日期:2021.05.03
作者:杨传伟
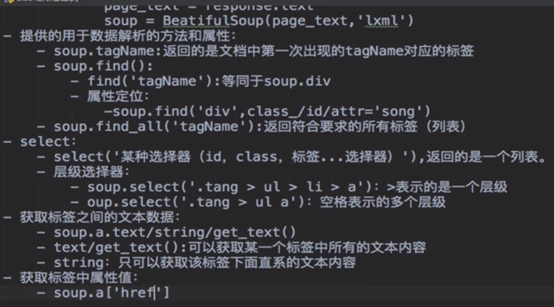
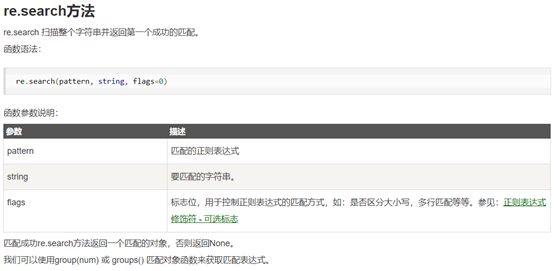
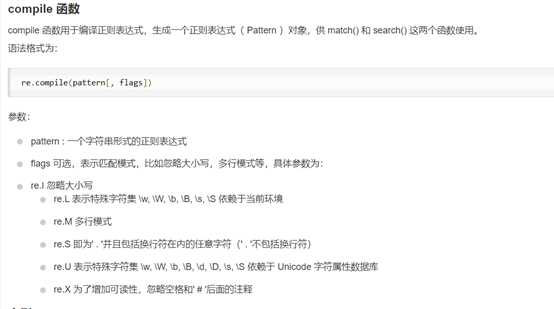
完成任务:爬虫、re、beautifulSoup解析网页初步。





5.3 李楠
今日完成豆瓣电影的爬取,主要有电影标题(title),主演(star),导演(director),类型(type_movie),
地区(area),日期(date_time),简介(summary),评分(score),语言(language),照片(img),评价人数(scorenum),时长(timelen)。
但是豆瓣的地区与语言的内容在标签之外用bs4无法解析到:

主要代码:
1 2 import string
3 import time
4 import traceback
5
6 import pymysql
7 import requests
8 import re
9
10 from lxml import etree
11 import random
12
13 from bs4 import BeautifulSoup
14 from flask import json
15
16 def get_conn():
17 """
18 :return: 连接,游标192.168.1.102
19 """
20 # 创建连接
21 conn = pymysql.connect(host="*",
22 user="root",
23 password="root",
24 db="*",
25 charset="utf8")
26 # 创建游标
27 cursor = conn.cursor() # 执行完毕返回的结果集默认以元组显示
28 return conn, cursor
29
30 def close_conn(conn, cursor):
31 if cursor:
32 cursor.close()
33 if conn:
34 conn.close()
35
36 def query(sql,*args):
37 """
38 封装通用查询
39 :param sql:
40 :param args:
41 :return: 返回查询结果以((),(),)形式
42 """
43 conn,cursor = get_conn();
44 cursor.execute(sql)
45 res=cursor.fetchall()
46 close_conn(conn,cursor)
47 return res
48
49 def get_tencent_data():
50 #豆瓣的网址
51 url_bean = 'https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=%E7%94%B5%E5%BD%B1&start='
52
53 headers = {
54 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36',
55 }
56 a=1
57 num=0
58 cursor = None
59 conn = None
60 conn, cursor = get_conn()
61 while a<=100:
62 num_str='%d'%num
63 num=num+20
64 a=a+1;
65 # 获取豆瓣页面电影数据
66 r = requests.get(url_bean + num_str, headers=headers)
67 res_bean = json.loads(r.text);
68 data_bean = res_bean["data"]
69 print(f"{time.asctime()}开始插入数据",(a-1))
70 #循环遍历电影数据
71 try:
72 for i in data_bean:
73
74
75 #分配数据
76 score = i["rate"]
77 director = i["directors"] # []
78 director_str = ""
79 for j in director:
80 director_str = director_str + " " + j
81 name = i["title"]
82 img = i["cover"]
83 star = i["casts"] # []
84 star_str = ""
85 for j in star:
86 star_str = star_str + " " + j
87 # 分配数据
88
89 # 获取电影详细数据的网址
90 url_details = i["url"]
91 r = requests.get(url_details, headers=headers)
92 soup_bean = BeautifulSoup(r.text,"lxml")
93 #获取详细数据
94 span = soup_bean.find_all("span", {"property": "v:genre"})
95 type = ""
96 for i in span:
97 type = type + " " + i.text
98 span = soup_bean.find_all("span", {"property": "v:runtime"})
99 timelen = span[0].text
100 span = soup_bean.find_all("span", {"property": "v:initialReleaseDate"})
101 date = span[0].text
102 span = soup_bean.find("a", {"class", "rating_people"})
103 scorenum = span.text
104 span = soup_bean.find("span", {"property": "v:summary"})
105 summary = span.text.replace(" ", "")#将空格去掉
106 # 获取详细数据
107
108 sql = "insert into test_bean values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
109 cursor.execute(sql, [name, star_str, director_str, type, "", date, summary, score, "", img, scorenum,
110 timelen])
111 conn.commit() # 提交事务 update delete insert操作 //*[@id="info"]/text()[2]
112 except:
113 traceback.print_exc()
114 print(f"{time.asctime()}插入数据完毕",(a-1))#循环了几次
115 close_conn(conn, cursor)
116 print(f"{time.asctime()}所有数据插入完毕")
117
118 if __name__ == "__main__":
119 get_tencent_data()
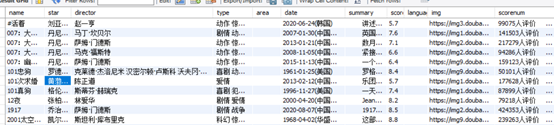
数据库截图:
5.3 章英杰
任务进度:通过借鉴豆瓣网首页的页面设计,对于项目页面的整体布局进行了设计,并完成了背景部分。
产品页面:
每日任务看板:

每日照片:
