监督学习 (Supervised Learning)
"right answers" given (监督学习的特点是:给定“正确答案”)
In supervised learning, we are given a data set and already know what our correct output should look like, having the idea that there is a relationship between the input and the output.
在有监督的学习中,我们得到一个数据集,并且已经知道我们的正确输出应该是什么样的,并且认为输入和输出之间存在关系。
Supervised learning problems are categorized into "regression" and "classification" problems. In a regression problem, we are trying to predict results within a continuous output, meaning that we are trying to map input variables to some continuous function. In a classification problem, we are instead trying to predict results in a discrete output. In other words, we are trying to map input variables into discrete categories.
监督学习问题分为“回归”和“分类”问题。 在回归问题中,我们试图在连续输出中预测结果,这意味着我们正在尝试将输入变量映射到某个连续函数。 在分类问题中,我们试图在离散输出中预测结果。 换句话说,我们试图将输入变量映射到离散类别。
举例帮助理解
例子 1:房价预测
给出多组“房子大小”和其对应的“房子价格”让计算机学习,这里的“房子的价格”就是给定的“正确答案”。比如
| 房子大小 | 房子的价格 |
| 489 | 101 |
| 512 | 148 |
| 890 | 249 |
| 1470 | 308 |
| 1803 | ? |
去预测一个给定“房子大小(1803)”的房子的“房子的价格”。(这也是一个回归问题:预测连续的输出值)
例子 2:根据肿瘤大小判断乳腺癌是良性还是恶性
给出多组“肿瘤大小”和“是否是恶性”让计算机学习,这里的“是否是恶性”就是给定的“正确答案”。比如
| 肿瘤大小 | 是否是恶性的 |
| 2 | N |
| 3 | N |
| 4 | N |
| 4.5 | ? |
| 5 | Y |
| 6 | Y |
| 7 | N |
| 8 | Y |
给出新的“肿瘤大小(4.5)”则“是否是恶性(Y/N ?)”。(这是一个分类问题:预测离散的输出值)
如果给出两个特征(feature)"肿瘤大小"和“患者年龄”,以及“正确答案”——“是否的恶性”。比如
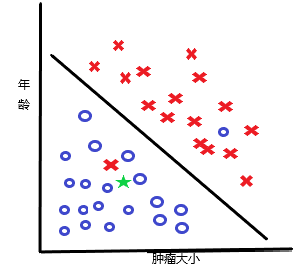
图 1
图 1 中蓝色圆圈代表“肿瘤为恶性”(N),红色 x 代表“肿瘤为恶性”(Y);
当给出一个新的患者的特征“肿瘤大小”和“年龄”(图中绿色的五角星)判断该患者的“肿瘤为恶性”(Y/N ?);
机器学习算法可能给出图中的黑线区分患者的肿瘤是否为恶性,它认为黑线右上方区域属于“肿瘤为恶性”(Y)区域,黑线左下方区域属于“肿瘤为恶性”(N)。因此,算法对绿色五角星的判断为“肿瘤为恶性”(N)。
患者还可以有更多的特征,比如:肿瘤厚度、细胞大小均匀性、细胞形状均匀性等。
当问题有无限个特征怎么处理呢?(支持向量机等)