synchronized作用在静态方法时,锁住整个类;
synchronized作用在方法上时,锁住整个对象;
synchronized作用于某一个对象实例时,所著的便是对应的代码块。
一、Java对象头
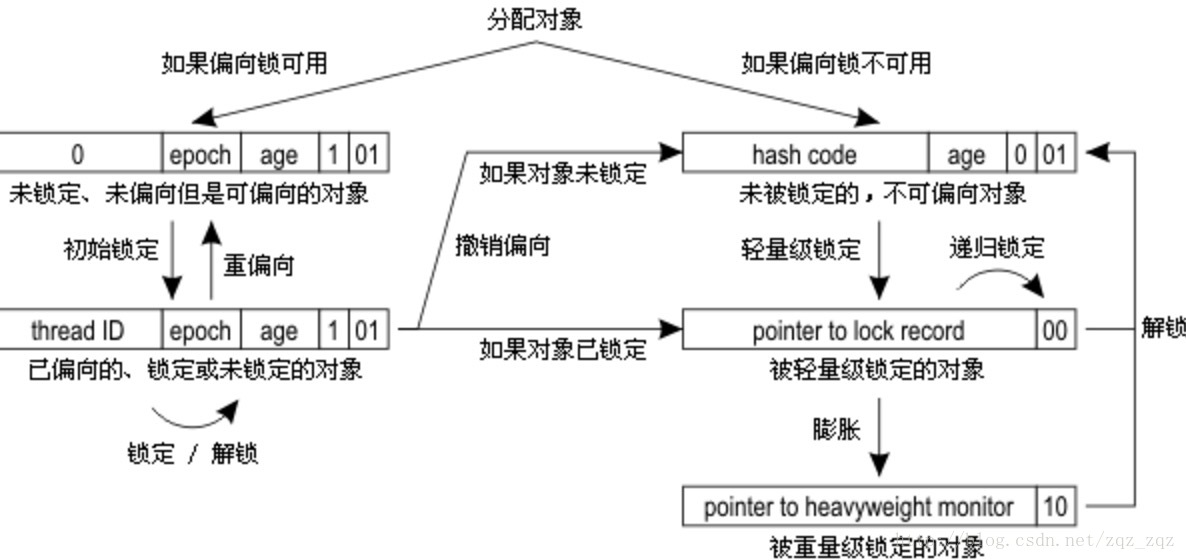
对象头包含两部分:Mark Word 和 Class Metadata Address 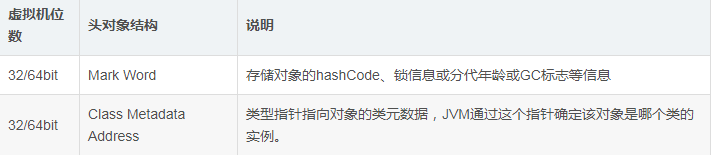
其中Mark Word在默认情况下存储着对象的HashCode、分代年龄、锁标记位等以下是32位JVM的Mark Word默认存储结构。32位虚拟机在不同状态下markword结构如下图所示:
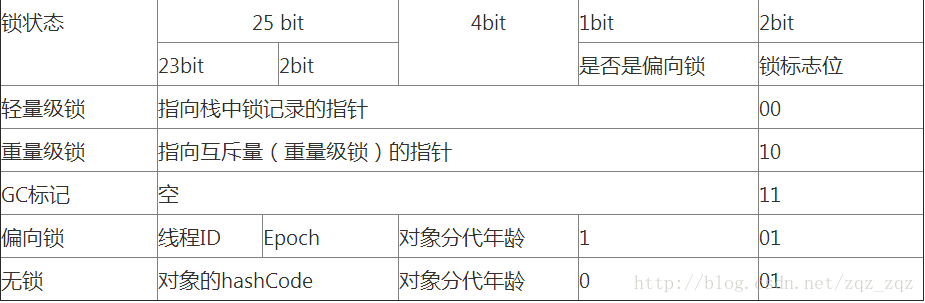
| 状态 | 标志位 | 存储内容 |
|---|---|---|
| 未锁定 | 01 | 对象哈希码、对象分代年龄 |
| 轻量级锁定 | 00 | 指向锁记录的指针 |
| 膨胀(重量级锁定) | 10 | 执行重量级锁定的指针 |
| GC标记 | 11 | 空(不需要记录信息) |
| 可偏向 | 01 | 偏向线程ID、偏向时间戳、对象分代年龄 |
二、重量级锁synchronized的实现
重量级锁(synchronized的对象锁),锁标识位为10,其中指针指向的是monitor对象(也称为管程或监视器锁)的起始地址。每个对象都存在着一个 monitor 与之关联,对象与其 monitor 之间的关系有存在多种实现方式,如monitor可以与对象一起创建销毁或当线程试图获取对象锁时自动生成,但当一个 monitor 被某个线程持有后,它便处于锁定状态。
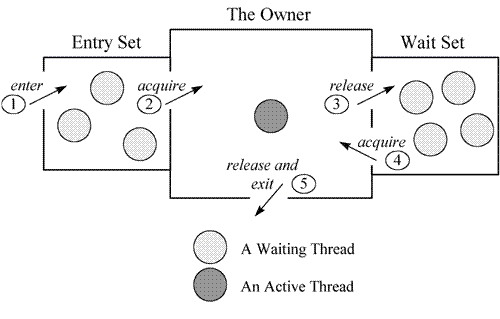
上图简单描述多线程获取锁的过程,当多个线程同时访问一段同步代码时,首先会进入 Entry Set。当线程获取到对象的monitor 后进入 The Owner 区域并把monitor中的owner变量设置为当前线程,同时monitor中的计数器count加1,若线程调用 wait() 方法,将释放当前持有的monitor,owner变量恢复为null,count自减1,同时该线程进入 WaitSet集合中等待被唤醒。若当前线程执行完毕也将释放monitor(锁)并复位变量的值,以便其他线程进入获取monitor(锁)。
由此看来,monitor对象存在于每个Java对象的对象头中(存储的指针的指向),synchronized锁便是通过这种方式获取锁的,也是为什么Java中任意对象可以作为锁的原因,同时也是notify/notifyAll/wait等方法存在于顶级对象Object中的原因。
三、自旋锁与自适应自旋
Java的线程是映射到操作系统的原生线程之上的,如果要阻塞或唤醒一个线程,都需要操作系统来帮忙完成,这就需要从用户态转换到核心态中,因此状态转换需要耗费很多的处理器时间,对于代码简单的同步块(如被synchronized修饰的getter()和setter()方法),状态转换消耗的时间有可能比用户代码执行的时间还要长。
虚拟机的开发团队注意到在许多应用上,共享数据的锁定状态只会持续很短的一段时间,为了这段时间去挂起和恢复线程并不值得。如果物理机器有一个以上的处理器,能让两个或以上的线程同时并行执行,我们就可以让后面请求锁的那个线程“稍等一下“,但不放弃处理器的执行时间,看看持有锁的线程是否很快就会释放锁。为了让线程等待,我们只需让线程执行一个忙循环(自旋),这项技术就是所谓的自旋锁。
自旋锁在JDK1.4.2中引入,使用-XX:+UseSpinning来开启。JDK1.6中已经变为默认开。自旋等待不能代替阻塞。自旋等待本身虽然避免了线程切换的开销,但它是要占用处理器时间的,因此,如果锁被占用的时间很短,自旋等待的效果就会非常好,反之,如果锁被占用的时间很长,那么自旋的线程只会浪费处理器资源。因此,自旋等待的时间必须要有一定的限度,如果自旋超过了限定次数(默认是10次,可以使用-XX:PreBlockSpin来更改)没有成功获得锁,就应当使用传统的方式去挂起线程了。
JDK1.6中引入自适应的自旋锁,自适应意味着自旋的时间不在固定。而是有虚拟机对程序锁的监控与预测来设置自旋的次数。
自旋是在轻量级锁中使用的。
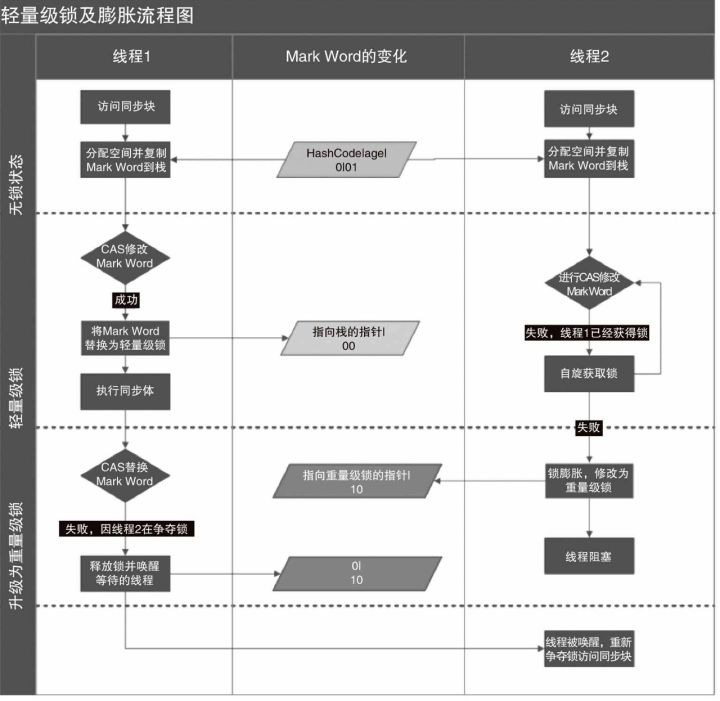
四、轻量级锁
· 轻量级锁提升程序同步性能的依据是:对于绝大部分的锁,在整个同步周期内都是不存在竞争的(区别于偏向锁)。这是一个经验数据。如果没有竞争,轻量级锁使用CAS操作避免了使用互斥量的开销,但如果存在锁竞争,除了互斥量的开销外,还额外发生了CAS操作,因此在有竞争的情况下,轻量级锁比传统的重量级锁更慢。
轻量级锁加锁过程:
1.在代码进入同步块的时候,如果同步对象锁状态为无锁状态(锁标志位为“01”状态,是否为偏向锁为“0”),虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的Mark Word的拷贝,官方称之为 Displaced Mark Word。这时候线程堆栈与对象头的状态如图:
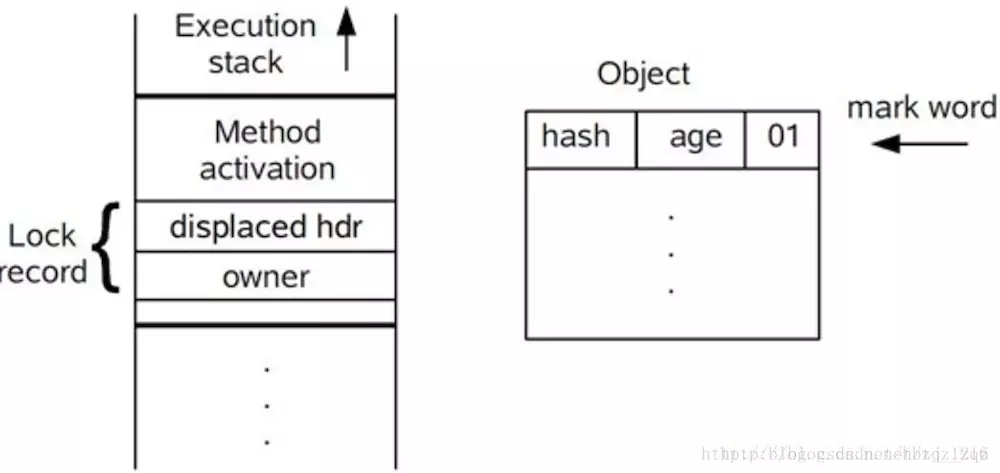
2. 拷贝对象头中的Mark Word复制到锁记录(Lock Record)中;
3. 拷贝成功后,虚拟机将使用CAS操作尝试将锁对象的Mark Word更新为指向Lock Record的指针,并将线程栈帧中的Lock Record里的owner指针指向Object的 Mark Word。
4. 如果这个更新动作成功了,那么这个线程就拥有了该对象的锁,并且对象Mark Word的锁标志位设置为“00”,即表示此对象处于轻量级锁定状态,这时候线程堆栈与对象头的状态如图所示。
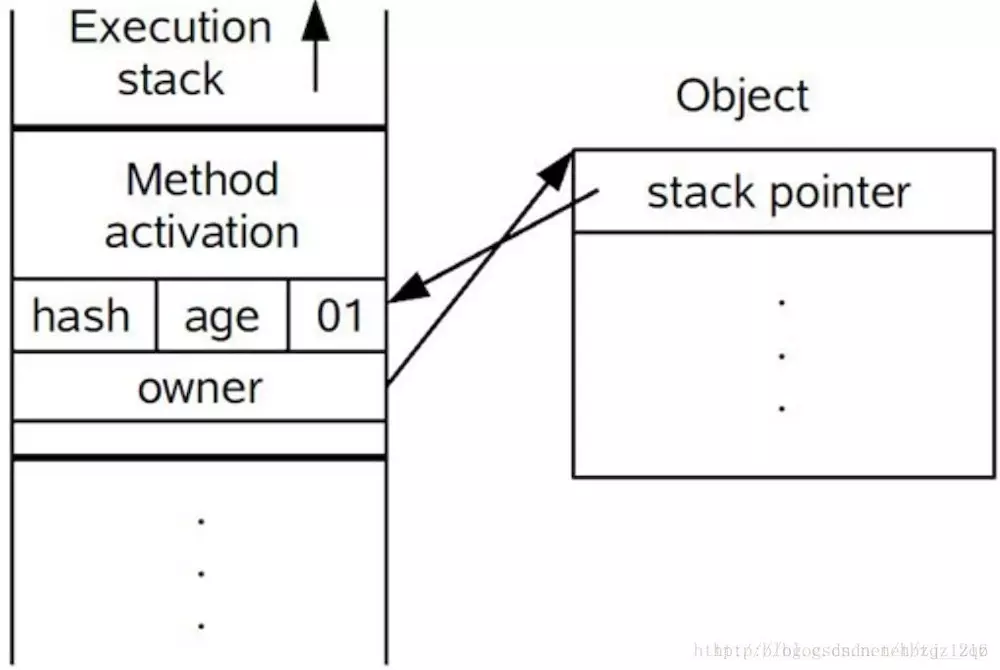
5. 如果这个更新操作失败了,虚拟机首先会检查对象的Mark Word是否指向当前线程的栈帧,如果是就说明当前线程已经拥有了这个对象的锁,那就可以直接进入同步块继续执行。否则说明多个线程竞争锁,轻量级锁就要膨胀为重量级锁,锁标志的状态值变为“10”,Mark Word中存储的就是指向重量级锁(互斥量)的指针,后面等待锁的线程也要进入阻塞状态。
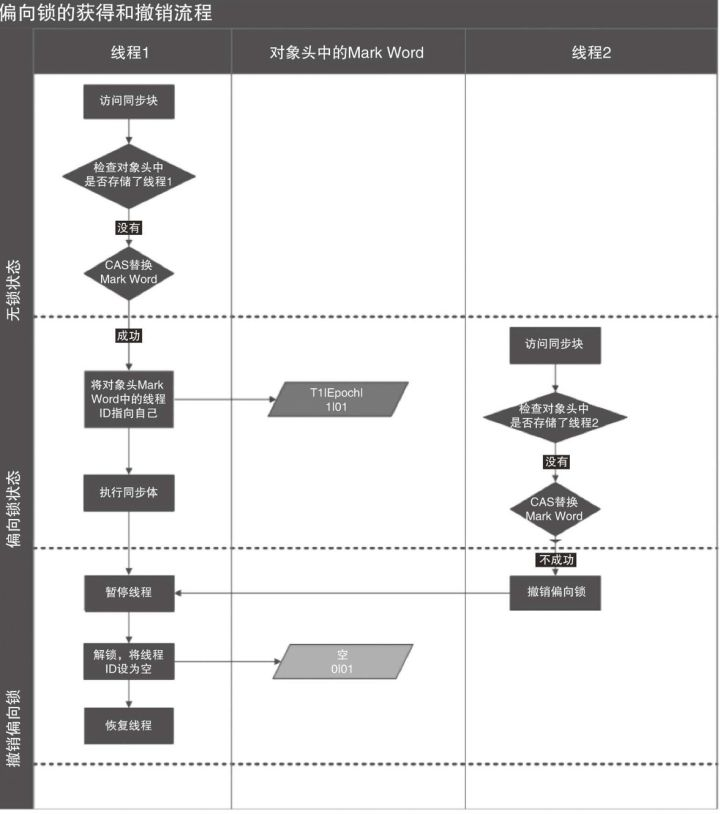
五、偏向锁
偏向锁是JDK6中引入的一项锁优化,它的目的是消除数据在无竞争情况下的同步原语,进一步提高程序的运行性能。
偏向锁会偏向于第一个获得它的线程,如果在接下来的执行过程中,该锁没有被其他的线程获取,则持有偏向锁的线程将永远不需要同步。大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低而引入了偏向锁。
当锁对象第一次被线程获取的时候,线程使用CAS操作把这个线程的ID记录在对象Mark Word之中,同时置偏向标志位1。以后该线程在进入和退出同步块时不需要进行CAS操作来加锁和解锁,只需要简单地测试一下对象头的Mark Word里是否存储着指向当前线程的ID。如果测试成功,表示线程已经获得了锁。
当有另外一个线程去尝试获取这个锁时,偏向模式就宣告结束。根据锁对象目前是否处于被锁定的状态,撤销偏向后恢复到未锁定或轻量级锁定状态。
六、总结
synchronized的执行过程(面试就回答这个):
1. 检测Mark Word里面是不是当前线程的ID,如果是,表示当前线程处于偏向锁
2. 如果不是,则使用CAS将当前线程的ID替换Mard Word,如果成功则表示当前线程获得偏向锁,置偏向标志位1
3. 如果失败,则说明发生竞争,撤销偏向锁,进而升级为轻量级锁。
4. 当前线程使用CAS将对象头的Mark Word替换为锁记录指针,如果成功,当前线程获得锁
5. 如果失败,表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁。
6. 如果自旋成功则依然处于轻量级状态。
7. 如果自旋失败,则升级为重量级锁。
上面几种锁都是JVM自己内部实现,当我们执行synchronized同步块的时候jvm会根据启用的锁和当前线程的争用情况,决定如何执行同步操作;
在所有的锁都启用的情况下线程进入临界区时会先去获取偏向锁,如果已经存在偏向锁了,则会尝试获取轻量级锁,启用自旋锁,如果自旋也没有获取到锁,则使用重量级锁,没有获取到锁的线程阻塞挂起,直到持有锁的线程执行完同步块唤醒他们;
偏向锁是在无锁争用的情况下使用的,也就是同步开在当前线程没有执行完之前,没有其它线程会执行该同步块,一旦有了第二个线程的争用,偏向锁就会升级为轻量级锁,如果轻量级锁自旋到达阈值后,没有获取到锁,就会升级为重量级锁;
如果线程争用激烈,那么应该禁用偏向锁。
七、锁优化
以上介绍的锁不是我们代码中能够控制的,但是借鉴上面的思想,我们可以优化我们自己线程的加锁操作;
1. 减少锁的时间
不需要同步执行的代码,能不放在同步快里面执行就不要放在同步快内,可以让锁尽快释放;
2. 减少锁的粒度
它的思想是将物理上的一个锁,拆成逻辑上的多个锁,增加并行度,从而降低锁竞争。它的思想也是用空间来换时间;java中很多数据结构都是采用这种方法提高并发操作的效率
JDK 1.7 ConcurrentHashMap
Segment继承自ReenTrantLock,所以每个Segment就是个可重入锁,每个Segment 有一个HashEntry< K,V >数组用来存放数据,put操作时,先确定往哪个Segment放数据,只需要锁定这个Segment,执行put,其它的Segment不会被锁定;所以数组中有多少个Segment就允许同一时刻多少个线程存放数据,这样增加了并发能力。
LongAddr
LongAdder 实现思路也类似ConcurrentHashMap,LongAdder有一个根据当前并发状况动态改变的Cell数组,Cell对象里面有一个long类型的value用来存储值;
开始没有并发争用的时候或者是cells数组正在初始化的时候,会使用cas来将值累加到成员变量的base上,在并发争用的情况下,LongAdder会初始化cells数组,在Cell数组中选定一个Cell加锁,数组有多少个cell,就允许同时有多少线程进行修改,最后将数组中每个Cell中的value相加,在加上base的值,就是最终的值;cell数组还能根据当前线程争用情况进行扩容,初始长度为2,每次扩容会增长一倍,直到扩容到大于等于cpu数量就不再扩容,这也就是为什么LongAdder比cas和AtomicInteger效率要高的原因,后面两者都是volatile+cas实现的,他们的竞争维度是1,LongAdder的竞争维度为“Cell个数+1”为什么要+1?因为它还有一个base,如果竞争不到锁还会尝试将数值加到base上;
LinkedBlockingQueue
LinkedBlockingQueue也体现了这样的思想,在队列头入队,在队列尾出队,入队和出队使用不同的锁,相对于LinkedBlockingArray只有一个锁效率要高;
拆锁的粒度不能无限拆,最多可以将一个锁拆为当前cup数量个锁即可;
3. 锁粗化
大部分情况下我们是要让锁的粒度最小化,锁的粗化则是要增大锁的粒度; 在以下场景下需要粗化锁的粒度: 假如有一个循环,循环内的操作需要加锁,我们应该把锁放到循环外面,否则每次进出循环,都进出一次临界区,效率是非常差的;
4. 读写锁
ReentrantReadWriteLock 是一个读写锁,读操作加读锁,可以并发读,写操作使用写锁,只能单线程写;
5.读写分离
CopyOnWriteArrayList 、CopyOnWriteArraySet
CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
CopyOnWrite并发容器用于读多写少的并发场景,因为,读的时候没有锁,但是对其进行更改的时候是会加锁的,否则会导致多个线程同时复制出多个副本,各自修改各自的;
6.CAS
如果需要同步的操作执行速度非常快,并且线程竞争并不激烈,这时候使用cas效率会更高,因为加锁会导致线程的上下文切换,如果上下文切换的耗时比同步操作本身更耗时,且线程对资源的竞争不激烈,使用volatiled+cas操作会是非常高效的选择;
7.消除缓存行的伪共享
除了我们在代码中使用的同步锁和jvm自己内置的同步锁外,还有一种隐藏的锁就是缓存行,它也被称为性能杀手。 在多核cup的处理器中,每个cup都有自己独占的一级缓存、二级缓存,甚至还有一个共享的三级缓存,为了提高性能,cpu读写数据是以缓存行为最小单元读写的;32位的cpu缓存行为32字节,64位cup的缓存行为64字节,这就导致了一些问题。
例如,多个不需要同步的变量因为存储在连续的32字节或64字节里面,当需要其中的一个变量时,就将它们作为一个缓存行一起加载到某个cup-1私有的缓存中(虽然只需要一个变量,但是cpu读取会以缓存行为最小单位,将其相邻的变量一起读入),被读入cpu缓存的变量相当于是对主内存变量的一个拷贝,也相当于变相的将在同一个缓存行中的几个变量加了一把锁,这个缓存行中任何一个变量发生了变化,当cup-2需要读取这个缓存行时,就需要先将cup-1中被改变了的整个缓存行更新回主存(即使其它变量没有更改),然后cup-2才能够读取,而cup-2可能需要更改这个缓存行的变量与cpu-1已经更改的缓存行中的变量是不一样的,所以这相当于给几个毫不相关的变量加了一把同步锁;
为了防止伪共享,不同jdk版本实现方式是不一样的:
1. 在jdk1.7之前会 将需要独占缓存行的变量前后添加一组long类型的变量,依靠这些无意义的数组的填充做到一个变量自己独占一个缓存行;
2. 在jdk1.7因为jvm会将这些没有用到的变量优化掉,所以采用继承一个声明了好多long变量的类的方式来实现;
3. 在jdk1.8中通过添加sun.misc.Contended注解来解决这个问题,若要使该注解有效必须在jvm中添加以下参数: -XX:-RestrictContended sun.misc.Contended注解会在变量前面添加128字节的padding将当前变量与其他变量进行隔离;