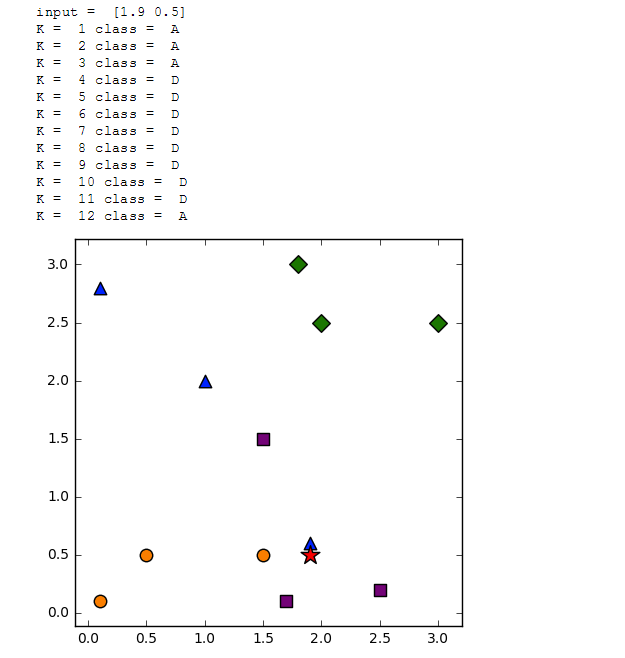
【K-Means++算法
K-Means++算法在聚类中心的初始化过程中的基本原则是使得初始的聚类中心之间的相互距离尽可能远,这样可以避免出现上述的问题。K-Means++算法的初始化过程如下所示:
在数据集中随机选择一个样本点作为第一个初始化的聚类中心
选择出其余的聚类中心:
计算样本中的每一个样本点与已经初始化的聚类中心之间的距离,并选择其中最短的距离,记为d_i 以概率选择距离最大的样本作为新的聚类中心,
重复上述过程,直到k个聚类中心都被确定 对k个初始化的聚类中心,利用K-Means算法计算最终的聚类中心。
#随机生成数据 def CreateDataset(number): #生成数组 dataArry=np.zeros((number,2)); #转为矩阵 dataSet=np.mat(dataArry); #数据分类聚类 offset=[[-80,-80],[-80,80],[-20,-20],[0,0],[80,-80],[30,-80],[80,80]]; #生成随机数据 for i in range(number): dataSet[i]=np.random.uniform(-20,20)+offset[i%7][0],np.random.uniform(-20,20)+offset[i%7][1]; #返回数据 return dataSet; #矩阵求欧式距离 def Distance(vectot1,vector2): #求样本数据差 sub=vector2-vectot1; #求矩阵平方 pows=np.power(sub,2); _sum=np.sum(pows); #求距离 distance=np.sqrt(_sum); return distance; #求样本数据在聚集点数据中的最近点 def nearest(point,cluster_centers): #线初始化一个比较大的最小值 min_dis=10000000; # 当前已经初始化的聚类中心的个数 m=np.shape(cluster_centers)[0]; #遍历聚类中心 for i in range(m): #计算point与每个聚类中心的距离 d=Distance(point,cluster_centers[i,]); #判断是否小是最短距离 if min_dis>d: min_dis=d; return min_dis; #生成聚类点 def clusterCenter(dataSet,k): #1、获取样本数据集的shape num,dim=dataSet.shape; #2、创建聚集点集 clusterPoints=np.zeros((k,dim)); cluster_centers=np.mat(clusterPoints); #3、随机在样本数据中选取一个点作为第一个聚集点 index=np.random.randint(0,num); cluster_centers[0,]=dataSet[index,]; #4、初始化一个距离序列 disList=[0.0 for _ in range(num)]; #5、从第二个点开始遍历聚合点(第一个点已经赋值了) for i in range(1,k): sum_all=0; for j in range(num): #6、对每一个样本点找到最近的聚类中心 point=dataSet[j,];#获取第j个样本 cluster_points=cluster_centers[0:i,];#获取前i个样本数据 disList[j]=nearest(point,cluster_points); #7、将所有最短距离相加 sum_all=sum_all+disList[j]; #8、获取sum_all之间的随机值 sum_all = np.random.uniform(0,int(sum_all)); # 9、获得距离最远的样本点作为聚类中心点 for j, di in enumerate(disList): sum_all -= di if sum_all > 0: continue cluster_centers[i] = dataSet[j,]; break return cluster_centers; #K-Means聚类 def kmeans(data,k,centroids): #获取样本维度,m表示样本个数,n表示样本维度 m,n=np.shape(data); #初始化样本所属类别 subCenter=np.mat(np.zeros((m,n))); #初始化判断变量 change=True; #训练数据 while change==True: #重置变量 change=False; #遍历样本数据 for i in range(m): minDis=10000000;#初始化最小数据 minIndex=0;#初始化最小距离的 #遍历聚集点 for j in range(k): #计算两点距离 dist=Distance(data[i,],centroids[j,]); #判断距离是否为最小 if dist <minDis: minDis=dist; minIndex=j; #判断是否需要改变 subCenter[i,0]不等于minindex if subCenter[i,0] != minIndex: change=True; subCenter[i,]=np.mat([minIndex, minDis]) #重新计算聚类中心 for j in range(k): #创建数据维度的总和矩形 sum_all=np.mat(np.zeros((1,n))); count=0;#没类的样本个数 #循环所属类别数据 for i in range(m): if subCenter[i,0]==j: sum_all+=data[i,]; count+=1; #遍历数据维度 for z in range(n): try: centroids[j,z]=sum_all[0,z]/count; except: print("count为零"); return subCenter; #保存聚类数据 def save_result(file_name, source): m, n = np.shape(source) f = open(file_name, "w") for i in range(m): tmp = [] for j in range(n): tmp.append(str(source[i, j])) f.write(" ".join(tmp) + " ") f.close() print("保存完成"); #主函数 if __name__=="__main__": dataNum=300;#样本数据集量 k=7;#分类数 # 1、创建数据 dataSet=CreateDataset(dataNum); print("数据初始化完成"); #生成聚合点 cluster_centers=clusterCenter(dataSet,k); print("生成聚合点"); #开始聚类 subcenter=kmeans(dataSet,k,cluster_centers); print("聚类完成"); #保存数据所属类别数据 save_result("subcenter.txt",subcenter); #保存数据所属类别数据 save_result("cluster_centers.txt",cluster_centers); #画图 #plt.figure(figsize=(-100,100)); #绘制数据 numSamples, dim = dataSet.shape mark = ['or', 'og', 'ob', 'oc', 'om', 'oy', 'ok', 'ow'] for i in range(numSamples): markIndex = int(subcenter[i, 0]); plt.plot(dataSet[i, 0], dataSet[i, 1], mark[markIndex-1]) #绘制聚合点 mark = ['*r', '*g', '*b', '*c', '*m', '*y', '*k', '*w'] for i in range(k): plt.plot(cluster_centers[i, 0], cluster_centers[i, 1], mark[i-1], markersize = 12) plt.axis('tight') plt.show() print("完成");
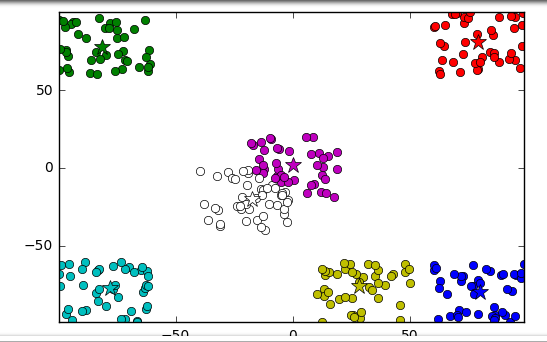
【参考文献】
https://blog.csdn.net/sm9sun/article/details/78521927
https://www.cnblogs.com/charlesblc/p/6193979.html
http://blog.csdn.net/acdreamers/article/details/44672305
http://blog.csdn.net/u013414741/article/details/47108317
https://www.cnblogs.com/ybjourney/p/4702562.html
https://blog.csdn.net/google19890102/article/details/53284285