#coding=utf-8 import re with open('aaa.txt','r',encoding="utf-8") as f: #data = f.read().decode('gbk').encode('utf-8') data = f.read() print(data) #str = re.sub(r'(\ud+)',"",data) #data = re.sub("[A-Za-z0-9!\%[]\,。]", "", data) #data = re.sub('[W_+]', "", data) data = re.sub('[u4E00-u9FA5]',"", data) print(data)
#过滤掉除了中文以外的字符
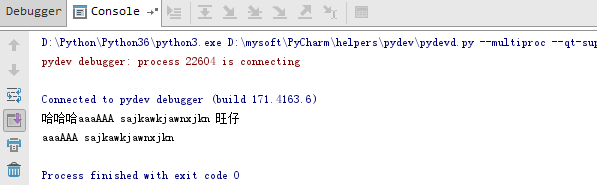
import re """ python 3.5版本 正则匹配中文,固定形式:u4E00-u9FA5 """ text = "aqweded***中国***xsa***日本***韩国" regStr = ".*?([u4E00-u9FA5]+).*?" aa = re.findall(regStr, text) if aa: print(aa)
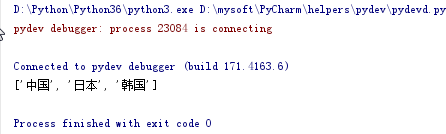
#提取字符串里的中文,返回数组
#coding=utf-8 import re with open('aaa.txt','r',encoding="utf-8") as f: #data = f.read().decode('gbk').encode('utf-8') data = f.read() print(data) data = re.sub("[A-Za-z0-9!\%[]\,。 ]", "", data) #data = re.sub('[u4E00-u9FA5]',"", data) print(data)

# -*- coding: utf-8 -*- import re #过滤掉除了中文以外的字符 str = "hello,world!!%[545]你好234世界。。。" str = re.sub("[A-Za-z0-9!\%[]\,。]", "", str) print(str) #提取字符串里的中文,返回数组 pattern="[u4e00-u9fa5]+" regex = re.compile(pattern) results = regex.findall("adf中文adf发京东方") print(results)