枚举类型
枚举类型(enumerated types)定义了一组"符号名称/值"配对。例如,以下Color类型定义了一组符号,每个符号都标识一种颜色:
internal enum Color { While, //赋值0 Red, //赋值1 Green, //赋值2 Blue, //赋值3 Orange //赋值4 }
使用枚举类型的好处:
1)枚举类型使程序更容易编写、阅读和维护。有了枚举类型,符号名称可在代码中随便使用,开发人员不需要记住每个硬编码的含义。而且,一旦与符号名称对应的值发生变化,代码也可以简单的重新编译,不需要对源代码做出任何修改。除此之外,文档工具和其他实用程序能向开发人员显示有意义的符号名称。
2)枚举类型是强类型的。
在Microsoft .NET Framework中,枚举类型不只是编译器所关心的符号,它在类型系统中还具有"一等公民"的地位,能实现非常强大的操作。而在其他环境(比如非托管c++)中,枚举类型是没有这个特点的。
枚举类型都直接从System.Enum派生,后者从System.ValueType派生,而System.ValueType用从 System.Object派生。所以,枚举类型是值类型,可表示成未装箱和已装箱形式。然而,有别于其他值类型,枚举类型不能定义任何方法、属性和事件。不过可利用C#的"扩展方法"功能模拟向枚举类型添加方法。
编译枚举类型时,C#编译器会把每个符号转换成为类型的一个常量字段。例如,编译器会把前面的Color枚举类型看成以下代码
internal struct Color : System.Enum { //以下是一些公共常量,它们定义了Color的符号和值 public const Color While = (Color)0; public const Color Red = (Color)1; public const Color Green = (Color)2; public const Color Bule = (Color)3; public const Color Orange = (Color)4; //以下是一个公共实例字段,它包含一个Color变量的值, //不能写代码来直接引用这个实例字段 public Int32 value__; }
C#编译器实际上并不编译这段代码,因为它禁止定义从System.Enum这一特殊类型派生的类型。不过,可以通过上述伪类型定义了解内部工作方式。简单的说,枚举类型只是一个结构,其中定义了一组常量字段和一个实例字段。常量字段会嵌入程序集的元数据中,并可以通过反射来访问。这意味着可以在运行时获得与枚举类型关联的所有符号及其值。还意味着可以将一个字符串符号转换成对应的数值。这些操作是通过System.Enum基类型来提供的,该类型提供了几个静态和实例方法,可利用它们操作枚举类型的一个实例,从而避免了必须使用反射的麻烦。
提示:枚举类型定义的符号是常量值。所以当编译器发现代码引用了一个枚举类型的符号,就会在编译时用数值替换符号,代码将不再引用定义了符号的枚举类型。这意味着在运行时可能不需要定义了枚举类型的程序集,在编译时需要。
例如,System.Enum类型有一个GetUnderlyingType的静态方法,而System.Type类型有一个 GetEnumUnderlyingType的实例方法。
public static Type GetUnderlyingType (Type enumType); //System.Enum中定义 public Type GetEnumUnderlyingType (Type enumType); //System.Type中定义
这些方法返回用于容纳一个枚举类型的值的基础类型。每个枚举类型都有一个基础类型,它可以是byte,sbyte, short,ushort,int(最常用,也是C#默认的),uint,long,或ulong。虽然这些C#基元类型都有都有对象的FCL 类型,但C#编译器为了简化本身的实现,要求只能指定基元类型名称。如果使用FCL类型名称(如Int32),就会报错。
以下代码演示了如何声明一个基础类型为byte(System.Byte)的枚举类型:
interal enum Color :byte { While, Red, Green, Blue, Orange }
基于这个Color枚举类型,一下代码显示了GetUnderlyingType 的返回结果:
//以下代码会显示"System.Byte" Console.WriteLine(Enum.GetUnderlyingType(typeof(Color)));
C#编译器将枚举类型视为基元类型。所以,可以运用许多操作符(==,!=,<,>等等)来操作枚举类型的实例。所有这些操作符实际作用于枚举类型实例内部的value__实例字段。此外,C#编译器还允许将枚举类型的实例显式转型为一个不同的枚举类型。也可以显式将一个枚举类型实例转型为一个数值类型。
给定一个枚举类型的实例,可以调用System.Enum的静态方法GetValue或者System.Type的实例方法GetEnumValue获取一个数组,该数组的每一个元素都对应枚举类型中的一个符号名称,每个元素都包含符号名称的数值:
public static Array GetValues(Type enumType); //System.Enum中定义 public Array GetEnumValues(Type enumType); //System.Type中定义
这个方法结合ToString方法使用,可显示枚举类型中所有符号名称及其对应的数值,如下所示:
Color[] colors = (Color[])Enum.GetValues(typeof(Color)); Console.WriteLine("Number of symbols defined: " + colors.Length); Console.WriteLine("Value Symbol ----- ------"); foreach (Color color in colors) { // 以十进制和常规格式显示每个符号 Console.WriteLine("{0,5:D} {0:G}", color);
以上代码产生的输出如下:
Number of symbols defined: 5 Value Symbol ----- ------ 0 While 1 Red 2 Green 3 Blue 4 Orange
位标志
程序员经常要与位标识(bit flag)集合打交道。调用System.IO.File类型的GetAttributes方法,会返回FileAttributes类型的一个实例。FileAttributes类型是基本类型为Int32的枚举类型,其中每一位都反映了文件的一项属性。FileAttibutes类型在FCL中的定义如下:
[Flags] [Serializable] [ComVisible (true)] public enum FileAttributes { Archive = 0x00020, Compressed = 0x00800, Device = 0x00040, // Reserved for future use (NOT the w32 value). Directory = 0x00010, Encrypted = 0x04000, // NOT the w32 value Hidden = 0x00002, Normal = 0x00080, NotContentIndexed = 0x02000, Offline = 0x01000, ReadOnly = 0x00001, ReparsePoint = 0x00400, SparseFile = 0x00200, System = 0x00004, Temporary = 0x00100, #if NET_4_5 IntegrityStream = 0x8000, NoScrubData = 0x20000, #endif }
为了判断一个文件是否隐藏,可执行下面这样的代码:
String file = Assembly.GetEntryAssembly().Location; FileAttributes attributes = File.GetAttributes(file); Console.WriteLine("Is {0} hidden? {1}",file,(attributes & FileAttributes.Hidden) !=0);
以下代码演示了如何将一个文件的属性改为只读和隐藏:
File.SetAttributes(file,FileAttributes.ReadOnly | FileAttribute.Hidden);
正如FileAttributes类型展示的那样,经常都要用枚举类型来表示一组可以组合的位标志。不过,虽然枚举类型和位标志相似,但它们的语义不尽相同。例如,枚举类型表示单个数值,而位标识表示一组位,其中有些位是1,有些位是0.
定义用于标识位标志的枚举类型时,当然应该显式为每个符号分配一个数值。通常,每个符号都有单独的一个位处于on(1)状态.此外,经常都要定义一个值为0的None符号。还可以定义一些代表常用位组合的符号。另外,强烈建议向枚举类型应用System.Flags.Attribute这个定制的attribute类型,如下所示
[Flags] public enum Actions { Read = 0x0001, Write = 0x0002, ReadWrite = Actions.Read | Actions.Write, Delete = 0x0004, Query = 0x0008, Sync = 0x0010 }
因为Actions是枚举类型,所以在操作位标志枚举类型时,可以使用上一节描述的所有方法。
Actions actions = Actions.Read | Actions.Delete; //0x0005 Console.WriteLine(actions.ToString()); //"Read,Delete"
调用ToString时,它会视图将数值转换为对应的符号。现在的数值是0x0005,它没有对应的符号。不过,ToString方法检测到Actions类型上存在[Flags]这个attribute,所以ToString方法现在不会将该数值视为单独的值。相反,会将它视为一组位标志。由于0x0005有0x0001和0x0004组合而成,所以ToString会生成字符串"Read,Delete", 如果从Actions类型中删除[Flags]这个attribute,ToString方法返回"5"。
ToString方法啊允许以3种方式格式化输出G(常规)、D(十进制)和X(十六进制)。使用常规格式来格式化枚举类型的实例时,首先会检查类型,看它是否应用了[Flags]这个特性。没有应用就查找与该数值匹配的符号并返回符号。ToString方法的工作过程如下
1 获取枚举类型定义的数值集合,降序排列这些数值。
2 每个数值都和枚举实例中的值进行“按位与”计算(“&”,参与运算的两数各对应的二进位相与。只有对应的两个二进位都为1时,结果位才为1),假如结果等于数值,与该数值关联的字符串就附加到输出字符串上,对应的位会被认为已经考虑过了,会被关闭(设为0)。这一步不断重复,知道检查完所有数值,或知道枚举实例的所有位都被关闭。
3 检查完所有数值后,如果枚举枚举实例仍然不为0,表明枚举实例中一些处于on状态的位不对应任何已定义的符号。在这种情况下,ToString将枚举实例中的原始值作为字符串返回。
4 如果枚举实例原始值不为0,返回符号之间以逗号分隔的字符串。
5 如果枚举实例原始值为0,而且枚举类型定义的一个符号对应的是0值,就返回这个符号。
6 如果到达这一步,就返回0
永远不要对位标志枚举类型使用IsDefined方法,理由如下:
1)如果向IsDefined方法传递一个字符串,它不会将这个字符串拆分为单独的token来进行查找,而是视图查找整个字符串,把它看成是包含逗号的一个更大的符号。由于不能在枚举类型中定义含有逗号的符号,所以这个符号永远找不到。
2)如果向IsDefined方法传递一个数值,它会检查枚举类型是否定义了一个其对应数值和传入数值匹配的符号。由于位标志不能这样简单匹配,所以IsDefined通常会返回flase。
向枚举类型添加方法
现在,可以使用C#的扩展方法功能向枚举类型模拟添加方法。
如果想为FileAttributes枚举类型添加一些方法,可以定义一个包含了扩展方法的静态类,如下所示:
public static Boolean Set(this FileAttributes flags, FileAttributes testFlags) { return flags | testFlags; }
从表面看,我似乎真的在枚举类型上调用这些方法:
FileAttributes fa = FileAttributes.System;
fa = fa.Set(FileAttributes.ReadOnly);
数组
数组是允许将多个数据项作为集合来处理的机制。clr支持一维、多维和交错数组(即数组构成的数组)。所有数组类型都隐式地从System.Array抽象类派生,后者又派生自system.Object。这意味着数组始终是引用类型,是在托管堆上分配的。在应用程序的变量或字段中,包含的是对数组的引用,而不是包含数组本身的元素。如下例子
Int32[] myIntegers; //声明一个数组引用 myIntegers = new int32[100] //创建含有100个Int32的数组
在第一行代码中,myIntegers变量能指向一个一维数组(由Int32值构成)。myIntegers刚开始被设为null,因为当时还没有分配数组。第二行代码分配了含有100个Int32值的一个数组,所有Int32都被初始化为0。由于数组是引用类型,所有托管堆上还包含一个未装箱Int32所需要的内存块。实际上,除了数组元素,数字对象占据的内存块还包含一个类型对象指针、一个同步块索引和一些额外的成员(overhead)。该数组的内存块地址被返回并保存到myIntegers变量中。
为了符common Language Specification,CLS 的要求,所有数组都必须是0基数组(即最小索引为0)。这样就可以用C#的方法创建数组,并将该数组的引用传给其他语言。此外,由于0基数组是最常用的数组,所以Microsoft花了很大力气优化性能。
每个数组都关联了一些额外的开销信息。这些信息包括数组的秩、数组每一维的下限和每一维的长度。开销信息还包含数组元素类型。
C#也支持多维数组。下面演示了几个多维数组的例子:
// 创建一个二维数组,由Double值构成 Double[,] myDoubles = new Double[10,20]; // 创建一个三位数组,由String引用构成 String[,,] myStrings = new String[5,3,10]; CLR还支持交错数组,即由数组构成的数组。下面例子演示了如何创建一个多边形数组,其中每一个多边形都由一个Point实例数组构成。 // 创建一个含有Point数组的一维数组 Point[][] myPolygons = new Point[3][]; // myPolygons[0]引用一个含有10个Point实例的数组 myPolygons[0] = new Point[10]; // myPolygons[1]引用一个含有20个Point实例的数组 myPolygons[1] = new Point[20]; // myPolygons[2]引用一个含有30个Point实例的数组 myPolygons[2] = new Point[30]; // 显示第一个多边形中的Point for (Int32 x =0 ; x < myPolygons[0].Length; x++) { Console.WriteLine(myPolygons[0][x]); }
注意:CLR会验证数组索引的有效性。换句话说,不能创建一个含有100个元素的数组(索引编号为0到99),又试图访问索引为-5或100的元素。
初始化数组元素
前面展示了如何创建数组对象,如何初始化数组中的元素。C#允许用一个语句来同时做两件事。例如:
String[] names = new String[] { "Aidan", "Grant" };
大括号中的以逗号分隔的数据项称为数组初始化器(array initializer)。每个数据项都可以是一个任意复杂度的表达式;在多维数组的情况下,则可以是一个嵌套的数组初始化器。可利用C#的“隐式类型的局部变量”的数组功能来简化代码:
//利用c#的隐式类型的局部变量公告呢 var names = new string[] { "Aidan", "Grant", null};
编译器推断局部变量names是string[]类型,因为那是赋值操作符(=)右侧的表达式的类型。
可利用c#的隐式类型的数组功能让编译器推断数组元素的类型。注意,下面这行代码没有在new和[]指定类型
//利用c#的隐式类型的局部变量和隐式类型的数组功能 var names = new[] { "Aidan", "Grant", null};
在上一行中,编译器检查数组中用于初始化数组元素的表达式的类型,并选择所有元素最接近的共同基类作为数组的类型。在本例中,编译器发现两个String和一个null。由于null可隐式转型成为任意引用类型(包括String),所以编译器推断应该创建和初始化一个由String引用构成的数组。
给定以下代码:
var names = new[] { "Aidan", "Grant", 123};
编译器是会报错的,虽然String类和Int32共同基类是Object,意味着编译器不得不创建Object引用了一个数组,然后对123进行装箱,并让最后一个数组元素引用已装箱的,值为123的一个Int32。但C#团队认为,隐式对数组 元素进行装箱是一个代价昂贵的操作,所以要做编译时报错。
在C#中还可以这样初始化数组:
String[] names = { "Aidan", "Grant" };
但是C#不允许在这种语法中使用隐式类型的局部变量:
var names = { "Aidan", "Grant" };
最后来看下"隐式类型的数组"如何与"匿名类型"和"隐式类型的局部变量"组合使用。
// 使用C#的隐式类型的局部变量、隐式类型的数组和匿名类型 var kids = new[] {new { Name="Aidan" }, new { Name="Grant" }}; // 示例用法 foreach (var kid in kids) Console.WriteLine(kid.Name);
输出结果:
Aidan
Grant
创建下限非零的数组
可以调用数组的静态CreateInstance方法来动态创建自己的数组。该方法有若干个重载版本,允许指定数组元素的类型、数组的维数、每一维的下限和每一维的元素数目。CreateInstance为数组分配内存,将参数信息保存到数组的内存块的额外开销(overhead)部分。然后返回对该数组的一个引用。
数组转型
对于元素为引用类型的数组,CLR允许将数组元素从一种类型隐式转型到另一种类型。为了成功转型,两个数组类型必须维数相等,而且从源类型到目标类型,必须存在一个隐式或显示转换。CLR不允许将值类型元素的数组转型为其他任何类型。(不过为了模拟实现这种效果,可利用Array.Copy方法创建一个新数组并在其中填充数据)。下面演示了数组转型过程:
// 创建一个二维FileStream数组 FileStream[,] fs2dim = new FileStream[5, 10]; // 隐式转型为一个二维Object数组 Object[,] o2dim = fs2dim; // 不能从二维数组转型为一维数组 //Stream[] s1dim = (Stream[]) o2dim; // 显式转型为二维Stream数组 Stream[,] s2dim = (Stream[,]) o2dim; // 显式转型为二维String数组 // 能通过编译,但在运行时会抛出异常 String[,] st2dim = (String[,]) o2dim; // 创建一个意味Int32数组(元素是值类型) Int32[] i1dim = new Int32[5]; // 不能将值类型的数组转型为其他任何类型 // Object[] o1dim = (Object[]) i1dim; // 创建一个新数组,使用Array.Copy将元数组中的每一个元素 // 转型为目标数组中的元素类型,并把它们复制过去 // 下面的代码创建一个元素为引用类型的数组, // 每个元素都是对已装箱的Int32的引用 Object[] o1dim = new Object[i1dim.Length]; Array.Copy(i1dim, o1dim, 0);
Array.Copy方法的作用不仅仅是将元素从一个数组复制到另一个数组。Copy方法还能正确处理内存的重叠区域。 Copy方法还能在复制每一个数组元素时进行必要的类型转换。Copy方法能执行以下转换:
1)将值类型的元素装箱为引用类型的元素,比如将一个Int32[]复制到一个Object[]中。
2)将引用类型的元素拆箱为值类型的元素,比如将一个Object[]复制到Int32[]中。
3)加宽CLR基元值类型,比如将一个Int32[]的元素复制到一个Double[]中。
4) 在两个数组之间复制时,如果仅从数组类型证明不了两者的兼容性,比如从Object[]转型为IFormattable[],就根据需要对元素进行乡下类型转换。如果Object[]中的每个对象都实现了IFormattable,Copy方法就能执行成功。
有时确实需要将数组从一种类型转换为另一种类型。这种功能称为数据协变性。利用数组协变性时,应该清楚由此带来的性能损失。
String[] sa =new stirng [100]; Object[] oa=sa; oa[5]=”JEFF”;//性能损失:clr检查oa的元素类型是不是string。检查通过 oa[3]=5;// 性能损失:clr检查oa的元素类型是不是string。发现有错,抛出异常
注意:如果只需要把数组中某些元素复制到另一个数组,可以选择System.Buffer的BlockCopy方法,它的执行速度比Array.Copy方法快。不过,Buffer的BlockCopy方法只支持基元类型,不提供像Array的Copy方法那样的转型能力。方法的Int32参数代表的是数组中的字节偏移量,而非元素索引。如果需要可靠的将一个数组中的元素复制到另一个数组,应该使用System.Array的ConstrainedCopy方法,该方法能保证不破坏目标数组中的数组的前提下完成复制,或者抛出异常。另外,它不执行任何装箱、拆箱或向下类型转换。
所有数组都隐式派生自system.array
如果像下面这样声明一个数组变量:
FileStream[] fsArray;
CLR会为AppDomain自动创建一个FileStream[]类型。这个类型将隐式派生自System.Array类型;因此,System.Array类型定义的所有实例方法和属性都将有FileStream[]继承,使这些方法和属性能通过fsArray变量调用。
所有数组都隐式实现IEnumerable,ICollection和IList
许多方法都能操作各种集合对象,因为他们声明为允许获取IEnumerable,ICollection和IList等参数。可将数组传给这些方法,因为System.Array也实现了这三个接口。System.Array之所以实现这些非泛型接口,是因为这些接口将所有元素都视为Systm.Object。然而,最好让System.Array实现这个接口的泛型形式,提供更好的编译时类型安全性和更好的性能。
不过,由于涉及多维数组和非0基数组的问题,clr团队不希望system.Array实现IEnumerable<T>,ICollection<t>和IList<T>。若在System.Array上定义这些接口,就会为所有数组类型启用这些接口。所以,clr没有那么做,而是耍了一个小花招;创建一维0基数组类型时,clr自动使数组类型实现IEnumerable<T>,ICollection<t>和IList<T>。同时,还为数组类型的所有基类型实现这三个接口,只要他们是引用类型。
如果数组包含值类型的元素,数组类型不会为元素的基类型实现接口。这是因为值类型的数组在内存中的布局与引用类型不同。
数组的传递和返回
数组作为实参传给一个方法时,实际传递的是对该数组的引用。因此,被调用的方法能修改数组中的元素。如果不想被修改,必须生成数组的一个拷贝,并将这个拷贝传给方法。注意,Array.Copy方法执行的是浅拷贝。换言之,如果数组元素是引用类型,新数组将引用现有对象。
类似地,有的方法返回对数组的引用。如果方法构造并初始化数组,返回数组引用是没有问题的。但假如方法返回的是对一个字段维护的内部数组的引用,就必须决定是否向让该方法的调用者直接访问这个数组及其元素。如果是就可以返回数组引用。但是通常情况下,你并不希望方法的调用这获得这个访问权限。所以,方法应该构造一个新数组,并调用Array.Copy返回对新数组的一个引用。
如果定义一个返回数组引用的方法,而且该数组不包含元素,那么方法既可以返回null,又可以放回对包含零个元素的一个数组的引用。实现这种方法时,Microsoft强烈建议让它返回后者,因为这样做能简化调用该方法时需要的代码。
// 这段代码更容易写,更容易理解 Appointment[] app = GetAppointmentForToday(); for (Int32 a =0; a< app.Length; a++) { // 对app[a]执行操作 } 如果返回null的话: // 写起来麻烦,不容易理解 Appointment[] app = GetAppointmentForToday(); if( app !=null ) { for (Int32 a =0; a< app.Length; a++) { // 对app[a]执行操作 } }
将方法设计为返回对含有0个元素的一个数组的引用,而不是返回null,该方法的调用者就能更清爽地使用该方法。顺便提一句,对字段也应如此。如果类型中有一个字段是数组引用,应考虑让这个字段始终引用数组,即使数组中不包含任何元素。
数组的内部工作原理
CLR内部实际支持两种不同的数组
1)下限为0的数组。这些数组有时称为SZ数组或向量。
2)下限未知的一维或多维数组。
可执行一下代码来实际地查看不同种类的输出
public static void Main() { Array a; // 创建一个一维数组的0基数组,其中不包含任何元素 a = new String[0]; Console.WriteLine(a.GetType()); // System.String[] // 创建一个一维数组的0基数组,其中不包含任何元素 a = Array.CreateInstance(typeof(String), new Int32[] { 0 }, new Int32[] { 0 }); Console.WriteLine(a.GetType()); // System.String[] // 创建一个一维数组的1基数组,其中不包含任何元素 a = Array.CreateInstance(typeof(String), new Int32[] { 0 }, new Int32[] { 1 }); Console.WriteLine(a.GetType()); // System.String[*] <-- 注意! Console.WriteLine(); // 创建一个二维数组的0基数组,其中不包含任何元素 a = new String[0, 0]; Console.WriteLine(a.GetType()); // System.String[,] // 创建一个二维数组的0基数组,其中不包含任何元素 a = Array.CreateInstance(typeof(String), new Int32[] { 0, 0 }, new Int32[] { 0, 0 }); Console.WriteLine(a.GetType()); // System.String[,] // 创建一个二维数组的1基数组,其中不包含任何元素 a = Array.CreateInstance(typeof(String), new Int32[] { 0, 0 }, new Int32[] { 1, 1 }); Console.WriteLine(a.GetType()); // System.String[,] }
对于一维数组,0基数组显示的类型名称是System.String[],但1基数组显示的是System.String[*]。*符号表示CLR知道该数组不是0基的。注意,C#不允许声明String[*]类型的变量,因此不能使用C#语法来访问一维的非0基数组。尽管可以调用Array的GetValue和SetValue方法来访问数组的元素,但速度会比较慢,毕竟有方法调用的开销。
对于多维数组,0基和1基数组会显示同样的类型名称:System.String[,]。在运行时,CLR将对所有多维数组都视为非0基数组。这自然会人觉得应该显示为System.String[*,*]。但是,对于多维数组,CLR决定不用*符号,避免开发人员对*产生混淆。
访问一维0基数组的元素比访问非0基数组或多维数组的元素稍快一些。首先,有一些特殊的IL指令,比如newarr,ldelem,ldelema等用于处理一维0基数组,这些特殊IL指令会导致JIT编译器生成优化代码。例如,jit编译器生成的代码假定数组是0基的,所以在访问元素时不需要从指定索引中减去一个偏移量。其次,一般情况下,jit编译器能将索引范围检查代码从循环中拿出,导致它只执行一次。
其次,JIT编译器知道for循环要访问0到Length-1之间的数组元素。所以,JIT编译器生成的代码会在运行时测试所有数组元素的访问都在数组有效访问内,这个检查会在循环之前发生。而非零基数组,检查会在循环内部执行。
如果很关心性能,请考虑由数组构成的数组(即交错数组)来替代矩形数组。
c#和clr还允许使用unsafe(不可验证)代码访问数组,这种技术实际能在访问数组时关闭索引上下限检查。这种不安全的数组访问技术适合很多值类型数组。这个功能很强大,但是使用需谨慎,因为它允许直接内存访问,访问越界不会抛出异常。
下面C#代码演示了访问二维数组的三种方式(安全、交错和不安全):


internal static class MultiDimArrayPerformance { private const Int32 c_numElements = 10000; public static void Go() { const Int32 testCount = 10; Stopwatch sw; // 声明一个二维数组 Int32[,] a2Dim = new Int32[c_numElements, c_numElements]; // 将一个二维数组声明为交错数组 Int32[][] aJagged = new Int32[c_numElements][]; for (Int32 x = 0; x < c_numElements; x++) aJagged[x] = new Int32[c_numElements]; // 1: 用普通的安全技术访问数组中的所有元素 sw = Stopwatch.StartNew(); for (Int32 test = 0; test < testCount; test++) Safe2DimArrayAccess(a2Dim); Console.WriteLine("{0}: Safe2DimArrayAccess", sw.Elapsed); // 2: 用交错数组技术访问数组中的所有元素 sw = Stopwatch.StartNew(); for (Int32 test = 0; test < testCount; test++) SafeJaggedArrayAccess(aJagged); Console.WriteLine("{0}: SafeJaggedArrayAccess", sw.Elapsed); // 3: 用unsafe访问数组中的所有元素 sw = Stopwatch.StartNew(); for (Int32 test = 0; test < testCount; test++) Unsafe2DimArrayAccess(a2Dim); Console.WriteLine("{0}: Unsafe2DimArrayAccess", sw.Elapsed); Console.ReadLine(); } private static Int32 Safe2DimArrayAccess(Int32[,] a) { Int32 sum = 0; for (Int32 x = 0; x < c_numElements; x++) { for (Int32 y = 0; y < c_numElements; y++) { sum += a[x, y]; } } return sum; } private static Int32 SafeJaggedArrayAccess(Int32[][] a) { Int32 sum = 0; for (Int32 x = 0; x < c_numElements; x++) { for (Int32 y = 0; y < c_numElements; y++) { sum += a[x][y]; } } return sum; } private static unsafe Int32 Unsafe2DimArrayAccess(Int32[,] a) { Int32 sum = 0; fixed (Int32* pi = a) { for (Int32 x = 0; x < c_numElements; x++) { Int32 baseOfDim = x * c_numElements; for (Int32 y = 0; y < c_numElements; y++) { sum += pi[baseOfDim + y]; } } } return sum; } }
本机结果是:
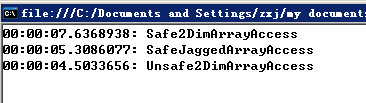
可以看出,安全二维数组访问技术最慢。安全交错数组访问时间略少于安全二维数组。不过应该注意的是:创建交错数组所花的时间多于创建多维数组所花的时间,因为创建交错数组时,要求在堆上为每一维分配一个对象,造成垃圾回收器的周期性活动。所以你可以这样权衡:如果需要创建大量"多个维的数组",而不会频繁访问它的元素,那么创建多维数组就要快点。如果"多个维的数组"只需创建一次,而且要频繁访问它的元素,那么交错数组性能要好点。当然,大多数应用中,后一种情况更常见。
最后请注意,不安全和安全二维数组访问技术的速度大致相同。但是,考虑到它访问是单个二维数组(产生一次内存分配),二不像交错数组那样需要许多次内存分配。所以它的速度是所有技术中最快的。
不安全的数组访问和固定大小的数组
如果性能是首要目标,请避免在堆上分配托管的数组对象。相反,应该在线程栈上分配数组,这是通过C#的 stackalloc语句来完成的(它很大程度上类似于c的alloca函数)。stackalloc语句只能创建一维0基、由值类型元素构成的数组,而且值类型绝对不能包含任何引用类型的字段。实际上,应该把它的作用看成是分配一个内存块,这个内存块可以使用不安全的指针来操纵。所以,不能将这个内存缓存区的地址传给大部分FCL方法。当然,在栈上分配的内存(数组)会在方法返回时自动释放:这对增强性能起到一定作用。使用这个功能要求为c#编译器指定/unsafe开关。
以下代码显示如何使用C#的stackalloc语句:
internal static class StackallocAndInlineArrays { public static void Go() { StackallocDemo(); InlineArrayDemo(); } private static void StackallocDemo() { unsafe { const Int32 width = 20; Char* pc = stackalloc Char[width]; // 在栈上分配数组 String s = "Jeffrey Richter"; // 15 个字符 for (Int32 index = 0; index < width; index++) { pc[width - index - 1] = (index < s.Length) ? s[index] : '.'; } //显示".....rethciR yerffeJ" Console.WriteLine(new String(pc, 0, width)); } } private static void InlineArrayDemo() { unsafe { CharArray ca; // 在栈上分配数组 Int32 widthInBytes = sizeof(CharArray); Int32 width = widthInBytes / 2; String s = "Jeffrey Richter"; // 15 个字符 for (Int32 index = 0; index < width; index++) { ca.Characters[width - index - 1] = (index < s.Length) ? s[index] : '.'; } //显示".....rethciR yerffeJ" Console.WriteLine(new String(ca.Characters, 0, width)); } } private unsafe struct CharArray { // 这个数组以内联的方式嵌入结构 public fixed Char Characters[20]; } }
通常,因为数组是引用类型,所以在一个结构中定义的数组字段实际只是指向数组的一个指针;数组本身在结构的内存的外部。不过,也可以像上述代码中的CharArray结构那样,直接将数组嵌入结构中。要在结构中直接嵌入一个数组,需要满足以下几个要求:
1)类型必须是结构(值类型);不能在类(引用类型)中嵌入数组。
2)字段或其定义结构必须用unsafe关键字标记
3)数组字段必须使用fixed关键字标记
4)数组必须是一维0基数组。
5)数组的元素类型必须是一下类型之一:Boolean,Char,SByte,Byte,Int16,Int32,UInt16,UInt32,Int64,UInt64,Single或Double。
内联(内嵌)数组常用于和非托管代码进行互操作,而且非托管数据结构也有一个内联数组。不过,也可用于其他情况。