deeplabv3是一种语义分割网络,语义分割旨在对给定图片的每一个像素点进行类别预测,在这里我们来梳理一下deeplabv3网络的大致流程仅供参考,参考的算法实现地址为:https://github.com/fregu856/deeplabv3
1.网络流程图
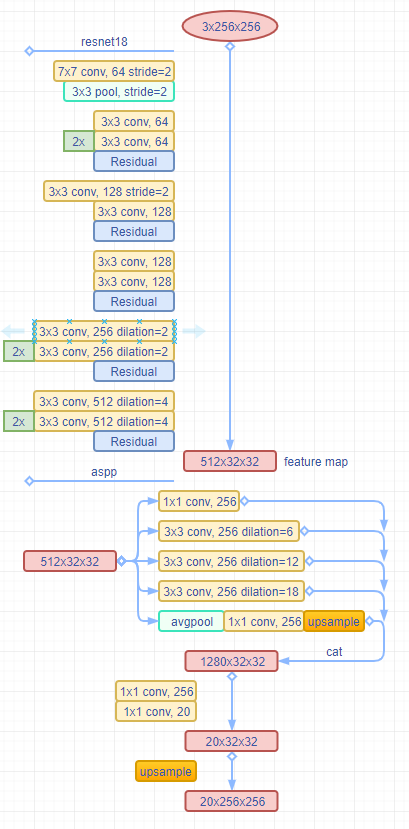
2.网络原理
算法使用的数据集是分割常用的cityscapes,在对数据集进行适当的预处理后,输入网络的是batchx3x256x256的图片和batchx256x256的标签,标签的取值范围是0-19,代表一共有20类。
1.首先对图片进行特征提取,上图使用的是resnet18网络进行的特征提取,得到的是512x32x32的特征图;
2.aspp网络层对上一步得到的特征图从5个分支分别进行各自的卷积提取操作,得到的都是256x32x32的特征图,然后将它们拼接在一起,得到1280x32x32的特征图,再经过两次卷积得到20x32x32的特征图;
3.最后对20x32x32的特征图进行一次上采样操作,得到20x256x256的特征图,即最后我们需要的输出;
4.loss直接对20x256x256的特征图和256x256的标签在每一个像素点进行交叉熵损失计算,考虑到类别不平衡问题,网络还对每个类别的损失添加了相应的权重;