【测试环境】
服务器:Linux Centos7.2
InfluxDB版本:influxdb-1.7.1.x86_64.rpm
【相关网址】
influxdb官网:https://www.influxdata.com/
相关API官网:https://docs.influxdata.com/influxdb/v1.7/
推荐博客:https://www.jianshu.com/p/f0905f36e9c3
【相关特点】
1)基于时间序列,支持与时间有关的相关函数(如最大,最小,求和等);
2)可度量性:你可以实时对大量数据进行计算;
3)基于事件:它支持任意的事件数据;
4)无结构(无模式):可以是任意数量的列;
5)支持min, max, sum, count, mean, median 等一系列函数;
6)内置http支持,使用http读写;
7)强大的类SQL语法;
8)自带管理界面,方便使用(新版本需要通过Chronograf)
【对比OpenTSDB】
| 特性 | InfluxDB | OpentsDB |
|---|---|---|
| 单机部署 | 部署简单、无依赖 | 需要搭建 Hbase,创建 TSD 数据表,配置 JAVA 等 |
| 集群 | 开源版本没有集群功能 | 集群方案成熟 |
| 资源占用 | cpu 消耗更小,磁盘占用更小 | 资源消耗相比更多 |
| 存储模型 | TSM | 基于HBase存储时序数据(LSM) |
| 存储特点 | 同一数据源的tags不再冗余存储 ;列式存储,独立压缩 | 存在很多无用的字段;无法有效的压缩;聚合能力弱 |
| 性能 | 查询更快,数据汇聚分析较快 | 数据写入和存储较快,但查询和分析能力略有不足 |
| 开发 | 版本升级快,但架构简单,类SQL语言(InfluxQL)易开发 | API较为丰富,版本较为稳定 |
【安装部署 】
1、安装epel源
epel (Extra Packages for Enterprise Linux)是基于Fedora的一个项目,为“红帽系”的操作系统提供额外的软件包,适用于RHEL、CentOS和Scientific Linux.
命令:yum install epel-release
2、安装go环境
命令:yum install golang
3、下载influxdb安装包
命令:wget https://dl.influxdata.com/influxdb/releases/influxdb-1.7.1.x86_64.rpm
4、安装influxdb
命令:rpm -ivh influxdb-1.7.1.x86_64.rpm
【启停命令】
启动命令:service influxdb start
停止服务:service influxdb stop
重启服务:service influxdb restart
尝试重启服务:service influxdb try-restart
重新加载服务:service influxdb reload
强制重新加载服务:service influxdb force-reload
查看服务状态:service influxdb status
【web界面】
按照上面的操作安装完毕之后,尝试着打开InfluxDB自带的Web页面,结果是打不开的。因为从1.3版开始InfluxDB官方就把web界面给取消了。
尝试了大家推荐的Grafna,安装及使用方法参考我的另一篇学习笔记。
https://www.cnblogs.com/quchunhui/p/12381080.html
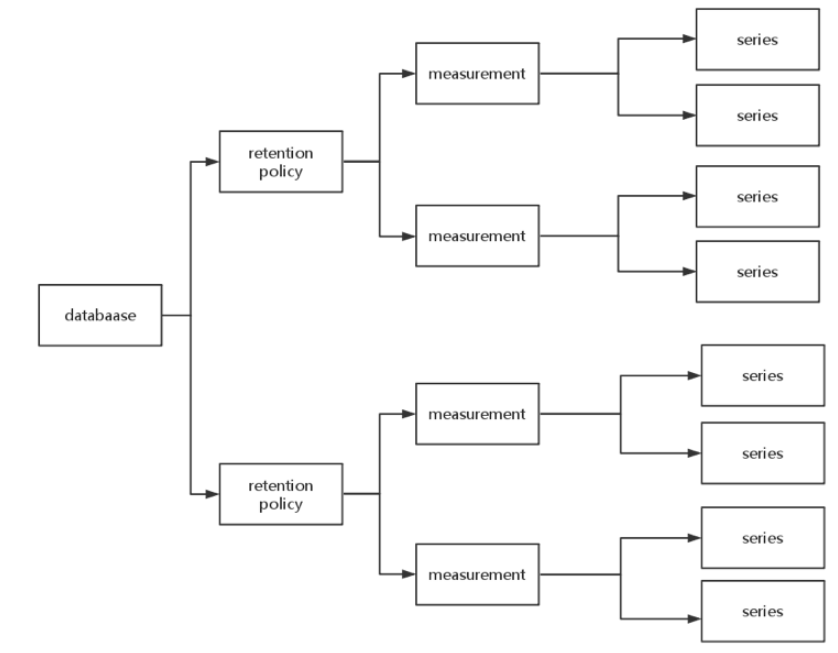
【数据模型】
参考图一:
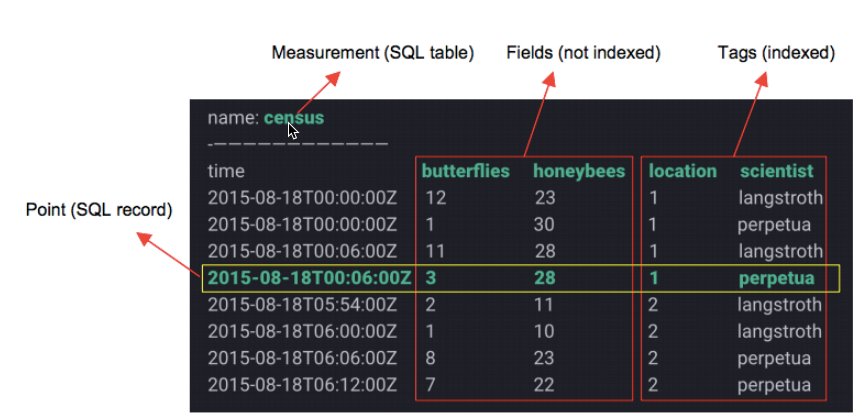
参考图二:
参考图三:

参考图四:与传统数据库的名词比较

1、database
数据库名。在 InfluxDB 中可以创建多个数据库,不同数据库中的数据文件是隔离存放的,存放在磁盘上的不同目录。
2、measurement
测量指标名。例如 cpu_usage 表示 cpu 的使用率。
3、point
由时间戳(time)、数据(field)、标签(tags)组成。相当于传统数据库里的一行数据,如下表所示:

【timestamp】:
时间戳,ns单位,每个记录都必然有这个属性,没有显示添加时,默认给一个
【tag】:
标签,kv结构,在database中,tag + measurement 一起构建索引。
tag参与索引创建,因此适合作为查询的过滤条件。
tag数据量不宜过多,最好能有典型的辨别性(和mysql的建立索引的原则差不多)。
tag是可选的,在measurement不设置tag也是ok的。
【field】:
存储数据,kv结构。数据类型为: long, String, boolean, float
【series】:
tag key与tag value的唯一组合。
所有在数据库中的数据,都需要通过图表来表示,series表示这个表里面的所有的数据可以在图表上画成几条线(注:线条的个数由tags排列组合计算出来)
同一个 series 的数据在物理上会按照时间顺序排列存储在一起。
在程序中debug查看了一下series的函数结构:

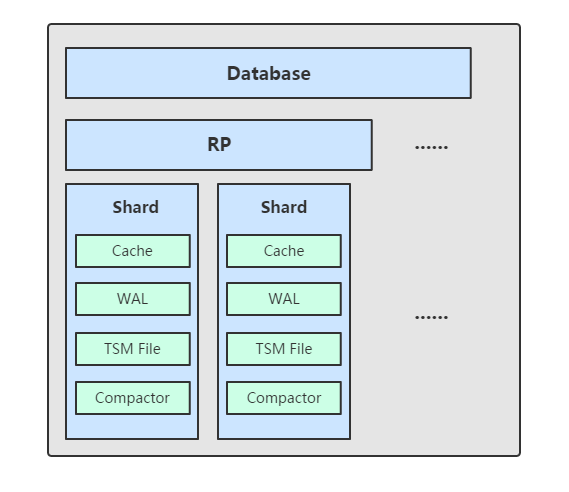
【物理模型】
1、Shard
Shard在InfluxDB中是一个比较重要的概念,它和retention policy(数据保留策略)相关联。
每一个存储策略下会存在许多shard,每一个shard存储一个指定时间段内的数据,并且不重复,
例如:7点-8点的数据落入shard0中,8点-9点的数据则落入shard1中。
每一个 shard 都对应一个底层的 tsm 存储引擎,有独立的 cache、wal、tsm file。
这样做的目的就是为了可以通过时间来快速定位到要查询数据的相关资源,加速查询的过程,并且也让之后的批量删除数据的操作变得非常简单且高效。
2、TSM存储引擎
部分组成:cache、wal、tsm file、compactor。(与HBase的LSM模型类似)
数据写入过程:
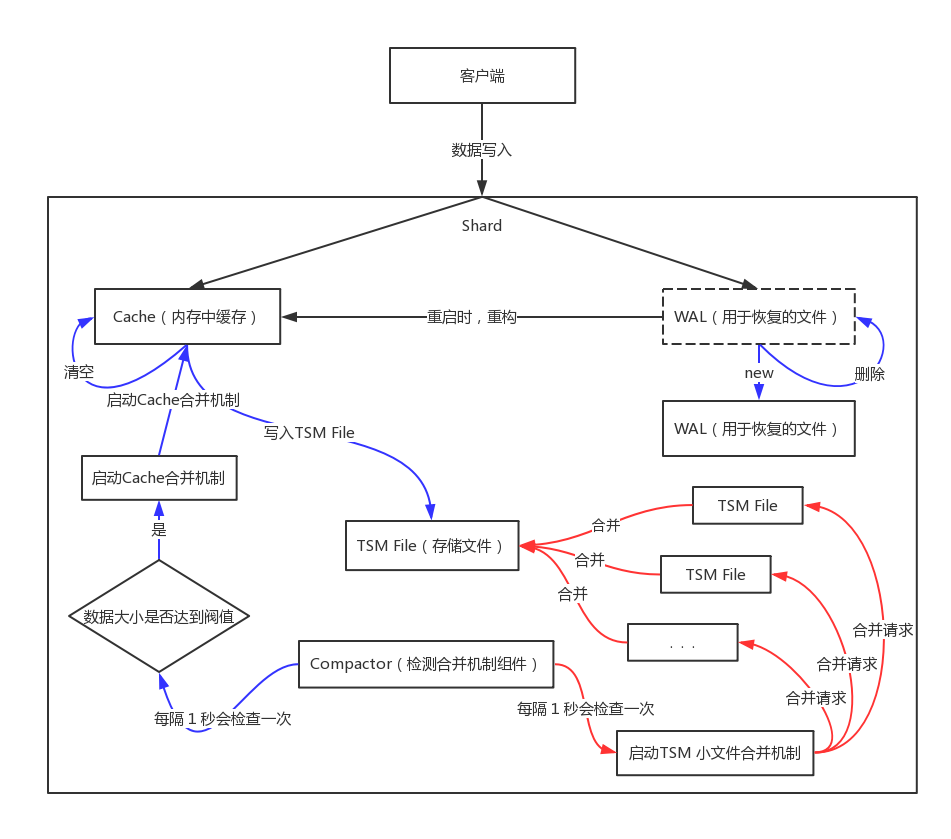
1)Cache:
cache相当于是LSM Tree中的memtabl。
插入数据时,实际上是同时往cache与wal中写入数据,可以认为cache是wal文件中的数据在内存中的缓存。
当InfluxDB启动时,会遍历所有的wal文件,重新构造cache,这样即使系统出现故障,也不会导致数据的丢失。
cache中的数据并不是无限增长的,有一个maxSize参数用于控制当cache中的数据占用多少内存后就会将数据写入tsm文件。
每当cache中的数据达到阀值后,会将当前的cache进行一次快照,之后清空当前cache中的内容,再创建一个新的wal文件用于写入,
剩下的wal文件最后会被删除,快照中的数据会经过排序写入一个新的tsm文件中。
如果不配置的话,默认上限为25MB。
2)WAL:
wal文件的内容与内存中的cache相同,其作用就是为了持久化数据,当系统崩溃后可以通过wal文件恢复还没有写入到tsm文件中的数据。
3)TSM File:
单个tsm file大小最大为2GB,用于存放数据。
4)Compactor:
compactor组件在后台持续运行,每隔1秒会检查一次是否有需要压缩合并的数据。
主要进行两种操作,一种是cache中的数据大小达到阀值后,进行快照,之后转存到一个新的tsm文件中。
另外一种就是合并当前的tsm文件,将多个小的tsm文件合并成一个,使每一个文件尽量达到单个文件的最大大小,减少文件的数量,并且一些数据的删除操作也是在这个时候完成。
【存储目录】
InfluxDB的数据存储主要有三个目录。默认情况下是meta、wal以及data三个目录。
InfluxDB安装之后的路径为:/var/lib/influxdb
存储路径可以通过/etc/influxdb/influxdb.conf里面修改,详细请参考后面的配置文件章节。
(可以通过tree命令查看结构,使用yum install tree命令来安装)
1、meta
存储数据库的一些元数据,meta目录下有一个meta.db文件。

[root@vm1 influxdb]# tree meta
meta
└── meta.db
2、wal
存放预写日志文件,以.wal结尾。

[root@vm1 influxdb]# tree wal
wal
├── _internal
│ └── monitor
│ ├── 1
│ │ └── _00004.wal
│ └── 3
│ ├── _00005.wal
│ └── _00006.wal
├── test1
│ ├── autogen
│ │ └── 4
│ │ └── _00002.wal
│ └── test1_rp
│ ├── 5
│ │ └── _00002.wal
│ ├── 6
│ │ └── _00002.wal
│ ├── 7
│ │ └── _00002.wal
│ ├── 8
│ │ └── _00002.wal
│ └── 9
│ └── _00002.wal
└── testdb
└── autogen
└── 2
16 directories, 9 files
3、data
存放实际存储的数据文件,以.tsm结尾。
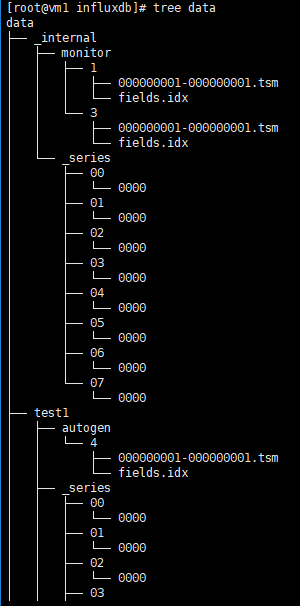
[root@vm1 influxdb]# tree data
data
├── _internal
│ ├── monitor
│ │ ├── 1
│ │ │ ├── 000000001-000000001.tsm
│ │ │ └── fields.idx
│ │ └── 3
│ │ ├── 000000001-000000001.tsm
│ │ └── fields.idx
│ └── _series
│ ├── 00
│ │ └── 0000
│ ├── 01
│ │ └── 0000
│ ├── 02
│ │ └── 0000
│ ├── 03
│ │ └── 0000
│ ├── 04
│ │ └── 0000
│ ├── 05
│ │ └── 0000
│ ├── 06
│ │ └── 0000
│ └── 07
│ └── 0000
├── test1
│ ├── autogen
│ │ └── 4
│ │ ├── 000000001-000000001.tsm
│ │ └── fields.idx
│ ├── _series
│ │ ├── 00
│ │ │ └── 0000
│ │ ├── 01
│ │ │ └── 0000
│ │ ├── 02
│ │ │ └── 0000
│ │ ├── 03
│ │ │ └── 0000
│ │ ├── 04
│ │ │ └── 0000
│ │ ├── 05
│ │ │ └── 0000
│ │ ├── 06
│ │ │ └── 0000
│ │ └── 07
│ │ └── 0000
│ └── test1_rp
│ ├── 5
│ │ ├── 000000001-000000001.tsm
│ │ └── fields.idx
│ ├── 6
│ │ ├── 000000001-000000001.tsm
│ │ └── fields.idx
│ ├── 7
│ │ ├── 000000001-000000001.tsm
│ │ └── fields.idx
│ ├── 8
│ │ ├── 000000001-000000001.tsm
│ │ └── fields.idx
│ └── 9
│ ├── 000000001-000000001.tsm
│ └── fields.idx
└── testdb
├── autogen
│ └── 2
│ ├── 000000001-000000001.tsm
│ └── fields.idx
└── _series
├── 00
│ └── 0000
├── 01
│ └── 0000
├── 02
│ └── 0000
├── 03
│ └── 0000
├── 04
│ └── 0000
├── 05
│ └── 0000
├── 06
│ └── 0000
└── 07
└── 0000
43 directories, 42 files
上面几张图中,_internal为数据库名,monitor为存储策略名称,再下一层目录中的以数字命名的目录是shard的ID值。
【Retention Policy(保留策略)】
主要包括数据保留时间和备份个数两个信息,
但是,备份个数只针对于集群机器,对于单点模式不起作用,需要设置为1。
每个数据库刚开始会自动创建一个默认的存储策略,策略名为autogen,数据保留时间为永久(0s)。
在集群中的副本个数为1,之后用户可以自己设置(查看、新建、修改、删除),例如保留最近2小时的数据。
插入和查询数据时如果不指定存储策略,则使用默认存储策略,且默认存储策略可以修改。
InfluxDB会定期清除过期的数据。每个数据库可以有多个过期策略。
建议在数据库建立的时候设置存储策略,不建议设置过多且随意切换。
我们尝试通过命令行查看一下retnetion policy。命令:show retention policies on test1
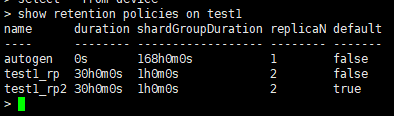
可以从结果中还可以看到一个有意思的关键字:ShardGroup
假设保留1个月数据,ShardGroup作用就是按某一个时间间隔来归档这些数据,
比如按日归档,就是1号数据是一个ShardGroup1,2号数据是ShardGroup2。
| RP Duration | Shard Group Duration |
| <2days | 1 hour |
| >=2days and <= 6 months | 1 day |
| >6 months | 7 days |
Shard是真正存储数据的,对于ShardGroup还需要按照series来划分,每一个Shard负责存储一些Series的信息,
比如ShardGroup1下面有个Shard1,负责存储seriesA和seriesB的数据,那么此时Shard1里面数据就是seriesA和seriesB在1号的数据。
【SQL语句】
==进入命令行==
命令:influx

==显示数据库==
命令:show databases
==新建数据库==
命令:create database testdb

==查看retention policy(数据保存策略)==
Retention是基于数据库的。如果没有自定义,那么都有一个默认的值。
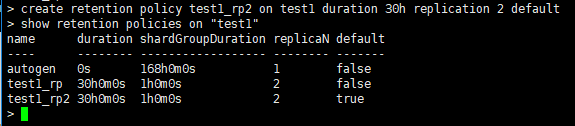
命令:show retention policies on test1
==创建retention policy==
CREATE RETENTION POLICY <retention_policy_name> ON <database> DURATION <duration> REPLICATION <n> [DEFAULT]
1)<retention_policy_name>:策略名称。
2)<datbase>:数据库名称。 retention策略是基于数据库的。此属性为必填项,所以Retention policy只针对某一个数据库进行创建的,不支持对全量的配置(对所有数据库都生效)。
3)<duration>:时间长度。
- m:分钟
- h:小时
- d:天数
- w:周
4)<n>:备份的份数。
5)DEFAULT:用来把当前策略设置为默认策略。
如:对数据库test1增加一个留存策略,策略名叫test1_rp3,数据保存10天,数据备份1份
命令:create retention policy test1_rp3 on test1 duration 10d replication 1 default

==修改retention policy==
ALTERRETENTIONPOLICY <retention_policy_name> ON <database> DURATION <duration> REPLICATION <n> [DEFAULT]
1)只更新是否为默认策略。如:将策略test1_rp作为库test1的默认策略
命令:alter retention policy "test1_rp" on "test1" DEFAULT

2)只更新保存时间。如:将策略test1_rp的保存时间变更为31天(31d×24h=744h0m0s)
命令:alter retention policy "test1_rp" on "test1" duration 31d
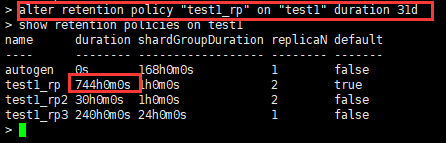
3)至更新备份数。如:将策略test1_rp的数据被分数变更为1。
命令:alter retention policy test1_rp on test1 replication 1 default

==删除retention policy==
DROPRETENTIONPOLICY <retention_policy_name> ON <database>
如删除数据库test1中名字叫做test1_rp的策略。
命令:drop retention policy test1_rp on test1

==删除数据库==
命令:drop database testdb
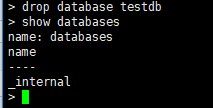
==使用数据库==
命令:use testdb
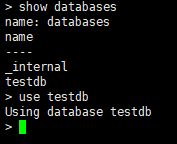
==显示所有表==
命令:show measurements

==创建measurement==
insert myapp,host=127.0.0.1,service=app.service.index qps=1340,rt=1313,cpu=45.23,mem="4145m",load=1.21
insert <表名>,hostname=<索引(tag)>,value=<记录值(field)> <时间戳>

==删除表==
命令:drop measurement myapp
==查询一个表中所有数据==
查询语句格式:
select * from measurement_name [WHERE <tag_key> <operator>] [limit xx] 查看数据
show series [on dbname] [from measurement] [WHERE <tag_key> <operator>] [limit xx] 查看series信息
show tag keys [on dbname] [from measurement] [WHERE <tag_key> <operator>] [limit xx] 查看tag keys信息
show field keys [on dbname] [from measurement] 查看field keys
select <fields> from <tbname> [ into_clause ] [ where_clause ] [ group_by_clause ] [ order_by_clause ] [ limit_clause ] [ offset_clause ] [ slimit_clause ] [ soffset_clause ]
fields : 要查询的字段,查询全部可以用*
tbname : 数据表名称
into_clause : select ... into (可选)
where_clause : where条件域(可选)
group_by_clause : group by相关(可选)
order_by_clause : order by相关(可选)
limit_clause : limit相关(可选)
offset_clause : offset相关(可选)
slimit_clause : slimit相关(可选)
soffset_clause : soffset相关(可选)
命令:select * from myapp

==查看数据库中所有记录==
通过”/.*/”表示所有的表。
命令:select * from /.*/
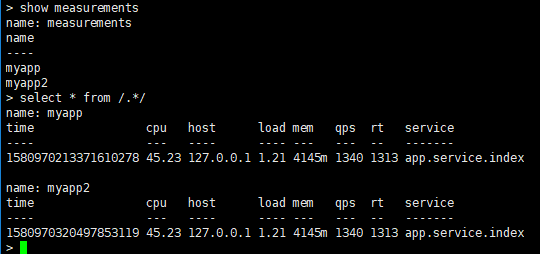
==根据tag-key查询==
查询数据时,都是按照tag-key进行查询,因为tag-key是存在索引的。
命令:select * from device where deviceName = 'sensor_1'

==更新数据==
tags 和 timestamp相同时数据会执行覆盖操作,相当于InfluxDB的更新操作。
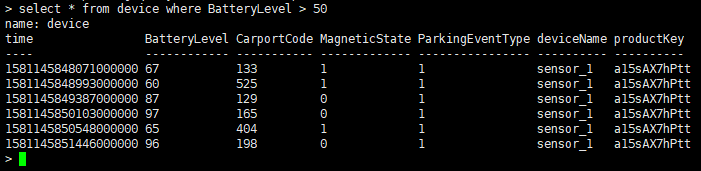
==根据field-key进行查询==
命令:select * from device where BatteryLevel > 50
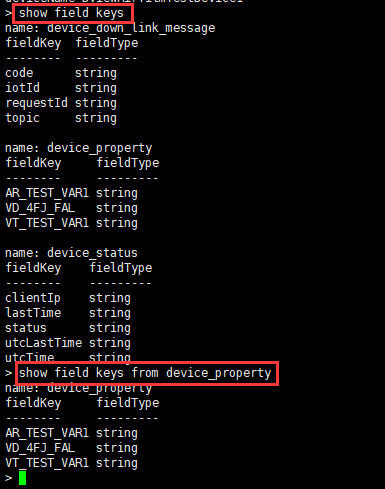
==查询所有tag key==
命令:show tag keys from device_property

==查询tag value==
命令:show tag values from device_property with key="deviceName" limit 30;

==查询所有field key==
命令:show field keys
命令:show field keys from device_property
==创建连续查询==
Continuous Queries叫做“连续查询“”
influxDB的连续查询是在数据库中自动定时启动的一组语句,
InfluxDB的连续查询是在数据库中自动定时启动的一组语句,语句中必须包含 SELECT关键词和GROUP BY,time()关键词。
使用连续查询是最优的降低采样率的方式,连续查询和存储策略搭配使用将会大大降低 InfluxDB 的系统占用量。
而且使用连续查询后,数据会存放到指定的数据表中,这样就为以后统计不同精度的数据提供了方便。
当数据超过保存策略里指定的时间之后就会被删除,但是这时候可能并不想数据被完全删掉,可以使用连续查询将数据聚合储存。
/*
* 在test1库中新建了一个名为query_1m的连续查询, * 每1分钟取一个CarportCode字段的MEAN平均值、MEDIAN中位值、MAX最大值、MIN最小值
* 并将结果存储到divece_1m表中,使用的数据保留策略都是default
*/ CREATE CONTINUOUS QUERY query_1m ON test1 BEGIN SELECT MEAN(CarportCode), MEDIAN(CarportCode), MAX(CarportCode), MIN(CarportCode) INTO device_1m FROM device GROUP BY productKey,deviceName,time(1m) END
==查看连续查询==
命令:SHOW CONTINUOUS QUERIES

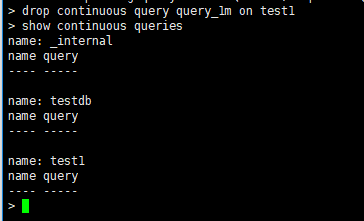
==删除连续查询==
DROP CONTINUOUS QUERY <cq_name> ON <database_name>
命令:DROP CONTINUOUS QUERY query_1m ON test1
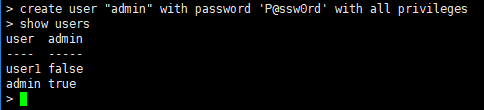
==显示用户==
命令:show users

==创建用户==
命令:create user "user1" with password 'P@ssw0rd'

==创建管理员权限用户==
命令:create user "admin" with password 'P@ssw0rd' with all privileges
==删除用户==
命令:drop user "user1"
==设置time显示格式==
在influxdb中默认会有time字段用utc形式保存,influxdb支持三种时间格式
1)epoch_time格式
就是时间戳表示,我们一般使用的10位和13位,在influxdb中使用的时间戳是19位,单位是ns(纳秒)
2)rfc3339_date_time_string格式
这种格式为:
'YYYY-MM-DDTHH:MM:SS.nnnnnnnnnZ'
其中nnnnnnnnn是可选的,如果不写则会被设置为000000000。
注意,如果使用这种时间格式,需要使用单引号 ’ 将时间括起来。
3)rfc3339_like_date_time_string
这种格式:
'YYYY-MM-DD HH:MM:SS.nnnnnnnnn'
其中HH::MM:SS.nnnnnnnnn可以省略,必须用单引号包括起来。
可以通过以下命令修改客户端命令显示格式
方式1:
命令:precision rfc3339

方式2:
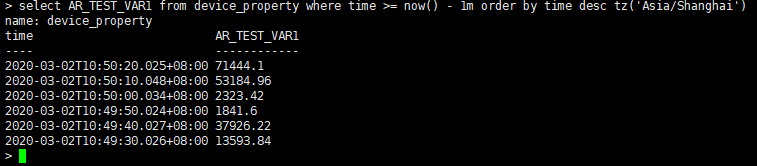
命令:select AR_TEST_VAR1 from device_property where time >= now() - 1m order by time desc tz('Asia/Shanghai')
==其他条件查询==
查询数据大于200的。 select * from device where CarportCode > 300 实现查询以给定字段开始的数据 select fieldName from measurementName where fieldName=~/^给定字段/ 实现查询以给定字段结束的数据 select fieldName from measurementName where fieldName=~/给定字段$/ 实现查询包含给定字段数据 select fieldName from measurementName where fieldName=~/给定字段/ 按照30m分钟进行聚合,时间范围是大于昨天的 主机名是server1的。 select mean(value) from cpu_idle group by time(30m) where time > now() – 1d and hostName = ‘server1′ limit 1000
==influx -execute==
类似 mysql -e 的功能
命令:influx -execute 'show databases' -format=column

其中-format可以为csv、json、column(默认)
==常用函数==
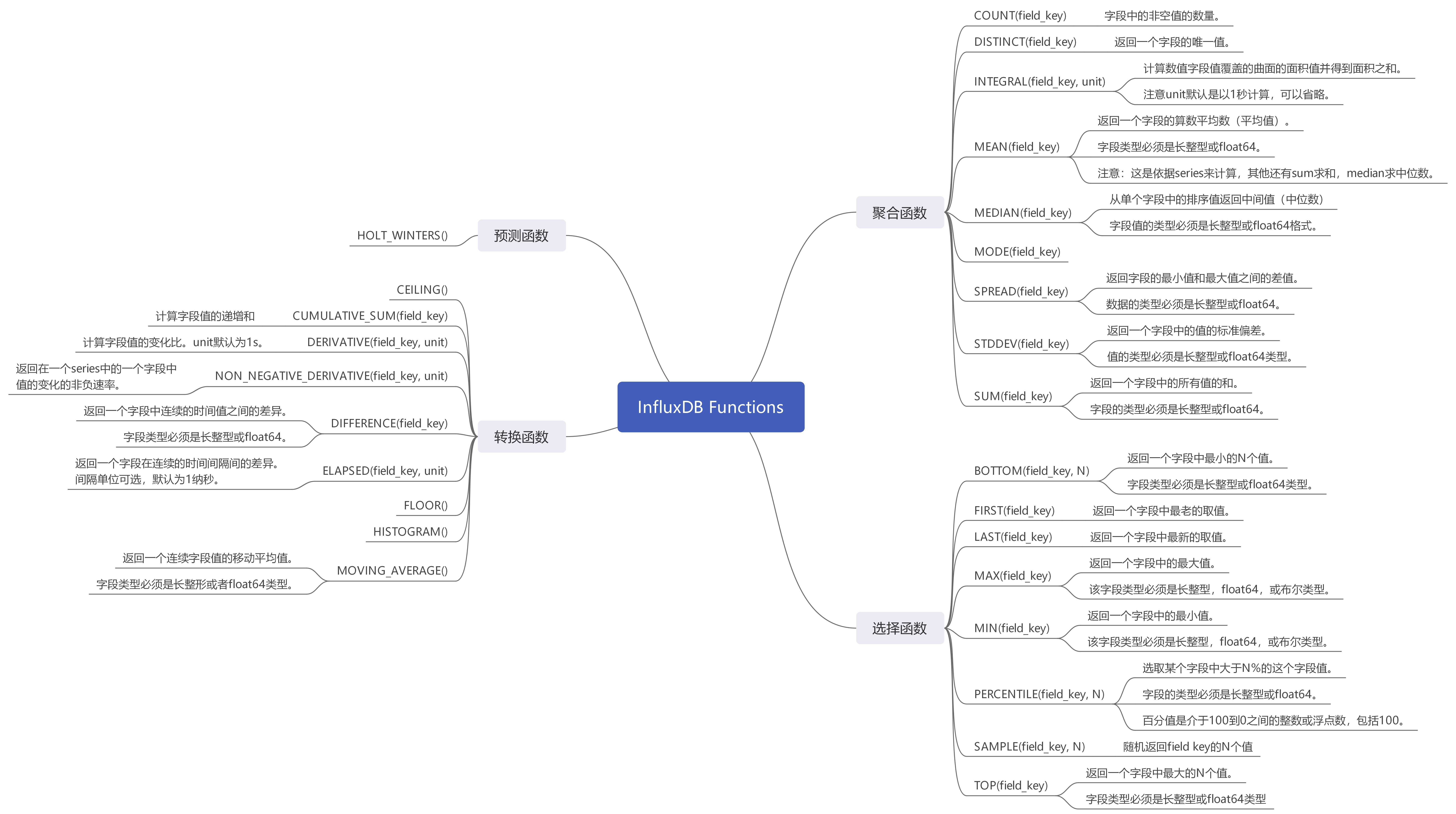
推荐几个网友整理的博客:
https://blog.csdn.net/zx711166/article/details/84541198
==几个典型语句样例==
数据准备:
time BatteryLevel CarportCode MagneticState ParkingEventType deviceName productKey ---- ------------ ----------- ------------- ---------------- ---------- ---------- 1581145848071000000 67 133 1 1 sensor_1 a15sAX7hPtt 1581145848537000000 36 149 1 1 sensor_1 a15sAX7hPtt 1581145848993000000 60 525 1 1 sensor_1 a15sAX7hPtt 1581145849387000000 87 129 0 1 sensor_1 a15sAX7hPtt 1581145849725000000 7 934 0 1 sensor_1 a15sAX7hPtt 1581145850103000000 97 165 0 1 sensor_1 a15sAX7hPtt 1581145850548000000 65 404 1 1 sensor_1 a15sAX7hPtt 1581145851141000000 26 737 0 1 sensor_1 a15sAX7hPtt 1581145851446000000 96 198 0 1 sensor_1 a15sAX7hPtt 1581145852001000000 21 389 1 1 sensor_1 a15sAX7hPtt 1581148921828000000 63 270 1 0 sensor_1 a15sAX7hPtt 1581148922471000000 60 983 0 0 sensor_1 a15sAX7hPtt 1581148922825000000 88 379 1 0 sensor_1 a15sAX7hPtt 1581148923502000000 27 144 0 0 sensor_1 a15sAX7hPtt 1581148947163000000 89 648 1 0 sensor_1 a15sAX7hPtt 1581149039657000000 19 172 1 0 sensor_1 a15sAX7hPtt 1581149040068000000 10 77 1 0 sensor_1 a15sAX7hPtt 1581149040340000000 89 158 1 0 sensor_1 a15sAX7hPtt 1581154727654000000 75 556 0 0 sensor_1 a15sAX7hPtt 1581154730202000000 64 782 0 0 sensor_1 a15sAX7hPtt 1581154730538000000 78 776 1 0 sensor_1 a15sAX7hPtt
1)返回从现在开始3小时以内数据中CarportCode字段的平均值
语句: select mean(CarportCode) from device where time >= now() - 180m
2)按照东八区的时间显示
select * from device_data_up order by time desc limit 10 tz('Asia/Shanghai')
【配置文件】
配置文件路径:/etc/influxdb/influxdb.conf
全局配置
reporting-disabled = false # 该选项用于上报influxdb的使用信息给InfluxData公司,默认值为false bind-address = ":8088" # 备份恢复时使用,默认值为8088
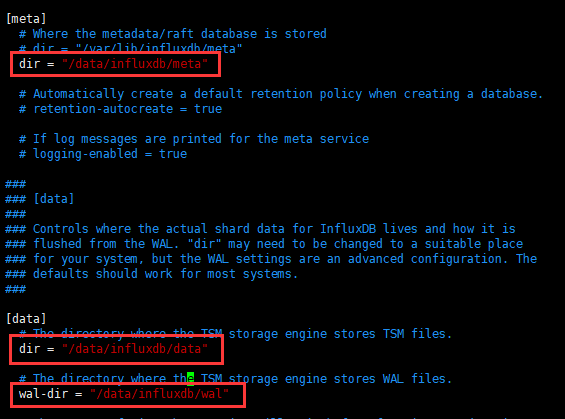
1、meta
[meta] dir = "/var/lib/influxdb/meta" # meta数据存放目录 retention-autocreate = true # 用于控制默认存储策略,数据库创建时,会自动生成autogen的存储策略,默认值:true logging-enabled = true # 是否开启meta日志,默认值:true
2、data
[data] dir = "/var/lib/influxdb/data" # 最终数据(TSM文件)存储目录 wal-dir = "/var/lib/influxdb/wal" # 预写日志存储目录 query-log-enabled = true # 是否开启tsm引擎查询日志,默认值: true cache-max-memory-size = 1048576000 # 用于限定shard最大值,大于该值时会拒绝写入,默认值:1000MB,单位:byte cache-snapshot-memory-size = 26214400 # 用于设置快照大小,大于该值时数据会刷新到tsm文件,默认值:25MB,单位:byte cache-snapshot-write-cold-duration = "10m" # tsm引擎 snapshot写盘延迟,默认值:10Minute compact-full-write-cold-duration = "4h" # tsm文件在压缩前可以存储的最大时间,默认值:4Hour max-series-per-database = 1000000 # 限制数据库的级数,该值为0时取消限制,默认值:1000000 max-values-per-tag = 100000 # 一个tag最大的value数,0取消限制,默认值:100000
3、coordinator
查询管理的配置选项
[coordinator] write-timeout = "10s" # 写操作超时时间,默认值: 10s max-concurrent-queries = 0 # 最大并发查询数,0无限制,默认值: 0 query-timeout = "0s # 查询操作超时时间,0无限制,默认值:0s log-queries-after = "0s" # 慢查询超时时间,0无限制,默认值:0s max-select-point = 0 # SELECT语句可以处理的最大点数(points),0无限制,默认值:0 max-select-series = 0 # SELECT语句可以处理的最大级数(series),0无限制,默认值:0 max-select-buckets = 0 # SELECT语句可以处理的最大"GROUP BY time()"的时间周期,0无限制,默认值:0
4、retention
旧数据的保留策略
[retention] enabled = true # 是否启用该模块,默认值 : true check-interval = "30m" # 检查时间间隔,默认值 :"30m"
5、shard-precreation
分区预创建
[shard-precreation] enabled = true # 是否启用该模块,默认值 : true check-interval = "10m" # 检查时间间隔,默认值 :"10m" advance-period = "30m" # 预创建分区的最大提前时间,默认值 :"30m"
6、monitor
控制InfluxDB自有的监控系统。
默认情况下,InfluxDB把这些数据写入_internal数据库,如果这个库不存在则自动创建。
_internal 库默认的retention策略是7天,如果你想使用一个自己的retention策略,需要自己创建。
[monitor] store-enabled = true # 是否启用该模块,默认值 :true store-database = "_internal" # 默认数据库:"_internal" store-interval = "10s # 统计间隔,默认值:"10s"
7、admin
web管理页面(在1.3版本之后已经没有这个配置了)
[admin] enabled = true # 是否启用该模块,默认值 : false bind-address = ":8083" # 绑定地址,默认值 :":8083" https-enabled = false # 是否开启https ,默认值 :false https-certificate = "/etc/ssl/influxdb.pem" # https证书路径,默认值:"/etc/ssl/influxdb.pem"
8、http
[http] enabled = true # 是否启用该模块,默认值 :true bind-address = ":8086" # 绑定地址,默认值:":8086" auth-enabled = false # 是否开启认证,默认值:false realm = "InfluxDB" # 配置JWT realm,默认值: "InfluxDB" log-enabled = true # 是否开启日志,默认值:true write-tracing = false # 是否开启写操作日志,如果置成true,每一次写操作都会打日志,默认值:false pprof-enabled = true # 是否开启pprof,默认值:true https-enabled = false # 是否开启https,默认值:false https-certificate = "/etc/ssl/influxdb.pem" # 设置https证书路径,默认值:"/etc/ssl/influxdb.pem" https-private-key = "" # 设置https私钥,无默认值 shared-secret = "" # 用于JWT签名的共享密钥,无默认值 max-row-limit = 0 # 配置查询返回最大行数,0无限制,默认值:0 max-connection-limit = 0 # 配置最大连接数,0无限制,默认值:0 unix-socket-enabled = false # 是否使用unix-socket,默认值:false bind-socket = "/var/run/influxdb.sock" # unix-socket路径,默认值:"/var/run/influxdb.sock"
9、logging
[logging] format = "auto" # 确定要为日志使用哪个日志编码器。可用选项auto、logfmt、json level = "info" # 确定将发出的日志级别。可用选项error、warn、info、debug suppress-logo = false # 取消启动程序时打印logo输出
10、subscriber
控制Kapacitor接受数据的配置
[subscriber] enabled = true # 是否启用该模块,默认值 :true http-timeout = "30s" # http超时时间,默认值:"30s" insecure-skip-verify = false # 是否允许不安全的证书 ca-certs = "" # 设置CA证书 write-concurrency = 40 # 设置并发数目,默认值:40 write-buffer-size = 1000 # 设置buffer大小,默认值:1000
11、graphite
[[graphite]] enabled = false # 是否启用该模块,默认值 :false database = "graphite" # 数据库名称,默认值:"graphite" retention-policy = "" # 存储策略,无默认值 bind-address = ":2003" # 绑定地址,默认值:":2003" protocol = "tcp" # 协议,默认值:"tcp" consistency-level = "one" # 一致性级别,默认值:"one batch-size = 5000 # 批量size,默认值:5000 batch-pending = 10 # 配置在内存中等待的batch数,默认值:10 batch-timeout = "1s" # 超时时间,默认值:"1s" udp-read-buffer = 0 # udp读取buffer的大小,0表示使用操作系统提供的值,如果超过操作系统的默认配置则会出错。 该配置的默认值:0 separator = "." # 多个measurement间的连接符,默认值: "."
12、collectd
[[collectd]] enabled = false # 是否启用该模块,默认值 :false bind-address = ":25826" # 绑定地址,默认值: ":25826" database = "collectd" # 数据库名称,默认值:"collectd" retention-policy = "" # 存储策略,无默认值 typesdb = "/usr/local/share/collectd" # 路径,默认值:"/usr/share/collectd/types.db" auth-file = "/etc/collectd/auth_file" batch-size = 5000 batch-pending = 10 batch-timeout = "10s" read-buffer = 0 # udp读取buffer的大小,0表示使用操作系统提供的值,如果超过操作系统的默认配置则会出错。默认值:0
13、opentsdb
[[opentsdb]] enabled = false # 是否启用该模块,默认值:false bind-address = ":4242" # 绑定地址,默认值:":4242" database = "opentsdb" # 默认数据库:"opentsdb" retention-policy = "" # 存储策略,无默认值 consistency-level = "one" # 一致性级别,默认值:"one" tls-enabled = false # 是否开启tls,默认值:false certificate= "/etc/ssl/influxdb.pem" # 证书路径,默认值:"/etc/ssl/influxdb.pem" log-point-errors = true # 出错时是否记录日志,默认值:true batch-size = 1000 batch-pending = 5 batch-timeout = "1s"
14、udp
[[udp]] enabled = false # 是否启用该模块,默认值:false bind-address = ":8089" # 绑定地址,默认值:":8089" database = "udp" # 数据库名称,默认值:"udp" retention-policy = "" # 存储策略,无默认值 batch-size = 5000 batch-pending = 10 batch-timeout = "1s" read-buffer = 0 # udp读取buffer的大小,0表示使用操作系统提供的值,如果超过操作系统的默认配置则会出错。 该配置的默认值:0
15、continuous_queries
[continuous_queries] enabled = true # enabled 是否开启CQs,默认值:true log-enabled = true # 是否开启日志,默认值:true run-interval = "1s" # 时间间隔,默认值:"1s"
16、tls
# 确定可用的密码套件集。 ciphers = [ "TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305", "TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256", ] min-version = "tls1.2" # tls协议的最小版本。 max-version = "tls1.2" # tls协议的最大版本。
【Java程序样例】
我个人的样例:
https://github.com/quchunhui/demo-macket/tree/master/influxdb
官方上的样例:
https://github.com/influxdata/influxdb-client-java/tree/master/examples/src/main/java/example
https://github.com/influxdata/influxdb-java
【优化策略】
-
控制series的数量;
-
使用批量写;
-
使用恰当的时间粒度;
-
存储的时候尽量对Tag进行排序;
-
根据数据情况,调整shard的duration;
-
无关的数据写不同的database;
-
控制Tag Key与Tag Value值的大小;
-
存储分离,将wal目录与data目录分别映射到不同的磁盘上,以减少读写操作的相互影响。
【遇到的问题】
==问题1==
需要修改一下InfluxDB默认的存储路径,根据上面的配置文件,对/etc/influxdb/influxdb.conf文件修改了3个地方
命令:vim /etc/influxdb/influxdb.conf
结果InfluxDB重新启动的时候,就报错了:

查看一下错误日志
命令:less /var/log/messages
Feb 28 19:50:21 rexel-ids003 influxd[28635]: ts=2020-02-28T11:50:21.058077Z lvl=info msg="InfluxDB starting" log_id=0LEuyxWW000 version=1.7.1 branch=1.7 commit=cb03c542a4054f0f4d3dc13919d31c456bdb5c39 Feb 28 19:50:21 rexel-ids003 influxd[28635]: ts=2020-02-28T11:50:21.058101Z lvl=info msg="Go runtime" log_id=0LEuyxWW000 version=go1.11 maxprocs=4 Feb 28 19:50:21 rexel-ids003 influxd[28635]: run: create server: mkdir all: mkdir /home/radmin/data: permission denied Feb 28 19:50:21 rexel-ids003 systemd[1]: influxdb.service: Main process exited, code=exited, status=1/FAILURE Feb 28 19:50:21 rexel-ids003 systemd[1]: influxdb.service: Failed with result 'exit-code'. Feb 28 19:50:21 rexel-ids003 systemd[1]: influxdb.service: Service RestartSec=100ms expired, scheduling restart. Feb 28 19:50:21 rexel-ids003 systemd[1]: influxdb.service: Scheduled restart job, restart counter is at 5. Feb 28 19:50:21 rexel-ids003 systemd[1]: Stopped InfluxDB is an open-source, distributed, time series database. Feb 28 19:50:21 rexel-ids003 systemd[1]: influxdb.service: Start request repeated too quickly. Feb 28 19:50:21 rexel-ids003 systemd[1]: influxdb.service: Failed with result 'exit-code'. Feb 28 19:50:21 rexel-ids003 systemd[1]: Failed to start InfluxDB is an open-source, distributed, time series database.
从日志中可以看到关键字“permission denied”,证明是没有这个目录权限。
解决步骤:
1、先查看一下InfluxDB所属的文件目录及权限
命令:rpm -ql influxdb
可以看到InfluxDB所持有权限的路径只有一下这些,我自己建的路径根本就没有权限。

2、查看一下InfluxDB的启动信息
命令:cat /usr/lib/influxdb/scripts/influxdb.service
可以看到,InfluxDB是的启动用户是influxdb,我这边是用root账户操作的。
3、修改一下目标文件夹及子文件夹的权限。
命令:chown -R influxdb:influxdb influx

4、重新启动就可以了。
【性能测试工具】
==influx_stress==
可以使用性能测试工具influx_stress进行性能测试。
如命令:influx_stress -addr http://XXX.XX.XXX.X:8086

【用户权限管理】
我们的InfluxDB部署在阿里云ECS服务器上,开放了公网地址,由于没有做权限限制,阿里云提示“InfluxDB未授权访问漏洞”

所以需要为InfluxDB增加用户权限
具体可以参考官网:
https://docs.influxdata.com/influxdb/v1.7/administration/authentication_and_authorization/
1、开启HTTP访问权限
编译配置文件。命令:vim /etc/influxdb/influxdb.conf
我修改了3个配置,其中bind-address是顺手修改了一下默认端口,提升一下安全。
记得修改之后,重启一下InfluxDB,重启命令:service influxdb restart
enabled = true auth-enabled = true bind-address = ":9100"

2、增加用户权限
相关命令如下:
创建一个新的管理员用户:CREATE USER <username> WITH PASSWORD '<password>' WITH ALL PRIVILEGES 为一个已有用户授权管理员权限:GRANT ALL PRIVILEGES TO <username> 展示用户及其权限:SHOW USERS 取消用户权限:REVOKE ALL PRIVILEGES FROM <username> 创建一个新的普通用户:CREATE USER <username> WITH PASSWORD '<password>' 为一个已有用户授权:GRANT [READ,WRITE,ALL] ON <database_name> TO <username> 取消权限:REVOKE [READ,WRITE,ALL] ON <database_name> FROM <username> 展示用户在不同数据库上的权限:SHOW GRANTS FOR <username> 重设密码:SET PASSWORD FOR <username> = '<password>' 删除用户:DROP USER <username>
我这里设置了4个用户,分别如下

3、修改相关客户端代码
修改访问InfluxDB客户端代码的相关配置即可。
==END==
enabled = true