背景
2009年,李飞飞和他的团队发表了ImageNet的论文,还附带了数据集。
2012年,多伦多大学的Geoffrey Hinton、Ilya Sutskever和Alex Krizhevsky提出了一种深度卷积神经网络结构:AlexNet,夺得了ImageNet冠军,成绩比当时的第二名高出41%。
结构
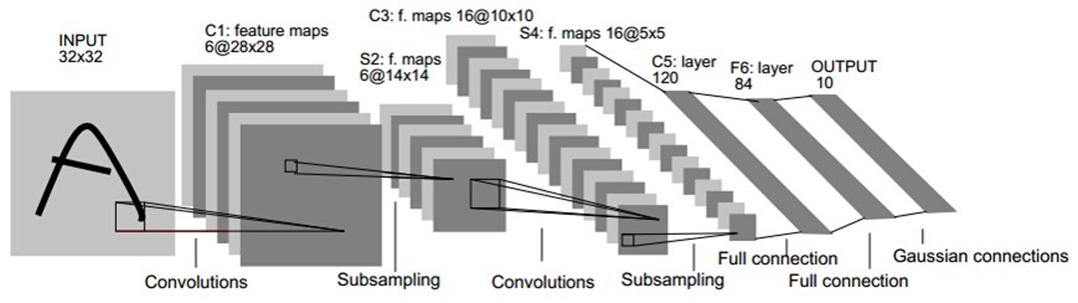
经典的Lenet(发布于1999)结构如下:
AlexNet的结构模型如下:
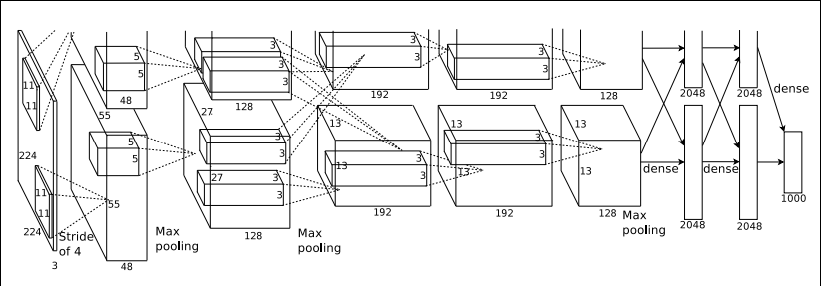
AlexNet相比LeNet主要的改动在于:
(1) Data Augmentation数据增长,现在的网络中已经大量使用了。最主要的是剪裁,光照变换和水平翻转。
(2) Dropout
Dropout方法和数据增强一样,都是防止过拟合的。Dropout应该算是AlexNet中一个很大的创新,以至于Hinton在后来很长一段时间里的Talk都拿Dropout说事,后来还出来了一些变种,比如DropConnect等。
(3) ReLU激活函数
用ReLU代替了传统的Tanh或者Logistic。好处有:
ReLU本质上是分段线性模型,前向计算非常简单,无需指数之类操作;
ReLU的偏导也很简单,反向传播梯度,无需指数或者除法之类操作;
ReLU不容易发生梯度发散问题,Tanh和Logistic激活函数在两端的时候导数容易趋近于零,多级连乘后梯度更加约等于0;
ReLU关闭了右边,从而会使得很多的隐层输出为0,即网络变得稀疏,起到了类似L1的正则化作用,可以在一定程度上缓解过拟合。
当然,ReLU也是有缺点的,比如左边全部关了很容易导致某些隐藏节点永无翻身之日,所以后来又出现pReLU、random ReLU等改进,而且ReLU会很容易改变数据的分布,因此ReLU后加Batch Normalization也是常用的改进的方法。
(4) Local Response Normalization
Local Response Normalization要硬翻译的话是局部响应归一化,简称LRN,实际就是利用临近的数据做归一化。这个策略贡献了1.2%的Top-5错误率。
(5) Overlapping Pooling
Overlapping的意思是有重叠,即Pooling的步长比Pooling Kernel的对应边要小。这个策略贡献了0.3%的Top-5错误率。
(6) 多GPU并行
实现
线性的网络结构
卷积层:5层
全连接层:3层
深度:8层
神经元个数:650k
分类数目:1000类
参数个数:60M
C1:96*11*11*3(卷积核个数/宽/高/厚度) 34848个参数
C2:256*5*5*48(卷积核个数/宽/高/厚度) 307200个参数
C3:384*3*3*256(卷积核个数/宽/高/厚度) 884736个参数
C4:384*3*3*192(卷积核个数/宽/高/厚度) 663552个参数
C5:256*3*3*192(卷积核个数/宽/高/厚度) 442368个参数
R1:4096*6*6*256(卷积核个数/宽/高/厚度) 37748736个参数
R2:4096*4096 16777216个参数
R3:4096*1000 4096000个参数
总计:60924656个参数
C1:96*55*55 290400个神经元
C2:256*27*27 186624个神经元
C3:384*13*13 64896个神经元
C4:384*13*13 64896个神经元
C5:256*13*13 43264个神经元
R1:4096个神经元
R2:4096个神经元
R3:1000个神经元
总计:659272个
input_data = mx.symbol.Variable(name="data") # stage 1 conv1 = mx.symbol.Convolution(name='conv1', data=input_data, kernel=(11, 11), stride=(4, 4), num_filter=96) relu1 = mx.symbol.Activation(data=conv1, act_type="relu") lrn1 = mx.symbol.LRN(data=relu1, alpha=0.0001, beta=0.75, knorm=2, nsize=5) pool1 = mx.symbol.Pooling( data=lrn1, pool_type="max", kernel=(3, 3), stride=(2,2)) # stage 2 conv2 = mx.symbol.Convolution(name='conv2', data=pool1, kernel=(5, 5), pad=(2, 2), num_filter=256) relu2 = mx.symbol.Activation(data=conv2, act_type="relu") lrn2 = mx.symbol.LRN(data=relu2, alpha=0.0001, beta=0.75, knorm=2, nsize=5) pool2 = mx.symbol.Pooling(data=lrn2, kernel=(3, 3), stride=(2, 2), pool_type="max") # stage 3 conv3 = mx.symbol.Convolution(name='conv3', data=pool2, kernel=(3, 3), pad=(1, 1), num_filter=384) relu3 = mx.symbol.Activation(data=conv3, act_type="relu") conv4 = mx.symbol.Convolution(name='conv4', data=relu3, kernel=(3, 3), pad=(1, 1), num_filter=384) relu4 = mx.symbol.Activation(data=conv4, act_type="relu") conv5 = mx.symbol.Convolution(name='conv5', data=relu4, kernel=(3, 3), pad=(1, 1), num_filter=256) relu5 = mx.symbol.Activation(data=conv5, act_type="relu") pool3 = mx.symbol.Pooling(data=relu5, kernel=(3, 3), stride=(2, 2), pool_type="max") # stage 4 flatten = mx.symbol.Flatten(data=pool3) fc1 = mx.symbol.FullyConnected(name='fc1', data=flatten, num_hidden=4096) relu6 = mx.symbol.Activation(data=fc1, act_type="relu") dropout1 = mx.symbol.Dropout(data=relu6, p=0.5) # stage 5 fc2 = mx.symbol.FullyConnected(name='fc2', data=dropout1, num_hidden=4096) relu7 = mx.symbol.Activation(data=fc2, act_type="relu") dropout2 = mx.symbol.Dropout(data=relu7, p=0.5) # stage 6 fc3 = mx.symbol.FullyConnected(name='fc3', data=dropout2, num_hidden=num_classes) softmax = mx.symbol.SoftmaxOutput(data=fc3, name='softmax') return softmax