1.准备两个表
表a:
结构:
mysql> desc a; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | name | varchar(40) | NO | PRI | NULL | | | age | int(11) | YES | | NULL | | +-------+-------------+------+-----+---------+-------+
数据
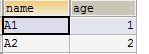
表b:
结构
mysql> desc b; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | nameB | varchar(40) | YES | | NULL | | | ageB | int(11) | YES | | NULL | | +-------+-------------+------+-----+---------+-------+
数据:

2.进行连接查询测试:
(1)交叉连接(笛卡尔积) cross join
mysql> select * from a,b; #第一种 +------+------+-------+------+ | name | age | nameB | ageB | +------+------+-------+------+ | A1 | 1 | B1 | 1 | | A2 | 2 | B1 | 1 | | A1 | 1 | B2 | 22 | | A2 | 2 | B2 | 22 | +------+------+-------+------+ 4 rows in set (0.00 sec) mysql> select * from a cross join b; #第二种 +------+------+-------+------+ | name | age | nameB | ageB | +------+------+-------+------+ | A1 | 1 | B1 | 1 | | A2 | 2 | B1 | 1 | | A1 | 1 | B2 | 22 | | A2 | 2 | B2 | 22 | +------+------+-------+------+ 4 rows in set (0.00 sec) mysql> select a.*,b.* from a cross join b; #第二种的又一个写法 +------+------+-------+------+ | name | age | nameB | ageB | +------+------+-------+------+ | A1 | 1 | B1 | 1 | | A2 | 2 | B1 | 1 | | A1 | 1 | B2 | 22 | | A2 | 2 | B2 | 22 | +------+------+-------+------+ 4 rows in set (0.00 sec)
(2)内连接 join 或 inner join(在笛卡尔积的基础上过滤)
- 显示内连接
(1)不带条件的内连接
mysql> select a.*,b.* from a inner join b on a.age=b.ageb; #第一种 inner join
+------+------+-------+------+ | name | age | nameB | ageB | +------+------+-------+------+ | A1 | 1 | B1 | 1 | +------+------+-------+------+ 1 row in set (0.00 sec)
mysql> select a.*,b.* from a join b on a.age=b.ageb; #第二种 join (默认是inner join) +------+------+-------+------+ | name | age | nameB | ageB | +------+------+-------+------+ | A1 | 1 | B1 | 1 | +------+------+-------+------+ 1 row in set (0.00 sec)
三个表的显示内连接:
SELECT a.*, b.*, c.* FROM exampaper a INNER JOIN bigquestion b INNER JOIN exampaperquestion c ON a.paperId = b.paperId AND b.bigQuertionId = c.bigQuertionId
四个表的显示内连接:
SELECT train.trainingSchemaName, train.majorName, train.createTime, tc.*, course.*, type.* FROM trainschemeinfo train JOIN train_course tc ON train.trainingSchemeID = tc.trainningSchemeID INNER JOIN t_course_base_info course ON tc.courseID = course.courseId INNER JOIN coursetypeinfo type ON tc.typeNum = type.typeNum WHERE tc.trainningSchemeID = '661ecb064b164d1ea133956f89beddb7'
与之等价的隐士内连接:
SELECT train.trainingSchemaName, train.majorName, train.createTime, tc.*, course.*, type.* FROM trainschemeinfo train, train_course tc, t_course_base_info course, coursetypeinfo type WHERE train.trainingSchemeID = tc.trainningSchemeID AND tc.courseID = course.courseId AND tc.typeNum = type.typeNum AND tc.trainningSchemeID = '661ecb064b164d1ea133956f89beddb7'
(2)显示内连接带条件
mysql> select a.*,b.* from a join b on a.age=b.ageb having a.name='A1'; #having从查出的数据中挑选满足条件的元祖 +------+------+-------+------+ | name | age | nameB | ageB | +------+------+-------+------+ | A1 | 1 | B1 | 1 | +------+------+-------+------+ 1 row in set (0.00 sec) mysql> select a.*,b.* from a join b on a.age=b.ageb where a.name='A1'; #where查询满足条件的元素 +------+------+-------+------+ | name | age | nameB | ageB | +------+------+-------+------+ | A1 | 1 | B1 | 1 | +------+------+-------+------+ 1 row in set (0.00 sec)
- 隐士内连接:
mysql> select * from a,b where a.age=b.ageb; +------+------+-------+------+ | name | age | nameB | ageB | +------+------+-------+------+ | A1 | 1 | B1 | 1 | +------+------+-------+------+ 1 row in set (0.00 sec) mysql> select * from a,b where a.age=b.ageb and a.name='A1'; +------+------+-------+------+ | name | age | nameB | ageB | +------+------+-------+------+ | A1 | 1 | B1 | 1 | +------+------+-------+------+ 1 row in set (0.00 sec) mysql> select * from a,b where a.age=b.ageb having a.name='A1'; +------+------+-------+------+ | name | age | nameB | ageB | +------+------+-------+------+ | A1 | 1 | B1 | 1 | +------+------+-------+------+ 1 row in set (0.00 sec)
where是从本地磁盘查询满足条件的元素,having是从查出的数据中挑选满足条件的元素。执行权限 where>sum()..聚合函数>having
(3)左外连接:(拿左边的匹配右边的,没有找到右边的为null)
mysql> select * from a left join b on a.age = b.ageb; #第一种 left join +------+------+-------+------+ | name | age | nameB | ageB | +------+------+-------+------+ | A1 | 1 | B1 | 1 | | A2 | 2 | NULL | NULL | +------+------+-------+------+ 2 rows in set (0.00 sec) mysql> select * from a left outer join b on a.age = b.ageb; #第二种 left outer join +------+------+-------+------+ | name | age | nameB | ageB | +------+------+-------+------+ | A1 | 1 | B1 | 1 | | A2 | 2 | NULL | NULL | +------+------+-------+------+ 2 rows in set (0.00 sec)
(4)右外连接:(拿右边的匹配左边的,没有找到左边的为null)
mysql> select * from a right join b on a.age = b.ageb; #第一种 right join +------+------+-------+------+ | name | age | nameB | ageB | +------+------+-------+------+ | A1 | 1 | B1 | 1 | | NULL | NULL | B2 | 22 | +------+------+-------+------+ 2 rows in set (0.00 sec) mysql> select * from a right outer join b on a.age = b.ageb; #第二种 right outer join +------+------+-------+------+ | name | age | nameB | ageB | +------+------+-------+------+ | A1 | 1 | B1 | 1 | | NULL | NULL | B2 | 22 | +------+------+-------+------+ 2 rows in set (0.00 sec)
3.Union 和 union all 取两个表的并集测试
修改b表,加一条和a表重复的数据
b表数据:
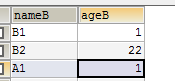
a表数据:

(1) union: 自动去掉重复元素
mysql> select * from a union select * from b; +------+------+ | name | age | +------+------+ | A1 | 1 | | A2 | 2 | | B1 | 1 | | B2 | 22 | +------+------+ 4 rows in set (0.00 sec)
总结:
union:联合的意思,即把两次或多次查询结果合并起来。
要求:两次查询的列数必须一致
推荐:列的类型可以不一样,但推荐查询的每一列,想对应的类型以一样
可以来自多张表的数据:多次sql语句取出的列名可以不一致,此时以第一个sql语句的列名为准。
如果不同的语句中取出的行,有完全相同(这里表示的是每个列的值都相同),那么union会将相同的行合并,最终只保留一行。也可以这样理解,union会去掉重复的行。
如果不想去掉重复的行,可以使用union all。
如果子句中有order by,limit,需用括号()包起来。推荐放到所有子句之后,即对最终合并的结果来排序或筛选,可以对union之后的数据进行排序和分页等操作。
例如:采用union合并的多个表的数据的SQL
需求是:为了显示学院、专业、班级树,但是这些信息不在一个月表,而且班级表中有专业编号,专业表中有学院编号。思路就是:分别从三个表中获取数据,然后采用union进行合并数据。
SELECT classID AS departNum, className AS departName, "class" AS departType, (SELECT majorID FROM t_major_base_info WHERE majorID = class.majorID) AS updepartNum FROM t_class_base_info class UNION SELECT majorID AS departNum, majorName AS departName, "major" AS departType, (SELECT collegeID FROM t_college_base_info WHERE collegeID=major.collegeID) AS updepartNum FROM t_major_base_info major UNION SELECT collegeId AS departNum, collegeName AS departName, "college" AS departType, "000" AS updepartNum FROM t_college_base_info
(2) union all 保留重复元素
UNION ALL 命令和 UNION 命令几乎是等效的,不过 UNION ALL 命令会列出所有的值。
mysql> select * from a union all select * from b; +------+------+ | name | age | +------+------+ | A1 | 1 | | A2 | 2 | | B1 | 1 | | B2 | 22 | | A1 | 1 | +------+------+ 5 rows in set (0.00 sec)
总结:
UNION 用于合并两个或多个 SELECT 语句的结果集,并消去表中任何重复行。
UNION 内部的 SELECT 语句必须拥有相同数量的列,列也必须拥有相似的数据类型。
同时,每条 SELECT 语句中的列的顺序必须相同.
默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
当 ALL 随 UNION 一起使用时(即 UNION ALL),不消除重复行
注意:
1、UNION 结果集中的列名总是等于第一个 SELECT 语句中的列名
2、UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同
补充:今天在项目种用到了从多个表种查询数据把并且分页,实现过程是将所有表的名字传到dao,然后遍历表名字,一起添加条件(前提是需要查询的列名字相同):
public List<Map<String, Object>> getAllData(List<String> tableNames) { List<String> sqls = new ArrayList(); StringBuilder sb = null; for (String tableName : tableNames) { sb = new StringBuilder(); sb.append("select id,name from "); sb.append(tableName); sb.append(" where 1=1"); sb.append(" and name = 'zhangsan'"); sqls.add(sb.toString()); } String sqlFinally = StringUtils.join(sqls, " union "); sqlFinally += "order by name limit 5,5"; System.out.println(sqlFinally); /*Session session = getSessionFactory().openSession(); SQLQuery sqlQuery = session.createSQLQuery(sqlFinally); sqlQuery.setResultTransformer(Transformers.ALIAS_TO_ENTITY_MAP); return sqlQuery.list();*/ return null; }
测试:
public static void main(String[] args) {
GroupDaoImpl g = new GroupDaoImpl();
List tableNames = new ArrayList();
tableNames.add("t1");
tableNames.add("t2");
tableNames.add("t3");
g.getAllData(tableNames);
}
结果:
select id,name from t1 where 1=1 and name = 'zhangsan' union select id,name from t2 where 1=1 and name = 'zhangsan' union select id,name from t3 where 1=1 and name = 'zhangsan' order by name limit 5,5