python中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU的资源,在python中大部分情况需要使用多进程。Python提供了非常好用的多进程包multiprocessing,只需要定义一个函数,Python会完成其他所有事情。借助这个包,可以轻松完成从单进程到并发执行的转换
本来想写多线程的,但是演示效果并不是很好,就改成进程了。

其实多进程没有我们想象的那么难,用几个小例子给大家分享一下!
目录
-
多进程的多种实现方法及效果演示:这段将通过几个小脚本实现多进程的效果
-
一个小爬虫实例,通过运行时间来查看进程对代码速度的影响
多进程
首先我们先做一个小脚本,就用turtle画4个同心圆吧!这样在演示多进程的时候比较直观。代码如下:
1 import turtle 2 3 def cir(n,m): 4 turtle.penup() 5 turtle.goto(n) 6 turtle.pendown() 7 turtle.circle(m) 8 time.sleep(1) 9 def runn(lis1,lis2): 10 for n, m in zip(lis1,lis2): 11 cir(n,m) 12 if __name__ == '__main__': 13 nn = [(0,-200),(0,-150),(0,-100),(0,-50)] 14 mm = [200,150,100,50] 15 runn(nn,mm)
这段代码,实现了画4个同心圆的效果,如果用多进程的话,我们稍微该写一下,将runn()函数替换下面的代码
from multiprocessing import Process,Pool
for i in range(4):
Process(target=runn,args=(nn,mm)).start()
这里,启动4个进程,同时画圆,给个图大家感受一下!
可以看到,这里直接生成4个画板同时画同心圆。如果还要在加进程的话,可以用pool进程池,注意pool有2个方法,建议用非阻塞的p.apply_async不要用阻塞的p.apply方法,p.apply_async会由系统自行判断并运行,比如指定4个进程运行5个任务,那么会在某一个进程运行完毕的同时自动开始第5个任务,而阻塞的p.apply方法会一次只运行一个进程。
然后就是记得close()进程池,并用p.join()等待所有进程完成!相关代码如下
1 p = Pool(9) 2 for i in range(9): 3 p.apply_async(runn,(nn,mm))#非阻塞 4 #p.apply(runn,(nn,mm))#阻塞 5 p.close() 6 p.join()
Pool()里面不带参数会自动适应电脑本身内核数量,这里我设置9个进程同时进行!来看看效果
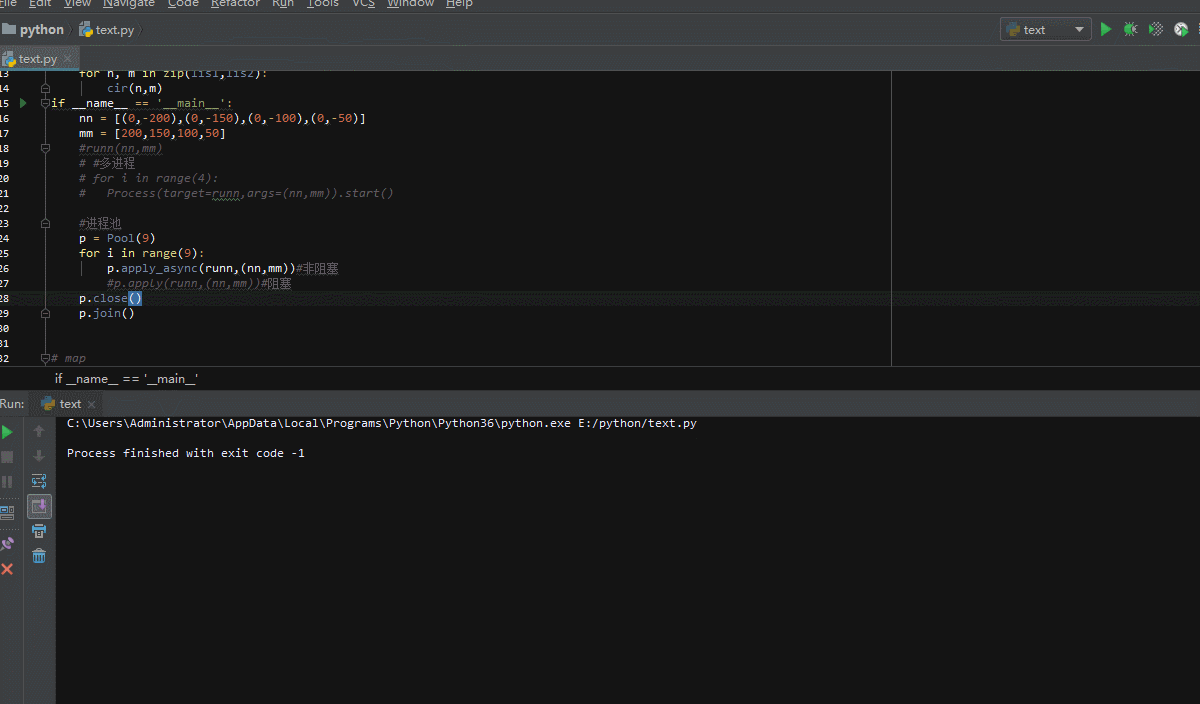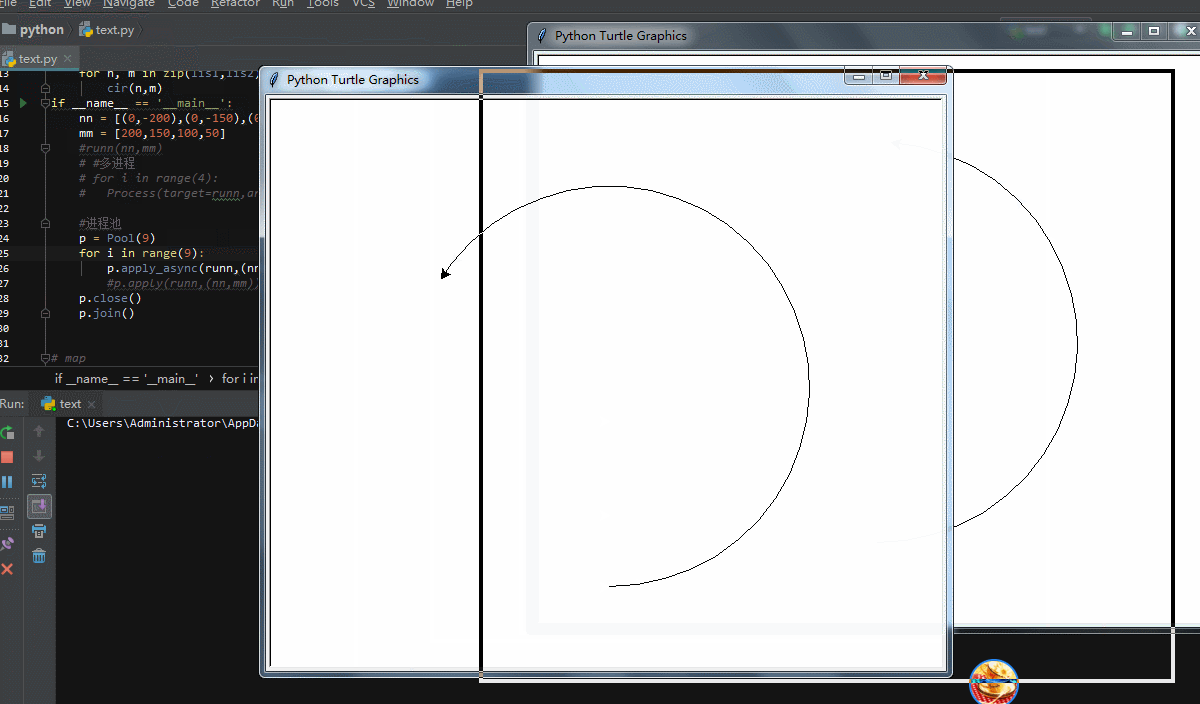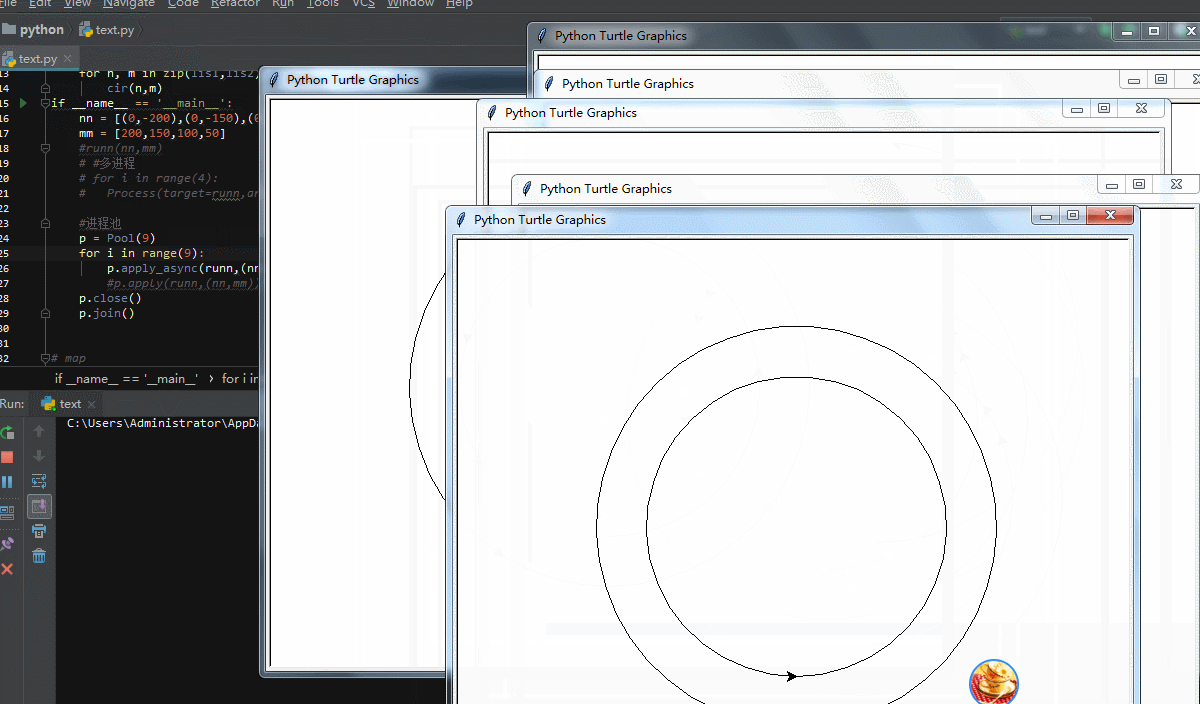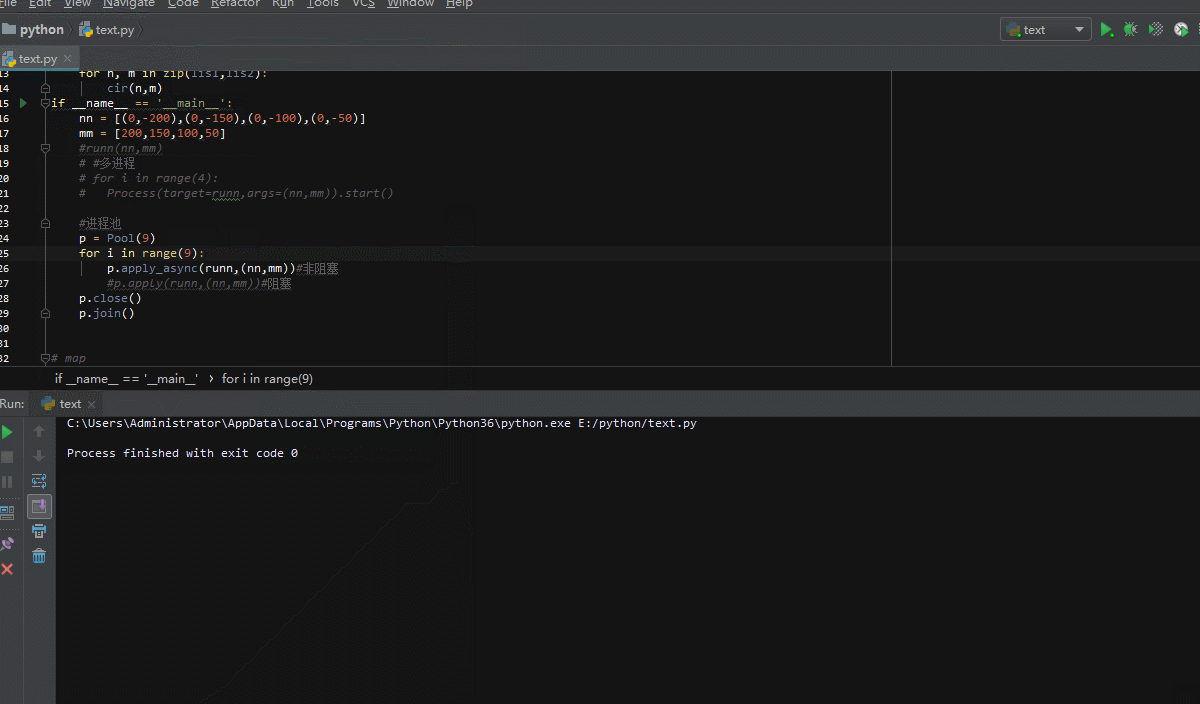
可以看到,同时进行了9个画图的进程,但是同样的,有明显的卡顿感!当然,我们也可以用map函数来写多进程,先修改下代码
def cir(m): turtle.penup() turtle.goto(m[0]) turtle.pendown() turtle.circle(m[1]) time.sleep(14) if __name__ == '__main__': nn = [(0, -200), (0, -150), (0, -100), (0, -50)] mm = [200, 150, 100, 50] mn = [(x,y) for x,y in zip(nn,mm)] p = Pool(3) p.map(cir,mn)
这次不画4个同心圆了,我们让它4个进程各画一个圆,来看看效果
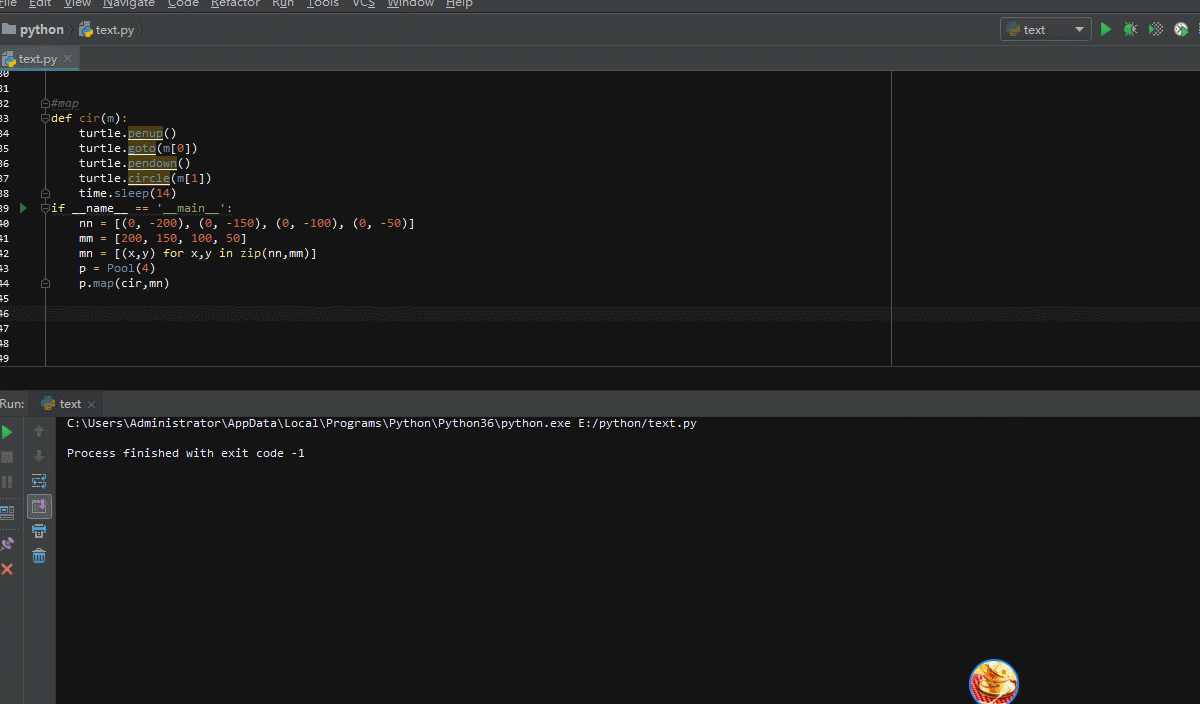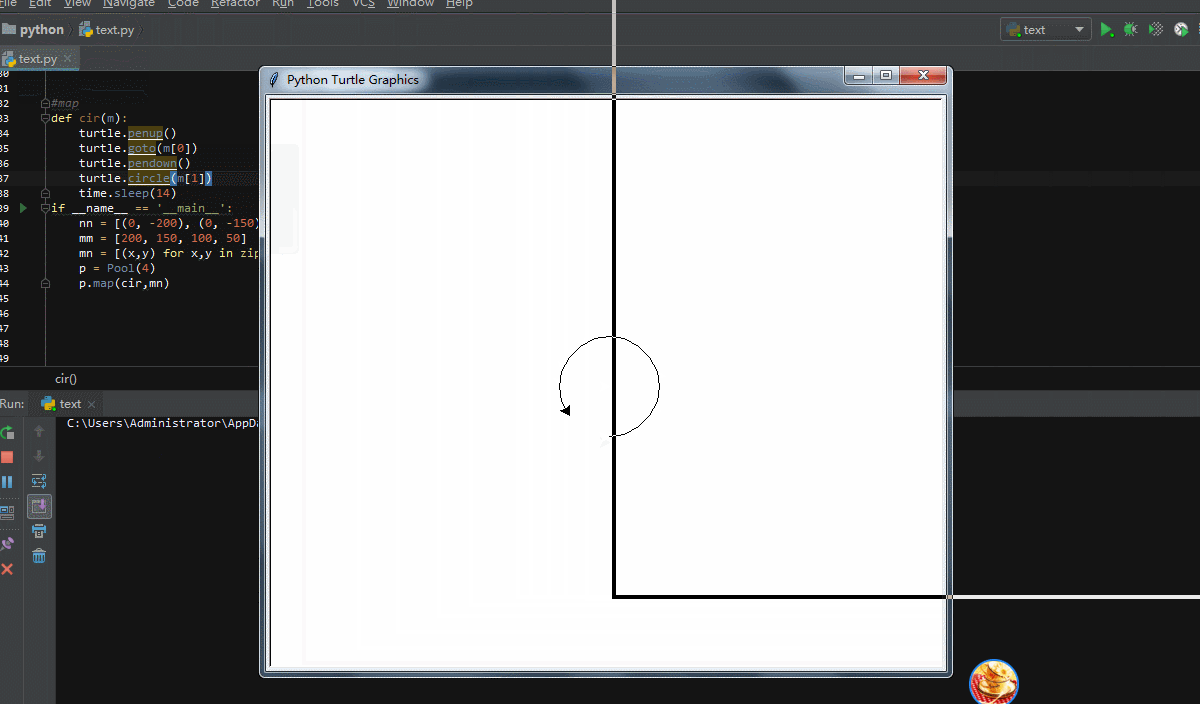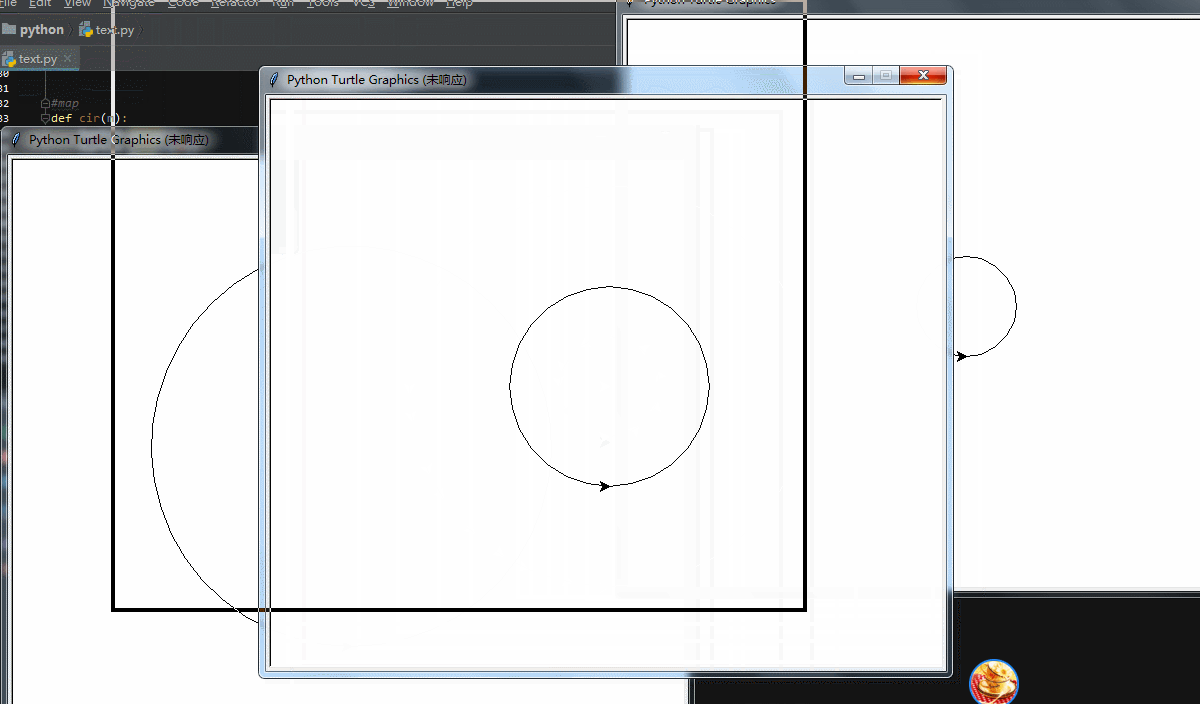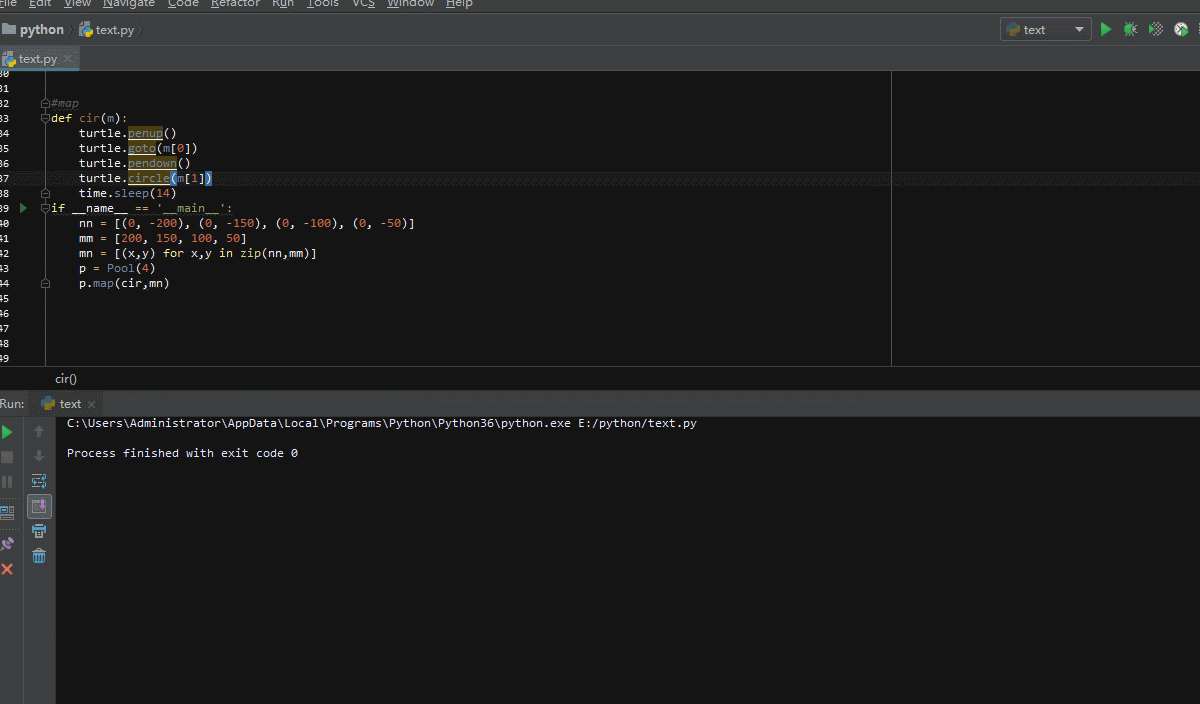
为了演示效果,多加了点间隔时间,并把cir函数的参数改为1个,这样便于生成元组列表!可以看到,有了明显的卡顿,电脑不好,大家看看效果就行了
写个简单的多进程爬虫
做一个小爬虫,加入运行时间,先上一个不使用进程的代码:
import requests from lxml import etree import time from multiprocessing import Process,Pool def main(url): time.sleep(1) html = requests.get(url) html.encoding = 'gb2312' data = etree.HTML(html.text) title = data.xpath('//a[@class="ulink"]/text()') summary = data.xpath('//td[@colspan="2"]/text()') urls = data.xpath('//a[@class="ulink"]/@href') for t,s,u in zip(title,summary,urls): print(t) print('【url:】http://www.dytt8.net'+u) print('【简介】>>>>>>>'+s) if __name__ == '__main__': start = time.time() url = 'http://www.dytt8.net/html/gndy/dyzz/' pg_url = [url+'list_23_{}.html'.format(str(x)) for x in range(1,10)] for pg_u in pg_url: main(pg_u) end = time.time() print("共计用时%.4f秒"%(end-start))
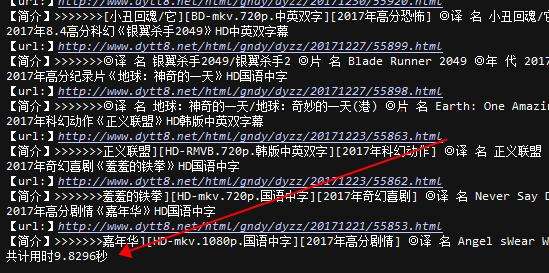
在修改下多进程,直接修改最后几行行代码即可
pg_url = [url+'list_23_{}.html'.format(str(x)) for x in range(1,10)] # for pg_u in pg_url: # main(pg_u) p=Pool() p.map(main,pg_url) end = time.time() print("共计用时%.4f秒"%(end-start))
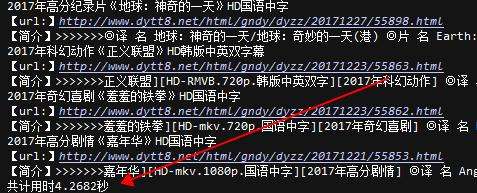
可以看到,速度提高了1倍多,当然,并不是说只能提高一倍,而是我的代码太简单了,只是从网站抓取字符串打印出来,响应速度很快,导致提升的倍率并没有我们想象的那么高,如果大家有兴趣,可以尝试一下,基本上可以提升到进程数的倍率,也就是说,不超过电脑核心数量,且没有其他外因(比如网络响应速度等等)的情况下,用4进程可以提升接近4倍的速度!

后记
在学习的过程中,难免会遇到很高深并且很难理解的知识点,我们可以先尝试去简化理解它,比如多进程,它本身还有进程池、进程间通讯、守护进程、进程类(重写run方法)、进程锁、进程队列、管道、信号量等等功能或知识点,这里都没有涉及,不过这并不影响我们使用简单的多进程写代码!