1、数据来源
(1)数据来源
来自kaggle的数据集Titanic:Titanic: Machine Learning from Disaster
train文档数据是用来分析和建模,包含有生存情况信息;test数据是用来最终预测其生存情况并生成结果文件。
2、分析流程
(1)不同变量跟生存情况的关系分析;
(2)查看缺失值并对缺失值进行处理;
(3)建立模型并预测;
(4)提交预测结果,查看网站排名。
3、数据分析
载入文件:
import pandas #中文的话这样打开,不会出现Initializing from file failed这种错误 f=open("C:/Users/中文的话/Desktop/Kaggle_Titanic/train.csv") titanic=pandas.read_csv(f) titanic.describe()
data_train.info()
#从datafrom中得到一些信息
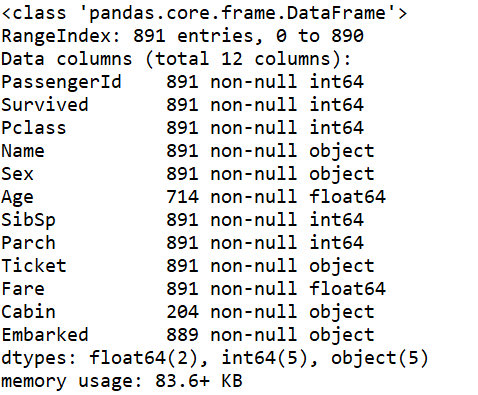
可以看到所有的缺失值信息
用可视化分析观察各部分与生还的关系:
import matplotlib.pyplot as plt
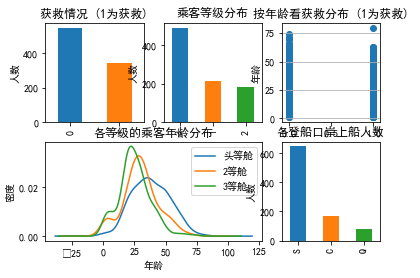
plt.rcParams['font.sans-serif']=['SimHei']#用来显示正常中文标签 fig = plt.figure() fig.set(alpha=0.2) # 设定图表颜色alpha参数 plt.subplot2grid((2,3),(0,0)) # 在一张大图里分列几个小图 data_train.Survived.value_counts().plot(kind='bar')# 柱状图 plt.title(u"获救情况 (1为获救)") # 标题 plt.ylabel(u"人数") plt.subplot2grid((2,3),(0,1)) data_train.Pclass.value_counts().plot(kind="bar") plt.ylabel(u"人数") plt.title(u"乘客等级分布") plt.subplot2grid((2,3),(0,2)) plt.scatter(data_train.Survived, data_train.Age) plt.ylabel(u"年龄") # 设定纵坐标名称 plt.grid(b=True, which='major', axis='y') plt.title(u"按年龄看获救分布 (1为获救)") plt.subplot2grid((2,3),(1,0), colspan=2) data_train.Age[data_train.Pclass == 1].plot(kind='kde') data_train.Age[data_train.Pclass == 2].plot(kind='kde') data_train.Age[data_train.Pclass == 3].plot(kind='kde') plt.xlabel(u"年龄")# plots an axis lable plt.ylabel(u"密度") plt.title(u"各等级的乘客年龄分布") plt.legend((u'头等舱', u'2等舱',u'3等舱'),loc='best') # sets our legend for our graph. plt.subplot2grid((2,3),(1,2)) data_train.Embarked.value_counts().plot(kind='bar') plt.title(u"各登船口岸上船人数") plt.ylabel(u"人数") plt.show()
#看看各乘客等级的获救情况 fig = plt.figure() fig.set(alpha=0.2) # 设定图表颜色alpha参数 Survived_m = data_train.Pclass[data_train.Survived == 0].value_counts() Survived_f = data_train.Pclass[data_train.Survived == 1].value_counts() df=pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0}) df.plot(kind='bar', stacked=True) plt.title(u"各乘客等级的获救情况") plt.xlabel(u"乘客等级") plt.ylabel(u"人数")

可以看出,等级高的获救的可能性大。。。
#看看各性别的获救情况 fig = plt.figure() fig.set(alpha=0.2) # 设定图表颜色alpha参数 Survived_m = data_train.Survived[data_train.Sex == 'male'].value_counts() Survived_f = data_train.Survived[data_train.Sex == 'female'].value_counts() df=pd.DataFrame({u'男性':Survived_m, u'女性':Survived_f}) df.plot(kind='bar', stacked=True) plt.title(u"按性别看获救情况") plt.xlabel(u"性别") plt.ylabel(u"人数") plt.show()
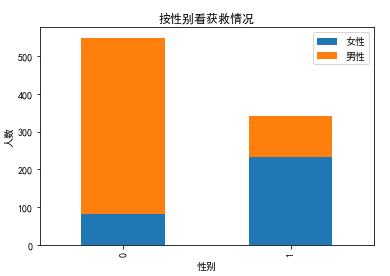
性别对获救的影响还是很大的。。
#看看各登录港口的获救情况 fig = plt.figure() fig.set(alpha=0.2) # 设定图表颜色alpha参数 Survived_m = data_train.Embarked[data_train.Survived == 0].value_counts() Survived_f = data_train.Embarked[data_train.Survived == 1].value_counts() df=pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0}) df.plot(kind='bar', stacked=True) plt.title(u"各登录港口乘客的获救情况") plt.xlabel(u"登录港口") plt.ylabel(u"人数")
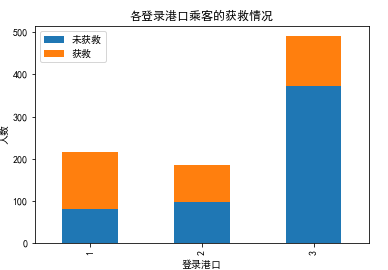
可以看出关系不太大。。。
#查看相关性矩阵 corrDf = data_train.corr() print(corrDf)
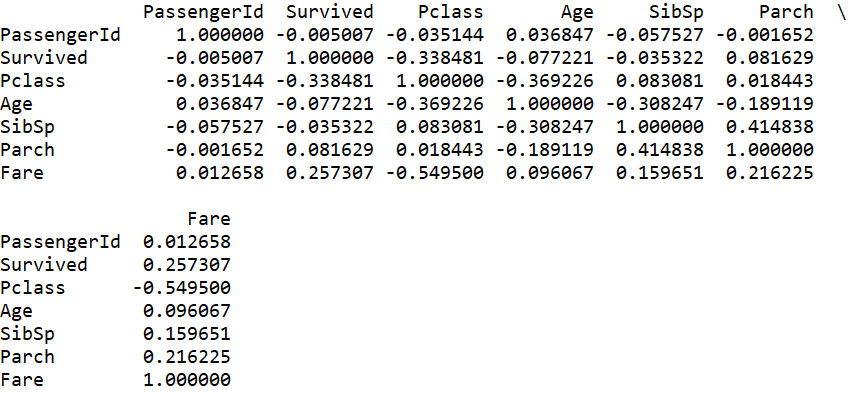
#相关性排序 print(corrDf['Survived'].sort_values(ascending =False))
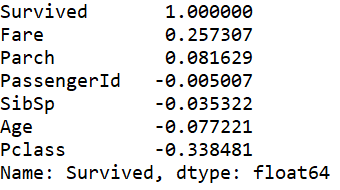
从协方差矩阵中我们可以看出船票号‘PassengerId’,堂兄妹'SibSp',家族'Parch'与生还的相关性接近0,所以可以不用考虑了。。。
#cabin只有204个乘客有值,由于缺失值过大,先看看这个值的有无,对于survival的分布状况的影响 fig = plt.figure() fig.set(alpha=0.2) # 设定图表颜色alpha参数 Survived_cabin = data_train.Survived[pd.notnull(data_train.Cabin)].value_counts() Survived_nocabin = data_train.Survived[pd.isnull(data_train.Cabin)].value_counts() df=pd.DataFrame({u'有':Survived_cabin, u'无':Survived_nocabin}).transpose() df.plot(kind='bar', stacked=True) plt.title(u"按Cabin有无看获救情况") plt.xlabel(u"Cabin有无") plt.ylabel(u"人数") plt.show()
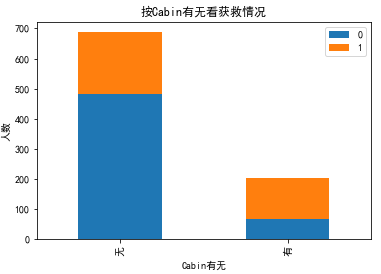
有Cabin记录的似乎获救概率稍高一些。。。
数据预处理
用随机森林填补缺失值
from sklearn.ensemble import RandomForestRegressor ### 使用 RandomForestClassifier 填补缺失的年龄属性 def set_missing_ages(df): # 把已有的数值型特征取出来丢进Random Forest Regressor中 age_df = df[['Age','Fare', 'Parch', 'SibSp', 'Pclass']] # 乘客分成已知年龄和未知年龄两部分 known_age = age_df[age_df.Age.notnull()].as_matrix() unknown_age = age_df[age_df.Age.isnull()].as_matrix() # y即目标年龄 y = known_age[:, 0] # X即特征属性值 X = known_age[:, 1:] # fit到RandomForestRegressor之中 rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1) rfr.fit(X, y) # 用得到的模型进行未知年龄结果预测 predictedAges = rfr.predict(unknown_age[:, 1::]) # 用得到的预测结果填补原缺失数据 df.loc[ (df.Age.isnull()), 'Age' ] = predictedAges return df, rfr def set_Cabin_type(df): df.loc[ (df.Cabin.notnull()), 'Cabin' ] = "Yes" df.loc[ (df.Cabin.isnull()), 'Cabin' ] = "No" return df data_train, rfr = set_missing_ages(data_train) data_train = set_Cabin_type(data_train)
特征工程:
#one-hot编码 # 因为逻辑回归建模时,需要输入的特征都是数值型特征,而男女不是数值型特征 # 以Cabin为例,原本一个属性维度,因为其取值可以是['yes','no'],而将其平展开为'Cabin_yes','Cabin_no'两个属性 # 原本Cabin取值为yes的,在此处的'Cabin_yes'下取值为1,在'Cabin_no'下取值为0 # 原本Cabin取值为no的,在此处的'Cabin_yes'下取值为0,在'Cabin_no'下取值为1 # 我们使用pandas的get_dummies来完成这个工作,并拼接在原来的data_train之上,如下所示 dummies_Cabin = pd.get_dummies(data_train['Cabin'], prefix= 'Cabin') dummies_Embarked = pd.get_dummies(data_train['Embarked'], prefix= 'Embarked') dummies_Sex = pd.get_dummies(data_train['Sex'], prefix= 'Sex') dummies_Pclass = pd.get_dummies(data_train['Pclass'], prefix= 'Pclass') df = pd.concat([data_train, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1) df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True) df
建模:
# 我们把需要的feature字段取出来,转成numpy格式,使用scikit-learn中的LogisticRegression建模 from sklearn import linear_model # y即Survival结果 y = df['Survived'] # X即特征属性值 X = df.loc[:, 'Age':] # fit到RandomForestRegressor之中 clf = linear_model.LogisticRegression(tol=1e-6) clf.fit(X, y) clf

对测试集进行同样的数据预处理:
n=open("C:/Users/文字/Desktop/Kaggle_Titanic/test.csv")
data_test = pd.read_csv(n)
data_test.loc[ (data_test.Fare.isnull()), 'Fare' ] = 0
# 接着我们对test_data做和train_data中一致的特征变换
# 首先用同样的RandomForestRegressor模型填上丢失的年龄
tmp_df = data_test[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
null_age = tmp_df[data_test.Age.isnull()].as_matrix()
# 根据特征属性X预测年龄并补上
X = null_age[:, 1:]
predictedAges = rfr.predict(X)
data_test.loc[ (data_test.Age.isnull()), 'Age' ] = predictedAges
data_test = set_Cabin_type(data_test)
dummies_Cabin = pd.get_dummies(data_test['Cabin'], prefix= 'Cabin')
dummies_Embarked = pd.get_dummies(data_test['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(data_test['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(data_test['Pclass'], prefix= 'Pclass')
df_test = pd.concat([data_test, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df_test.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
df_test
用模型进行结果预测
predictions = clf.predict(test) ''' 生成的预测值是浮点数(0.0,1,0) 但是Kaggle要求提交的结果是整型(0,1) 所以要对数据类型进行转换 ''' result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)}) result.to_csv("C:/Users/。。。。/Desktop/logistic_regression_predictions.csv", index=False)
保存结果为CSV格式,提交到kaggle中
pd.read_csv("logistic_regression_predictions.csv")