如果一个C#developer,对CLR没有了解,那就只能是入门级别。未来.NET CORE是趋势,但是.NET CORE 也是基于CoreCLR的,而CLR和CoreCLR其实差别不大,从runtime那部分看几乎没有区别,进程管理,GC,JIT这些基本上是一样的。
CLR vie C#这本书很久之前就已经读过了,但是一直没有写个像样的总结。这次我重新读了一遍,把我认为比较重要的点记录下来。
一、源代码编译成托管模块
CLR(Common Language Runtime,公共语言运行时)是一个由多种编译语言使用的“运行时”。CLR的核心功能(比如内存管理、程序集加载、安全性、异常处理和线程同步)可由面向CLR的所有语言使用。
事实上,在运行时,CLR根本不关心开发人员用哪一种语言写源代码。无论选择哪一种语言及其编译器,结果都是托管模块(managed module)。
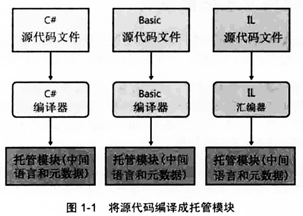

native code compilers生成的是面向特定cpu架构(比如x84,x64或ARM)的代码。相反,每个面向CLR的编译器生成的都是IL(中间语言)代码。IL代码有时称为托管代码(managed code),因为CLR管理他的执行。
元数据:(metadata)元数据简单地说就是一个数据表集合。一些数据表描述了模块中定了什么(比如类型及成员),另一些描述了模块引用了什么(比如导出的类型及其成员)。元数据是一些老技术的超集,不如COM的类型库和IDL文件,元数据总是与包含IL代码的文件管理。元数据有多种用途,下面仅列举一部分:
1 元数据避免了编译时对原生C/C++头和 库文件的需求,因为在实现类型/成员的IL代码文件中,已包含有关引用类型/成员的全部信息。编译器直接从托管模块读取元数据。
2 Visual Studio用元数据帮助你写代码。智能感知(intelliSense)技术会解析元数据,告诉你一个类型提供了哪些方法、属性、事件和字段。以及相应参数。
3 CLR的代码验证过程使用元数据确保代码只执行”类型安全”的操作
4 元数据允许垃圾回收器跟踪对象生成期。垃圾回收器能判断任何对象的类型,并从元数据知道哪个对象中的那些字段引用了其他对象。
二、托管模块合并程序集
CLR实际不和模块工作,他和程序集工作。程序集(assembly)是抽象概念,首先是一个或多个模块/资源文件的逻辑性分组。其次,程序集是重用、安全性以及版本控制的最小单元。在CLR的世界中,程序集相当于”组件”。
下图有助于你理解程序集。图中一些托管模块和资源(或数据)文件准备交由一个工具(编译器)处理。工具生成代表文件逻辑分组的一个PE32(+)文件。实际发生的事情是,这个PE32(+)文件包含一个名为清单(manifest)的数据块。清单也是元数据表的集合。这些表描述了构成程序集的文件、程序集中 的文件所实现的公共导出的类型(就是程序集中定义的public类型,他们在程序集内外部均可见)以及与程序集关联的资源或数据文件。
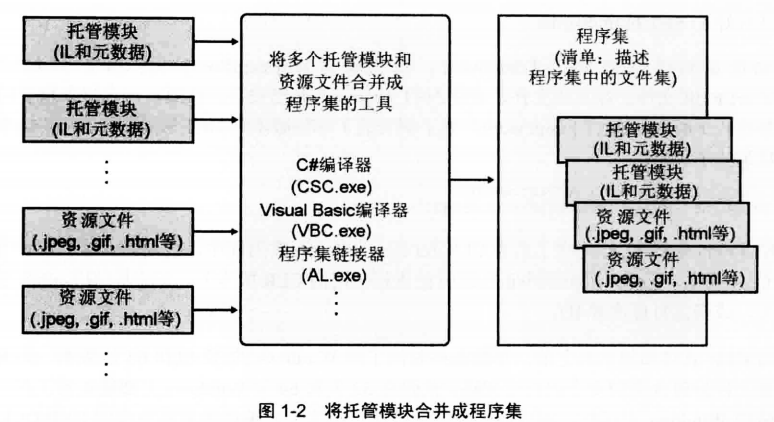
在程序集的模块中,还包含与引用的程序集有关的信息(包含他们的版本号)。这些信息使程序集能够自描述(self-describing)。也就是说,CLR能判断为了执行程序集中的代码,程序集的直接依赖对象(immediate dependenct)是什么。不需要在注册表或者ADDS中保存额外的信息。由于无需额外信息,所以和非托管组件相比,程序集更容易部署。
三、加载公共语言运行时
生成的每个程序集可以是可执行引用程序,也可以是DLL(其中含有一组由可执行程序使用的类型)。当然,最终是由CLR管理这些程序集中的代码的执行。这意味着目标及其必须安装好.NET Framework。
四、执行程序集的代码
如前所述,托管程序集同时包含元数据和IL。IL是与CPU无关的及其语言,是Microsoft在请教了很多商业及学术性语言/编译器的作者之后,费尽心思开发出来的。IL比大多数CPU及其语言都高级。IL能访问和操作对象类型,并提供了指令来创建和初始化对象、调用对象上的虚方法以及直接操作数据元素。甚至提供了抛出和捕捉异常的指令来实现错误处理。可将IL视为一种面向对象的机器语言。
为了执行方法,首先必须把方法的IL转换成本机(native)CPU指令。这是CLR的JIT(just-in-time)编译器的职责。下图展示了方法首次调用时的执行过程。
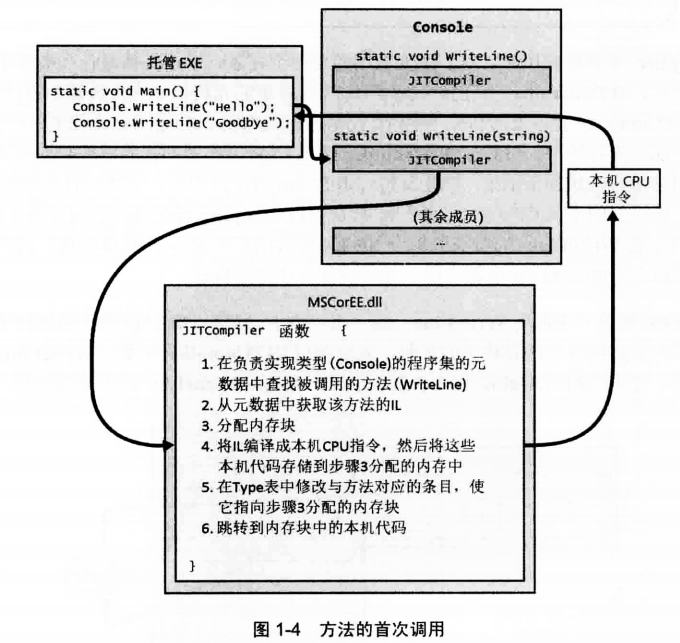
就在main方法执行之前,CLR会检查出Main的代码引用的所有类型。这导致CLR分配一个内部数据结构来管理对引用类型的访问。如上图中的main方法引用了一个Console类型,导致CLR分配一个内部结构。在这个内部数据结构中,Console类型定义的每个方法都有一个对应的记录项。每个记录项都含有一个地址,根据此地址即可找到方法的实现。对这个结构初始化时,CLR将每个记录项都指向包含在CLR内部的一个未编档函数(JITCompiler)。
main方法首次调用writeline时,JITCompiler函数会被调用。JITCompiler函数负责将方法的IL代码编译成本机CPU指令。由于IL是“即时”(just in time)编译的,所以通常将CLR的这个组件称为JIT编译器。
方法仅在首次调用时才会有一些性能损失。以后对该方法的所有调用都以本机代码的形式全速运行,无需重新验证IL并把它编译成本机代码。
JIT编译器将本机CPU指令存储到动态内存中。这意味着一旦应用程序终止,编译好的代码也会被丢弃。所以,将来再次运行应用程序,或者同时启动应用程序的两个实例(使用两个不同的操作系统进程),JIT编译器必须再次将IL编译成本机指令。对于某些应用程序,这可能显著增加内存消耗。
4.1 IL和验证
IL基于栈。这意味着它的所有指令都要将操作数压入(push)一个执行栈,并从栈弹出(pop)结果。由于IL没有提供操作寄存器的指令,所以人们可以很容易地创建新的语言和编译器,生成面向CLR的代码。
IL指令还是“无类型”(typeless)的。例如,IL提供了add指令将压入栈的最后两个操作数加到一起。add指令不分32位和64位版本。add指令执行时,他判断栈中的操作数的类型,并执行恰当的操作。
IL最大的优势不是他对底层CPU的抽象,而是应用程序的健壮性和安全性。将IL编译成本机CPU指令时,CLR执行一个名为验证的过程。这个过程会检查高级IL代码,确定代码所做的一切都是安全的。例如,会核实调用的每个方法都有正确数量的参数,传给每个方法的每个参数都有正确的类型,每个方法的返回值都得到了正确的使用,每个方法都有一个返回语句等等。托管模块的元数据包含验证过程要用到的所有方法及类型信息。
windows的每个进程都有自己的虚拟地址空间。独立地址空间之所以必要,是因为不能简单地新人一个应用程序的代码。应用程序完全可能读写无效的内存地址(令人遗憾的是,这种情况时有发生)。将每个windows进程都放到独立的地址空间,将获得健壮性与稳定性;一个进程干扰不到另一个进程。
然而,通过验证托管代码,可以确保代码不会不正确地访问内存,不会干扰到另一个应用程序的代码。这样就可以放心地将多个托管应用程序放到同一个windows虚拟地址空间运行。
由于windows进程需要大量操作系统资源,所以进程数量太多,会损害性能并制约可用的资源。用一个进程运行多个应用程序,可减少进程数,从而增强性能,减少所需的资源,健壮性也没有丝毫下降。这是托管代码相较于非托管代码的另一个优势。
事实上,clr确实提供了一个操作系统进程执行多个托管应用程序的能力。每个托管应用程序都在一个AppDomain中执行。每个托管EXE文件默认都在它自己的独立地址空间中运行,这个地址空间只有一个AppDomain。然后,CLR的宿主进程(比如IIS或者Microsoft SQL Server)可决定一个进程中运行多个AppDomain。
4.2 不安全的代码
C#编译器默认生成安全代码,这种代码的安全性可以验证。然而,C#编译器也允许开发人员写不安全的代码。不安全代码允许直接操作内存地址,并可操作这些地址处的字节。这是一个非常强大的功能,通常只有在与非托管代码进行互操作,或者在提升对效率要求极高的一个算法的性能的时候,才需要这样做。(不安全代码的所有方法都要用unsafe关键字标记)