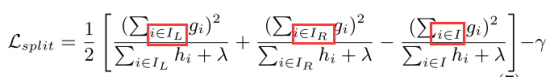(原创)
本文讨论XGBoost的原理
1.目标函数
xgboost需要优化的目标函数分为两部分,
一部分是样本的损失函数(下式红色部分),另一部分是对模型复杂程度的正则罚项(下式蓝色部分,下式的基模型为cart树):
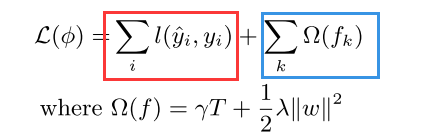
2.梯度提升方法
第t次迭代的yi预测值可以由第t-1次的预测值,加上一个第t轮新模型的预测值:

带入1中目标函数即是:
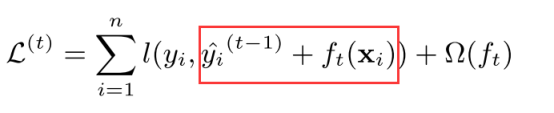
对上面红框部分看成 x+∆x ,在x点泰勒展开,并展开到二阶项,即得下式:

注意到蓝色部分是常值(因为上一轮预测值已确定),不影响函数优化,可以去掉得到下面函数:
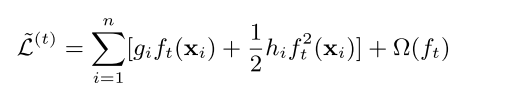
这是general的目标优化函数,接下来以基础决策树为基模型为例继续推导,
带入决策树模型的正则罚项得到下面式子:
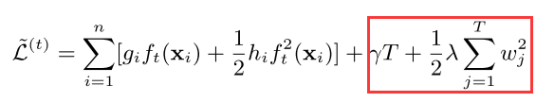
由于左边部分是针对样本的,而正则罚项是基于叶子节点的,这时候为了两者可以合并,做一个技巧处理:遍历样本转换为遍历叶子节点,因为样本的f会落在某个叶子节点上,因此得到下式:
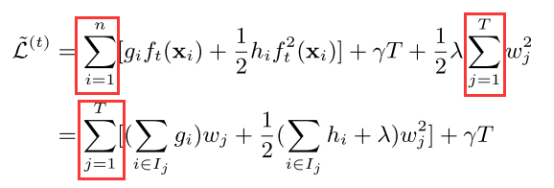
至此,可以看出上式式关于Wj的二次函数,那么很容易得到最优点(-b/2a)和最值((4ac-b^2)/4a):
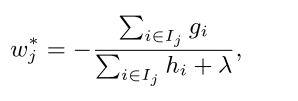
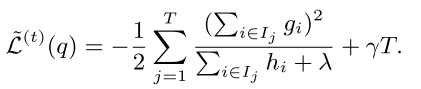
这个最值也是衡量该树质量的量化标准,
同时,用这个值的变化量来度量某颗树分割为左右子树的效果好坏,即下式: