论文下载:http://arxiv.org/abs/1506.02640
代码下载:https://github.com/pjreddie/darknet
1、创新点
端到端训练及推断 + 改革区域建议框式目标检测框架 + 实时目标检测
改革了区域建议框式检测框架: RCNN系列均需要生成建议框,在建议框上进行分类与回归,但建议框之间有重叠,这会带来很多重复工作。YOLO将全图划分为SXS的格子,每个格子负责中心在该格子的目标检测,采用一次性预测所有格子所含目标的bbox、定位置信度以及所有类别概率向量来将问题一次性解决(one-shot)。
2、核心思想
从R-CNN到Fast R-CNN一直采用的思路是proposal+分类 (proposal 提供位置信息, 分类提供类别信息)精度已经很高,但是速度还不行。 YOLO提供了另一种更为直接的思路: 直接在输出层回归bounding box的位置和bounding box所属的类别(整张图作为网络的输入,把 Object Detection 的问题转化成一个 Regression 问题)。
3、特点
优点:
(1)速度快,能够达到实时的要求。在 Titan X 的 GPU 上 能够达到 45 帧每秒。
(2)使用全图作为 Context 信息,背景错误(把背景错认为物体)比较少。
(3)泛化能力强。
缺点:
(1)对小物体及邻近特征检测效果差:当一个小格中出现多于两个小物体或者一个小格中出现多个不同物体时效果欠佳。原因:B表示每个小格预测边界框数,而YOLO默认同格子里所有边界框为同种类物体。
(2)图片进入网络前会先进行resize为448 x 448,降低检测速度(it takes about 10ms in 25ms),如果直接训练对应尺寸会有加速空间。
(3)基础网络计算量较大,yolov2使用darknet-19进行加速。
(4)预测的 Box 对于尺度的变化比较敏感,在尺度上的泛化能力比较差。
(5)由于损失函数的问题,定位误差是影响检测效果的主要原因,尤其是大小物体的处理上,还有待加强。
4、网络结构
该论文提出的网络结构,包括 24 个卷积层,最后接 2 个全连接层。文章设计的网络借鉴 GoogleNet 的思想,在每个 1∗1 的 归约层(Reduction layer) 之后再接一个 3∗3 的卷积层的结构替代 Inception结构。文章中还提到了 fast 版本的 Yolo,只有 9 个卷积层,其他的结构基本一致。网络的主体结构如下:
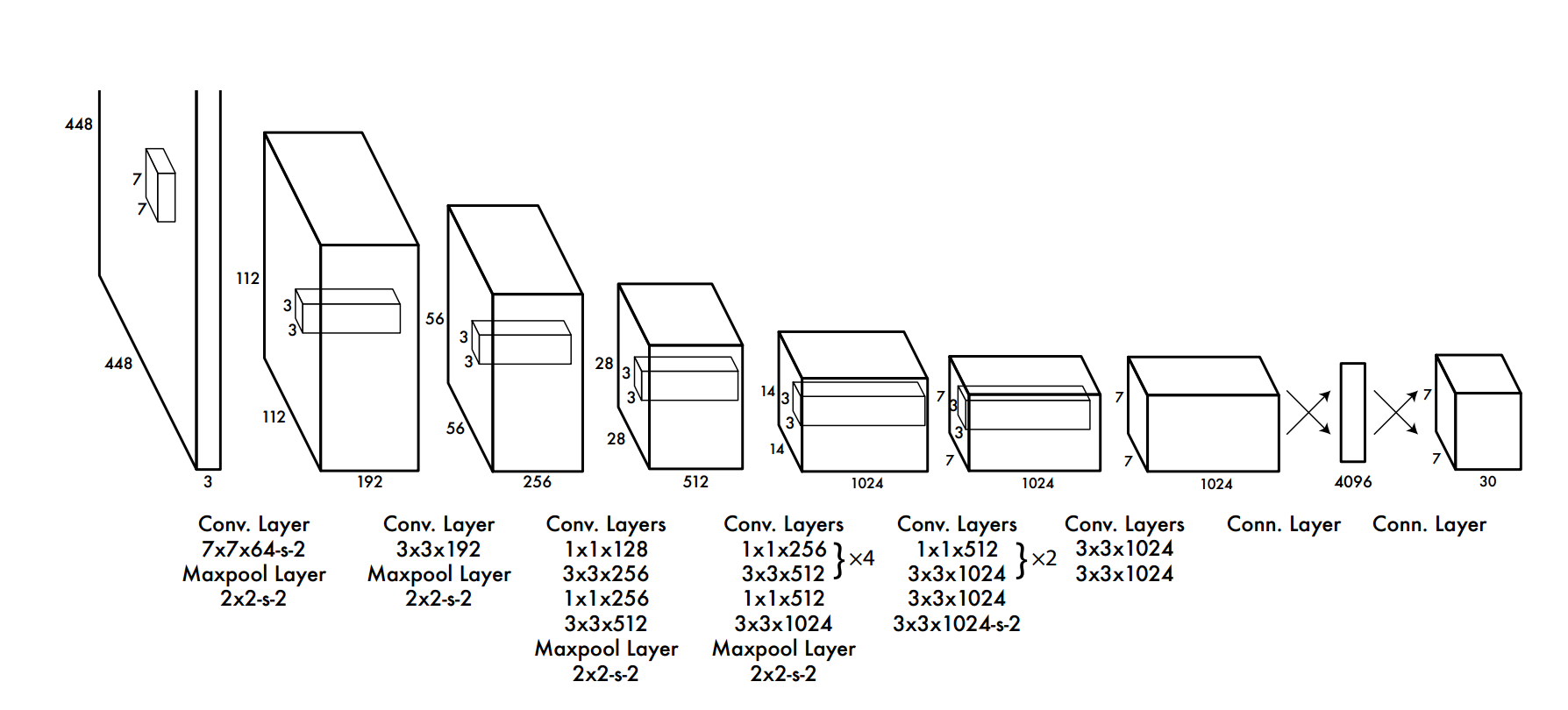
5、实现方法
(1)将一幅图像分成SxS个网格(grid cell),如果某个object的中心 落在这个网格中,则这个网格就负责预测这个object。
(2)每个网格要预测B个bounding box,每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence值。
这个confidence代表了所预测的box中含有object的置信度和这个box预测的有多准两重信息,其值是这样计算的:
其中如果有object落在一个grid cell里,第一项取1,否则取0。 第二项是预测的bounding box和实际的groundtruth之间的IoU值。
(3)每个bounding box要预测(x, y, w, h)和confidence共5个值,每个网格还要预测一个类别信息,记为C类。则SxS个网格,每个网格要预测B个bounding box还要预测C个categories。输出就是S x S x (5*B+C)的一个tensor。
注意:class信息是针对每个网格的,confidence信息是针对每个bounding box的。
(4)举例说明: 在PASCAL VOC中,图像输入为448x448,取S=7,B=2,一共有20个类别(C=20)。则输出就是7x7x30的一个tensor。
(5)在test的时候,每个网格预测的class信息和bounding box预测的confidence信息相乘,就得到每个bounding box的class-specific confidence score:
等式左边第一项就是每个网格预测的类别信息,第二三项就是每个bounding box预测的confidence。这个乘积即encode了预测的box属于某一类的概率,也有该box准确度的信息。

(5)得到每个box的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果。
6、实现细节
(1)每个grid有30维,这30维中,8维是回归box的坐标,2维是box的confidence,还有20维是类别。
其中坐标的x,y用对应网格的offset归一化到0-1之间,w,h用图像的width和height归一化到0-1之间。
(2)在实现中,最主要的就是怎么设计损失函数,让这个三个方面得到很好的平衡。作者简单粗暴的全部采用了sum-squared error loss来做这件事。
这种做法存在以下几个问题:
第一,8维的localization error和20维的classification error同等重要显然是不合理的;
第二,如果一个网格中没有object(一幅图中这种网格很多),那么就会将这些网格中的box的confidence push到0,相比于较少的有object的网格,这种做法是overpowering的,这会导致网络不稳定甚至发散。
解决办法:
- 更重视8维的坐标预测,给这些损失前面赋予更大的loss weight, 记为
在pascal VOC训练中取5。
- 对没有object的box的confidence loss,赋予小的loss weight,记为
在pascal VOC训练中取0.5。
- 有object的box的confidence loss和类别的loss的loss weight正常取1。
(3)对不同大小的box预测中,相比于大box预测偏一点,小box预测偏一点肯定更不能被忍受的。而sum-square error loss中对同样的偏移loss是一样。
为了缓和这个问题,作者用了一个比较取巧的办法,就是将box的width和height取平方根代替原本的height和width。小box的横轴值较小,发生偏移时,反应到y轴上相比大box要大。
(4)一个网格预测多个box,希望的是每个box predictor专门负责预测某个object。具体做法就是看当前预测的box与ground truth box中哪个IoU大,就负责哪个。这种做法称作box predictor的specialization。
(5)最后整个的损失函数如下所示:

这个损失函数中:
- 只有当某个网格中有object的时候才对classification error进行惩罚。
- 只有当某个box predictor对某个ground truth box负责的时候,才会对box的coordinate error进行惩罚,而对哪个ground truth box负责就看其预测值和ground truth box的IoU是不是在那个cell的所有box中最大。
(6)其他细节,例如使用激活函数使用leak RELU,模型用ImageNet预训练等等
7、训练策略
(1)首先利用 ImageNet 的数据集 Pretrain 卷积层。使用上述网络中的前 20 个卷积层,外加一个全连接层,作为 Pretrain 的网络,训练大约一周的时间,使得在 ImageNet 2012 的验证数据集 Top-5 的准确度达到 88%,这个结果跟 GoogleNet 的效果相当。
(2)将 Pretrain 的结果应用到 Detection 中,将剩下的 4 个卷积层及 2 个全连接层加入到 Pretrain 的网络中。同时为了获取更精细化的结果,将输入图像的分辨率由 224*224 提升到 448*448。
(3)将所有的预测结果都归一化到 0~1, 使用 Leaky RELU 作为激活函数。
(4)对比 localization error 和 classification error,加大 localization 的权重。
(5)在 Pascal VOC 2007 和 2012 上训练 135 个 epochs, Batchsize 设置为 64, Momentum 为 0.9, Decay 为 0.0005.
(6)在第一个 epoch 中 学习率是逐渐从 10−3 增大到 10−2,然后保持学习率为 10−2,一直训练到 75个 epochs,然后学习率为 10−3 训练 30 个 epochs,最后 学习率为 10−4 训练 30 个 epochs。
(7)为了防止过拟合,在第一个全连接层后面接了一个 ratio=0.5 的 Dropout 层。并且对原始图像做了一些随机采样和缩放,甚至对调节图像的在 HSV 空间的饱和度。
8、实际使用
转载一个tensorflow版yolo v1的图片检测项目:https://github.com/hizhangp/yolo_tensorflow
下载pascal VOC 2007 数据集和 small_yolo的ckpt文件需要翻墙,这里给出百度网盘的下载链接:
pascal_VOC:https://pan.baidu.com/s/1miKLVHA#list/path=%2F
YOLO_small_ckpt:https://pan.baidu.com/s/1i57uPLF
以下列出几个主要模块:
常量配置模块config_hzp.py(我将这个模块移动到项目根目录下了):
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2017/12/20 16:12
# @Author : Andes
# @Site :
import os
#
# path and dataset parameter
#
PROJECT_ROOT = '/opt/alpen/qqw/remote/yolo_tf' # 存放测试用的YOLO_small.ckpt的根目录
IMG_ROOT = '/opt/alpen/qqw/remote/yolo_tf/test_img' # 单张测试图片的路径
IMGS_ROOT = '/opt/alpen/qqw/remote/yolo_tf/test_imgs' # 多张测试图片的路径
RESULT_SHOW_ROOT = '/opt/alpen/qqw/remote/yolo_tf/result_show' # 画框结果图片的存储路径
DATA_PATH = 'data' # 相关训练数据的存储路径
PASCAL_PATH = os.path.join(DATA_PATH, 'pascal_voc')
CACHE_PATH = os.path.join(PASCAL_PATH, 'cache')
OUTPUT_DIR = os.path.join(PASCAL_PATH, 'output')
WEIGHTS_DIR = os.path.join(PASCAL_PATH, 'weight')
# WEIGHTS_FILE = os.path.join(WEIGHTS_DIR, 'YOLO_small.ckpt')
# WEIGHTS_FILE = os.path.join(PROJECT_ROOT, 'weights_public', 'YOLO_small.ckpt')
CLASSES = ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus',
'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant', 'sheep', 'sofa',
'train', 'tvmonitor']
FLIPPED = True
#
# model parameter
#
IMAGE_SIZE = 448
CELL_SIZE = 7
BOXES_PER_CELL = 2
ALPHA = 0.1
DISP_CONSOLE = False
OBJECT_SCALE = 1.0
NOOBJECT_SCALE = 1.0
CLASS_SCALE = 2.0
COORD_SCALE = 5.0
#
# solver parameter
#
GPU = ''
LEARNING_RATE = 0.0001
DECAY_STEPS = 30000
DECAY_RATE = 0.1
STAIRCASE = True
BATCH_SIZE = 45
MAX_ITER = 15000
SUMMARY_ITER = 10
SAVE_ITER = 1000
#
# test parameter
#
THRESHOLD = 0.2
IOU_THRESHOLD = 0.5
yolo模型模块yolo_net.py:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2017/12/20 16:12
# @Author : Andes
# @Site :
import numpy as np
import tensorflow as tf
import sys
sys.path.append("../")
import config_hzp as cfg
slim = tf.contrib.slim
# 建立YOLONet
class YOLONet(object):
def __init__(self, is_training=True):
# 网络初始化
# self.weights_file = cfg.WEIGHTS_FILE # 权重文件
self.classes = cfg.CLASSES # 类别
self.num_class = len(self.classes) # 类别数量,值为20
self.image_size = cfg.IMAGE_SIZE # 图像尺寸,值为448
self.cell_size = cfg.CELL_SIZE # cell尺寸,值为7
self.boxes_per_cell = cfg.BOXES_PER_CELL # 每个grid cell负责的boxes,默认为2
self.output_size = (self.cell_size * self.cell_size) *
(self.num_class + self.boxes_per_cell * 5) # 输出尺寸
self.scale = 1.0 * self.image_size / self.cell_size
self.boundary1 = self.cell_size * self.cell_size * self.num_class # 7×7×20
self.boundary2 = self.boundary1 + self.cell_size *
self.cell_size * self.boxes_per_cell # 7×7×20+7×7×2
self.object_scale = cfg.OBJECT_SCALE # 值为1
self.noobject_scale = cfg.NOOBJECT_SCALE # 值为1
self.class_scale = cfg.CLASS_SCALE # 值为2.0
self.coord_scale = cfg.COORD_SCALE # 值为5.0
self.learning_rate = cfg.LEARNING_RATE # 学习速率LEARNING_RATE = 0.0001
self.batch_size = cfg.BATCH_SIZE # BATCH_SIZE = batch_size
self.alpha = cfg.ALPHA # ALPHA = 0.1
# self.disp_console = cfg.DISP_CONSOLE # DISP_CONSOLE = False
# self.phase = phase # train or test
# self.collection = [] # 用于储存网络参数
self.offset = np.transpose(np.reshape(np.array(
[np.arange(self.cell_size)] * self.cell_size * self.boxes_per_cell),
(self.boxes_per_cell, self.cell_size, self.cell_size)), (1, 2, 0))
self.images = tf.placeholder(tf.float32, [None, self.image_size, self.image_size, 3], name='images')
self.logits = self.build_network(self.images, num_outputs=self.output_size, alpha=self.alpha, is_training=is_training)
if is_training:
self.labels = tf.placeholder(tf.float32, [None, self.cell_size, self.cell_size, 5 + self.num_class])
self.loss_layer(self.logits, self.labels)
self.total_loss = tf.losses.get_total_loss()
tf.summary.scalar('total_loss', self.total_loss)
def build_network(self,
images,
num_outputs,
alpha,
keep_prob=0.5,
is_training=True,
scope='yolo'):
with tf.variable_scope(scope):
with slim.arg_scope([slim.conv2d, slim.fully_connected],
activation_fn=leaky_relu(alpha),
weights_initializer=tf.truncated_normal_initializer(0.0, 0.01),
weights_regularizer=slim.l2_regularizer(0.0005)):
net = tf.pad(images, np.array([[0, 0], [3, 3], [3, 3], [0, 0]]), name='pad_1')
net = slim.conv2d(net, 64, 7, 2, padding='VALID', scope='conv_2')
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_3')
net = slim.conv2d(net, 192, 3, scope='conv_4')
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_5')
net = slim.conv2d(net, 128, 1, scope='conv_6')
net = slim.conv2d(net, 256, 3, scope='conv_7')
net = slim.conv2d(net, 256, 1, scope='conv_8')
net = slim.conv2d(net, 512, 3, scope='conv_9')
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_10')
net = slim.conv2d(net, 256, 1, scope='conv_11')
net = slim.conv2d(net, 512, 3, scope='conv_12')
net = slim.conv2d(net, 256, 1, scope='conv_13')
net = slim.conv2d(net, 512, 3, scope='conv_14')
net = slim.conv2d(net, 256, 1, scope='conv_15')
net = slim.conv2d(net, 512, 3, scope='conv_16')
net = slim.conv2d(net, 256, 1, scope='conv_17')
net = slim.conv2d(net, 512, 3, scope='conv_18')
net = slim.conv2d(net, 512, 1, scope='conv_19')
net = slim.conv2d(net, 1024, 3, scope='conv_20')
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_21')
net = slim.conv2d(net, 512, 1, scope='conv_22')
net = slim.conv2d(net, 1024, 3, scope='conv_23')
net = slim.conv2d(net, 512, 1, scope='conv_24')
net = slim.conv2d(net, 1024, 3, scope='conv_25')
net = slim.conv2d(net, 1024, 3, scope='conv_26')
net = tf.pad(net, np.array([[0, 0], [1, 1], [1, 1], [0, 0]]), name='pad_27')
net = slim.conv2d(net, 1024, 3, 2, padding='VALID', scope='conv_28')
net = slim.conv2d(net, 1024, 3, scope='conv_29')
net = slim.conv2d(net, 1024, 3, scope='conv_30')
net = tf.transpose(net, [0, 3, 1, 2], name='trans_31')
net = slim.flatten(net, scope='flat_32')
net = slim.fully_connected(net, 512, scope='fc_33')
net = slim.fully_connected(net, 4096, scope='fc_34')
net = slim.dropout(net, keep_prob=keep_prob,
is_training=is_training, scope='dropout_35')
net = slim.fully_connected(net, num_outputs,
activation_fn=None, scope='fc_36')
return net
def calc_iou(self, boxes1, boxes2, scope='iou'):
"""calculate ious
Args:
boxes1: 4-D tensor [CELL_SIZE, CELL_SIZE, BOXES_PER_CELL, 4] ====> (x_center, y_center, w, h)
boxes2: 1-D tensor [CELL_SIZE, CELL_SIZE, BOXES_PER_CELL, 4] ===> (x_center, y_center, w, h)
Return:
iou: 3-D tensor [CELL_SIZE, CELL_SIZE, BOXES_PER_CELL]
"""
with tf.variable_scope(scope):
boxes1 = tf.stack([boxes1[:, :, :, :, 0] - boxes1[:, :, :, :, 2] / 2.0, # 矩阵拼接
boxes1[:, :, :, :, 1] - boxes1[:, :, :, :, 3] / 2.0,
boxes1[:, :, :, :, 0] + boxes1[:, :, :, :, 2] / 2.0,
boxes1[:, :, :, :, 1] + boxes1[:, :, :, :, 3] / 2.0])
boxes1 = tf.transpose(boxes1, [1, 2, 3, 4, 0]) # 根据[1, 2, 3, 4, 0]进行矩阵转置
boxes2 = tf.stack([boxes2[:, :, :, :, 0] - boxes2[:, :, :, :, 2] / 2.0,
boxes2[:, :, :, :, 1] - boxes2[:, :, :, :, 3] / 2.0,
boxes2[:, :, :, :, 0] + boxes2[:, :, :, :, 2] / 2.0,
boxes2[:, :, :, :, 1] + boxes2[:, :, :, :, 3] / 2.0])
boxes2 = tf.transpose(boxes2, [1, 2, 3, 4, 0])
# calculate the left up point & right down point
lu = tf.maximum(boxes1[:, :, :, :, :2], boxes2[:, :, :, :, :2])
rd = tf.minimum(boxes1[:, :, :, :, 2:], boxes2[:, :, :, :, 2:])
# intersection
intersection = tf.maximum(0.0, rd - lu)
inter_square = intersection[:, :, :, :, 0] * intersection[:, :, :, :, 1]
# calculate the boxs1 square and boxs2 square
square1 = (boxes1[:, :, :, :, 2] - boxes1[:, :, :, :, 0]) *
(boxes1[:, :, :, :, 3] - boxes1[:, :, :, :, 1])
square2 = (boxes2[:, :, :, :, 2] - boxes2[:, :, :, :, 0]) *
(boxes2[:, :, :, :, 3] - boxes2[:, :, :, :, 1])
union_square = tf.maximum(square1 + square2 - inter_square, 1e-10)
return tf.clip_by_value(inter_square / union_square, 0.0, 1.0)
# loss函数
def loss_layer(self, predicts, labels, scope='loss_layer'):
with tf.variable_scope(scope):
# 将网络输出分离为类别和定位以及box大小,输出维度为7*7*20+7*7*2+7*7*2*4=1470
# 类别,shape为(batch_size, 7, 7, 20),将预测结果的前 20维(表示类别)转换为相应的矩阵形式 (类别向量)
predict_classes = tf.reshape(predicts[:, :self.boundary1], [self.batch_size, self.cell_size, self.cell_size, self.num_class])
# 定位,shape为(batch_size, 7, 7, 2),将预测结果 的 21 ~ 34 转换为相应的矩阵形式 (尺度向量?)
predict_scales = tf.reshape(predicts[:, self.boundary1:self.boundary2], [self.batch_size, self.cell_size, self.cell_size, self.boxes_per_cell])
# box大小,长宽等 shape为(batch_size, 7, 7, 2, 4),将预测结果剩余的维度转变为相应的矩阵形式(boxes 所在的位置向量)
predict_boxes = tf.reshape(predicts[:, self.boundary2:], [self.batch_size, self.cell_size, self.cell_size, self.boxes_per_cell, 4])
# label的类别结果,shape为(batch_size, 7, 7, 1),将真实的 labels 转换为相应的矩阵形式
response = tf.reshape(labels[:, :, :, 0], [self.batch_size, self.cell_size, self.cell_size, 1])
# label的定位结果,shape为(batch_size, 7, 7, 1, 4)
boxes = tf.reshape(labels[:, :, :, 1:5], [self.batch_size, self.cell_size, self.cell_size, 1, 4])
# label的大小结果,shapewei (batch_size, 7, 7, 2, 4)
boxes = tf.tile(boxes, [1, 1, 1, self.boxes_per_cell, 1]) / self.image_size
# shape 为(batch_size, 7, 7, 20)
classes = labels[:, :, :, 5:]
# offset shape为(7, 7, 2)
offset = tf.constant(self.offset, dtype=tf.float32)
# shape为 (1,7, 7, 2)
offset = tf.reshape(offset, [1, self.cell_size, self.cell_size, self.boxes_per_cell])
# shape为(batch_size, 7, 7, 2)
offset = tf.tile(offset, [self.batch_size, 1, 1, 1])
# shape为(4, batch_size, 7, 7, 2)
predict_boxes_tran = tf.stack([(predict_boxes[:, :, :, :, 0] + offset) / self.cell_size,
(predict_boxes[:, :, :, :, 1] + tf.transpose(offset, (0, 2, 1, 3))) / self.cell_size,
tf.square(predict_boxes[:, :, :, :, 2]),
tf.square(predict_boxes[:, :, :, :, 3])])
# shape为(batch_size, 7, 7, 2, 4)
predict_boxes_tran = tf.transpose(predict_boxes_tran, [1, 2, 3, 4, 0])
# shape为(batch_size, 7, 7, 2)
iou_predict_truth = self.calc_iou(predict_boxes_tran, boxes)
# calculate I tensor [BATCH_SIZE, CELL_SIZE, CELL_SIZE, BOXES_PER_CELL]
# shape为 (batch_size, 7, 7, 1)
object_mask = tf.reduce_max(iou_predict_truth, 3, keep_dims=True)
# shape为(batch_size, 7, 7, 2)
object_mask = tf.cast((iou_predict_truth >= object_mask), tf.float32) * response
# mask = tf.tile(response, [1, 1, 1, self.boxes_per_cell])
# calculate no_I tensor [CELL_SIZE, CELL_SIZE, BOXES_PER_CELL]
# shape为(batch_size, 7, 7, 2)
noobject_mask = tf.ones_like(object_mask, dtype=tf.float32) - object_mask
# shape为(4, batch_size, 7, 7, 2)
boxes_tran = tf.stack([boxes[:, :, :, :, 0] * self.cell_size - offset,
boxes[:, :, :, :, 1] * self.cell_size - tf.transpose(offset, (0, 2, 1, 3)),
tf.sqrt(boxes[:, :, :, :, 2]),
tf.sqrt(boxes[:, :, :, :, 3])])
# shape为(batch_size, 7, 7, 2, 4)
boxes_tran = tf.transpose(boxes_tran, [1, 2, 3, 4, 0])
# class_loss
class_delta = response * (predict_classes - classes)
class_loss = tf.reduce_mean(tf.reduce_sum(tf.square(class_delta), axis=[1, 2, 3]), name='class_loss') * self.class_scale
# object_loss
object_delta = object_mask * (predict_scales - iou_predict_truth)
object_loss = tf.reduce_mean(tf.reduce_sum(tf.square(object_delta), axis=[1, 2, 3]), name='object_loss') * self.object_scale
# noobject_loss
noobject_delta = noobject_mask * predict_scales
noobject_loss = tf.reduce_mean(tf.reduce_sum(tf.square(noobject_delta), axis=[1, 2, 3]), name='noobject_loss') * self.noobject_scale
# coord_loss
# shape 为 (batch_size, 7, 7, 2, 1)
coord_mask = tf.expand_dims(object_mask, 4)
# shape为(batch_size, 7, 7, 2, 4)
boxes_delta = coord_mask * (predict_boxes - boxes_tran)
coord_loss = tf.reduce_mean(tf.reduce_sum(tf.square(boxes_delta), axis=[1, 2, 3, 4]), name='coord_loss') * self.coord_scale
tf.losses.add_loss(class_loss)
tf.losses.add_loss(object_loss)
tf.losses.add_loss(noobject_loss)
tf.losses.add_loss(coord_loss)
tf.summary.scalar('class_loss', class_loss)
tf.summary.scalar('object_loss', object_loss)
tf.summary.scalar('noobject_loss', noobject_loss)
tf.summary.scalar('coord_loss', coord_loss)
tf.summary.histogram('boxes_delta_x', boxes_delta[:, :, :, :, 0])
tf.summary.histogram('boxes_delta_y', boxes_delta[:, :, :, :, 1])
tf.summary.histogram('boxes_delta_w', boxes_delta[:, :, :, :, 2])
tf.summary.histogram('boxes_delta_h', boxes_delta[:, :, :, :, 3])
tf.summary.histogram('iou', iou_predict_truth)
def leaky_relu(alpha):
def op(inputs):
return tf.maximum(alpha * inputs, inputs, name='leaky_relu')
return op
主测试模块test.py:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2017/12/20 16:12
# @Author : Andes
# @Site :
import argparse
import cv2
import numpy as np
import os
import tensorflow as tf
import config_hzp as cfg
from utils.timer import Timer
from utils.get_path_list import get_imglist_cnn as gic # 获取图片路径列表的模块,自己随便写写都能写出来
from yolo.yolo_net import YOLONet
class Detector(object):
def __init__(self, net, weight_file):
self.net = net
self.weights_file = weight_file
self.classes = cfg.CLASSES
self.num_class = len(self.classes)
self.image_size = cfg.IMAGE_SIZE
self.cell_size = cfg.CELL_SIZE
self.boxes_per_cell = cfg.BOXES_PER_CELL
self.threshold = cfg.THRESHOLD
self.iou_threshold = cfg.IOU_THRESHOLD
self.boundary1 = self.cell_size * self.cell_size * self.num_class
self.boundary2 = self.boundary1 + self.cell_size * self.cell_size * self.boxes_per_cell
self.sess = tf.Session()
self.sess.run(tf.global_variables_initializer())
print 'Restoring weights_public from: ' + self.weights_file
self.saver = tf.train.Saver()
self.saver.restore(self.sess, self.weights_file)
def draw_result(self, img, result):
for i in range(len(result)):
x = int(result[i][1])
y = int(result[i][2])
w = int(result[i][3] / 2)
h = int(result[i][4] / 2)
cv2.rectangle(img, (x - w, y - h), (x + w, y + h), (0, 255, 0), 2)
cv2.rectangle(img, (x - w, y - h - 20),
(x + w, y - h), (125, 125, 125), -1)
cv2.putText(img, result[i][0] + ' : %.2f' % result[i][5], (x - w + 5, y - h - 7), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 1, cv2.CV_AA)
return img
def detect(self, img):
img_h, img_w, _ = img.shape
inputs = cv2.resize(img, (self.image_size, self.image_size))
inputs = cv2.cvtColor(inputs, cv2.COLOR_BGR2RGB).astype(np.float32)
inputs = (inputs / 255.0) * 2.0 - 1.0
inputs = np.reshape(inputs, (1, self.image_size, self.image_size, 3))
result = self.detect_from_cvmat(inputs)[0]
for i in range(len(result)):
result[i][1] *= (1.0 * img_w / self.image_size)
result[i][2] *= (1.0 * img_h / self.image_size)
result[i][3] *= (1.0 * img_w / self.image_size)
result[i][4] *= (1.0 * img_h / self.image_size)
return result
def detect_from_cvmat(self, inputs):
net_output = self.sess.run(self.net.logits,
feed_dict={self.net.images: inputs})
results = []
for i in range(net_output.shape[0]):
results.append(self.interpret_output(net_output[i]))
return results
def interpret_output(self, output):
probs = np.zeros((self.cell_size, self.cell_size,
self.boxes_per_cell, self.num_class))
class_probs = np.reshape(output[0:self.boundary1], (self.cell_size, self.cell_size, self.num_class))
scales = np.reshape(output[self.boundary1:self.boundary2], (self.cell_size, self.cell_size, self.boxes_per_cell))
boxes = np.reshape(output[self.boundary2:], (self.cell_size, self.cell_size, self.boxes_per_cell, 4))
offset = np.transpose(np.reshape(np.array([np.arange(self.cell_size)] * self.cell_size * self.boxes_per_cell),
[self.boxes_per_cell, self.cell_size, self.cell_size]), (1, 2, 0))
boxes[:, :, :, 0] += offset
boxes[:, :, :, 1] += np.transpose(offset, (1, 0, 2))
boxes[:, :, :, :2] = 1.0 * boxes[:, :, :, 0:2] / self.cell_size
boxes[:, :, :, 2:] = np.square(boxes[:, :, :, 2:])
boxes *= self.image_size
for i in range(self.boxes_per_cell):
for j in range(self.num_class):
probs[:, :, i, j] = np.multiply(
class_probs[:, :, j], scales[:, :, i])
filter_mat_probs = np.array(probs >= self.threshold, dtype='bool')
filter_mat_boxes = np.nonzero(filter_mat_probs)
boxes_filtered = boxes[filter_mat_boxes[0],
filter_mat_boxes[1], filter_mat_boxes[2]]
probs_filtered = probs[filter_mat_probs]
classes_num_filtered = np.argmax(filter_mat_probs, axis=3)[filter_mat_boxes[
0], filter_mat_boxes[1], filter_mat_boxes[2]]
argsort = np.array(np.argsort(probs_filtered))[::-1]
boxes_filtered = boxes_filtered[argsort]
probs_filtered = probs_filtered[argsort]
classes_num_filtered = classes_num_filtered[argsort]
for i in range(len(boxes_filtered)):
if probs_filtered[i] == 0:
continue
for j in range(i + 1, len(boxes_filtered)):
if self.iou(boxes_filtered[i], boxes_filtered[j]) > self.iou_threshold:
probs_filtered[j] = 0.0
filter_iou = np.array(probs_filtered > 0.0, dtype='bool')
boxes_filtered = boxes_filtered[filter_iou]
probs_filtered = probs_filtered[filter_iou]
classes_num_filtered = classes_num_filtered[filter_iou]
result = []
for i in range(len(boxes_filtered)):
result.append([self.classes[classes_num_filtered[i]], boxes_filtered[i][0], boxes_filtered[
i][1], boxes_filtered[i][2], boxes_filtered[i][3], probs_filtered[i]])
return result
def iou(self, box1, box2):
tb = min(box1[0] + 0.5 * box1[2], box2[0] + 0.5 * box2[2]) -
max(box1[0] - 0.5 * box1[2], box2[0] - 0.5 * box2[2])
lr = min(box1[1] + 0.5 * box1[3], box2[1] + 0.5 * box2[3]) -
max(box1[1] - 0.5 * box1[3], box2[1] - 0.5 * box2[3])
if tb < 0 or lr < 0:
intersection = 0
else:
intersection = tb * lr
return intersection / (box1[2] * box1[3] + box2[2] * box2[3] - intersection)
def camera_detector(self, cap, wait=10):
detect_timer = Timer()
ret, _ = cap.read()
while ret:
ret, frame = cap.read()
detect_timer.tic()
result = self.detect(frame)
detect_timer.toc()
print('Average detecting time: {:.3f}s'.format(detect_timer.average_time))
self.draw_result(frame, result)
cv2.imshow('Camera', frame)
cv2.waitKey(wait)
ret, frame = cap.read()
def image_detector(self, imname, wait=0):
detect_timer = Timer()
image = cv2.imread(imname)
img_name = os.path.basename(imname)
img_name = img_name.replace('.jpg', '_det_hzp.jpg')
detect_timer.tic()
result = self.detect(image)
detect_timer.toc()
print('Average detecting time: {:.3f}s'.format(detect_timer.average_time))
image = self.draw_result(image, result)
cv2.imwrite(os.path.join(cfg.RESULT_SHOW_ROOT, img_name), image)
# cv2.imshow('Image', image)
# cv2.waitKey(wait)
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', default="YOLO_small.ckpt", type=str)
parser.add_argument('--weight_dir', default='/opt/alpen/qqw/remote/yolo_tf/weights_public', type=str)
# parser.add_argument('--data_dir', default="data", type=str)
parser.add_argument('--gpu', default='', type=str) # 选择要使用的GPU编号,默认GPU 0
args = parser.parse_args()
os.environ['CUDA_VISIBLE_DEVICES'] = args.gpu
yolo = YOLONet(False)
weight_file = os.path.join(args.weight_dir, args.weights)
detector = Detector(yolo, weight_file)
# detect from camera
# cap = cv2.VideoCapture(-1)
# detector.camera_detector(cap)
# detect from image file
img_list = gic(cfg.IMGS_ROOT)
for img_path in img_list:
detector.image_detector(img_path)
if __name__ == '__main__':
main()
另附上获取图片列表的代码:
def get_imglist_cnn(root_path):
img_list = []
for (r, d, f) in os.walk(root_path):
for line in f:
if line.endswith('png') or line.endswith('jpg') or line.endswith('jpeg')
or line.endswith('PNG') or line.endswith('JPG') or line.endswith('JPEG'):
img_list.append(os.path.join(r, line))
return img_list