MemNN 记忆网络
一般的神经网络是训练好参数后,直接用参数与样本进行计算得出结果,而不会与内存进行交互的,就像一个参变量很多的函数。对于要处理一些很复杂的自然语言,或者要进行人机交互的模型,仅仅靠模型内部参数与参数之间的联结计算是很难达到目的。因此,在处理自然语言等内部概念十分密集的样本,并且可能有后续交互时,允许模型处理时进行内存的读写,就可以把样本有用的“抽象”存在分配给它的内存中,让神经网络能够“理解”和“思考”这些样本。从而将神经网络从一个死的输入输出“函数”,变成一个可与内存交互的东西,就好像一个操作系统一样。
内存给模型提供了一个短期记忆功能,模型可以“记住”你刚刚传给它的信息。比如对于可以阅读理解和交互的模型来说,当它读完一篇文章,它所理解的信息还包含在内存中(因为不能包含在模型参数中),你问它关于这篇文章的问题时,它就能读取内存中存储的文章抽象作答。这就是MemNN,训练以及测试流程图如下:
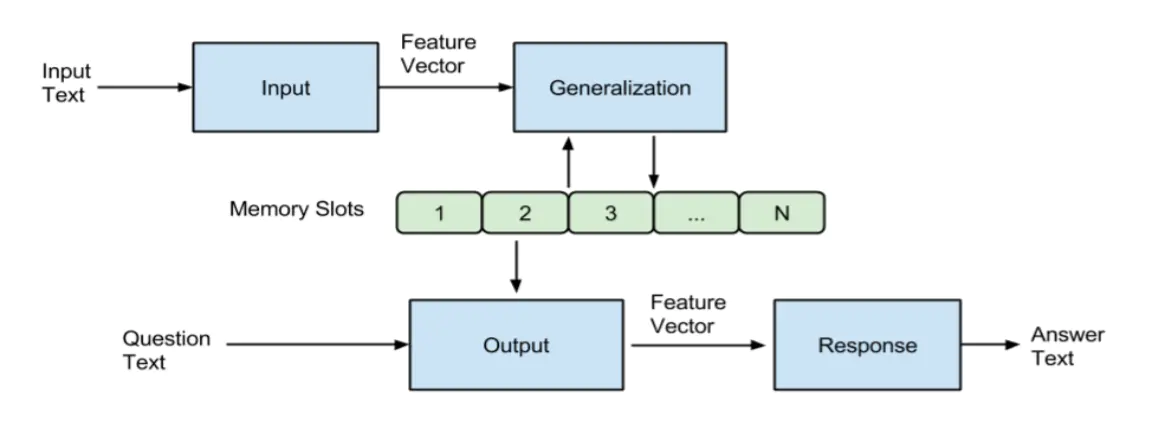
以下是各个过程的解释:

记忆网络Memory Network_网络_Irving_zhang的专栏-CSDN博客
记忆增强神经网络所要实现的通常不是分类、判别等一次性的操作。之所以要保存信息在内存中,是因为要对输入的数据进行一个多方位的“解读”,而这些解读是不可能保存在神经网络的训练参数中的,要通过存取内存来将网络解析的“概念”保存起来,当你向它“提问”的时候,它便可使用这些概念进行作答。又因为这些输入都是按顺序进行的,前一个输入对后一个有影响,所以就更需要使用内存来保存中间数据了。它有点类似于RNN,但是它是“可互动的”,而RNN依旧是一个“函数”。