STL提供了两个用来计算排列组合关系的算法,分别是next_permutation和prev_permutation。首先我们必须了解什么是“下一个”排列组合,什么是“前一个”排列组合。考虑三个字符所组成的序列{a,b,c}。
这个序列有六个可能的排列组合:abc,acb,bac,bca,cab,cba。这些排列组合根据less-than操作符做字典顺序(lexicographical)的排序。也就是说,abc名列第一,因为每一个元素都小于其后的元素。acb是次一个排列组合,因为它是固定了a(序列内最小元素)之后所做的新组合。
同样道理,那些固定b(序列中次小元素)而做的排列组合,在次序上将先于那些固定c而做的排列组合。以bac和bca为例,bac在bca之前,因为次序ac小于序列ca。面对bca,我们可以说其前一个排列组合是bac,而其后一个排列组合是cab。序列abc没有“前一个”排列组合,cba没有“后一个”排列组合。
next_permutation()会取得[first,last)所标示之序列的下一个排列组合,如果没有下一个排列组合,便返回false;否则返回true。这个算法有两个版本。版本一使用元素型别所提供的less-than操作符来决定下一个排列组合,版本二则是以仿函数comp来决定。
算法思想:
1.首先从最尾端开始往前寻找两个相邻元素,令第一元素为*i,第二元素为*ii,且满足*i<*ii。
2.找到这样一组相邻元素后,再从最尾端开始往前检验,找出第一个大于*i的元素,令为*j,将i,j元素对调(swap)。
3.再将ii之后的所有元素颠倒(reverse)排序。
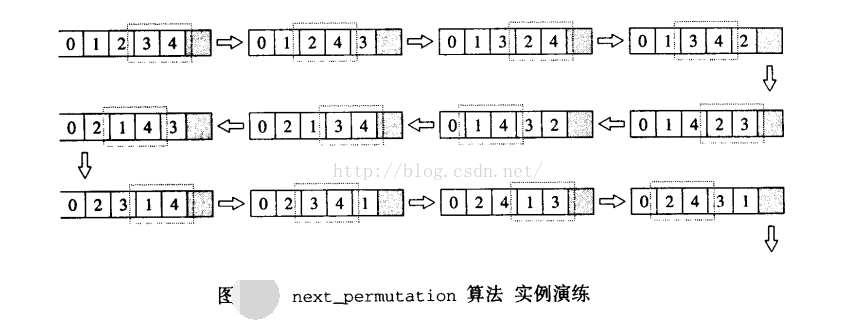
举个实例,假设有序列{0,1,2,3,4},下图便是套用上述演算法则,一步一步获得“下一个”排列组合。图中只框出那符合“一元素为*i,第二元素为*ii,且满足*i<*ii ”的相邻两元素,至于寻找适当的j、对调、逆转等操作并未显示出。
以下便是版本一的实现细节。版本二相当类似,就不列出来了。