什么是机器学习?
广义概念:
机器学习是让计算机具有学习的能力,无需明确的编程 —— 亚瑟·萨缪尔,1959
工程概念:
计算机程序利用经验 E 学习任务 T,性能是 P,如果针对任务 T 的性能 P 随着经验 E 不断增长,则称为机器学习。 —— 汤姆·米切尔,1997
机器学习系统的类型
机器学习有多种类型,可以根据以下规则进行分类:
- 是否在人类监督下进行训练(监督、非监督、半监督和强化学习)
- 是否可以动态渐进学习(在线学习和批量学习)
- 它们是否只是简单的通过比较新的数据点和已知的数据点,还是在训练数据中进行模式识别,以建立一个预测模型,就像科学家所做的那样(基于实力学习和基于模型学习)
监督/非监督学习
机器学习可以根据训练时监督的量和类型进行分类。主要有四类:监督、非监督、半监督和强化学习
监督学习
在监督学习中,用来训练算法的训练数据包含了答案,称为标签。

图 1 用于监督学习(比如垃圾邮件分类)的加了标签的训练集
一个典型的监督学习就是分类,垃圾邮件过滤器就是一个很好的例子:用很多带有归类(垃圾邮件和普通邮件)的邮件样本进行训练,过滤器还能用新邮件进行分类。
另一个典型数值是预测目标数值,例如给出一些特征(里程数、车程、品牌等等)称为预测值,来预测一辆汽车的价格。这类任务称为回归,要训练在这个系统,你需要给出大量汽车样本,包括它们的预测值和标签(即它们的价格)
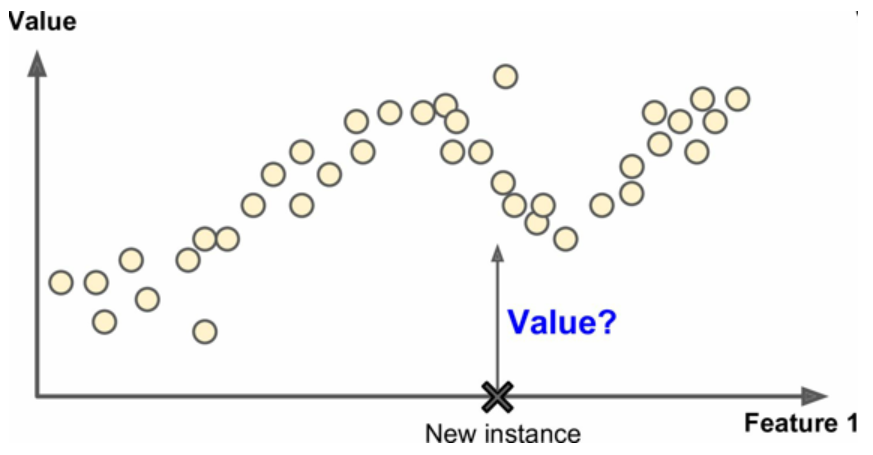
图2 回归
注意:一些回归算法也可以用来进行分类,例如,逻辑回归常用来进行分类,它可以生成一个归属某一类的可能性的值。
下面是一些重要的监督性学习算法:
- K近邻算法
- 线性回归
- 逻辑回归
- 支持向量机(SVM)
- 决策树和随机森林
- 神经网络
非监督学习
训练数据没有加标签。
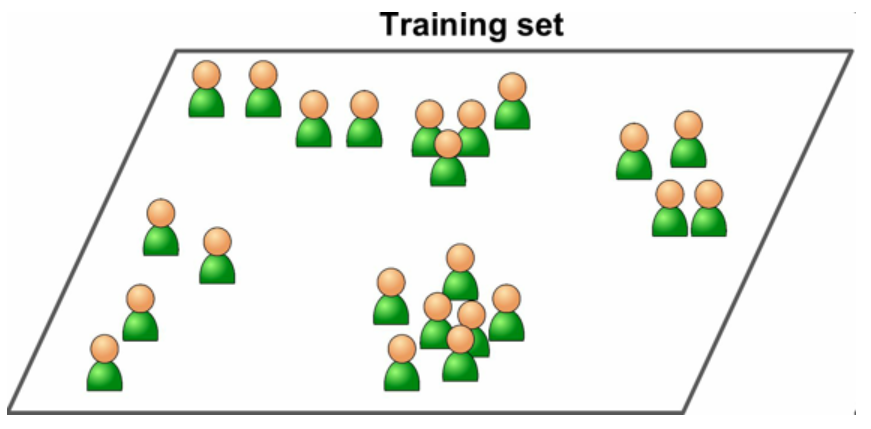
图 3 非监督学习的一个不加标签的训练集
下面是一些最重要的非监督学习算法:
- 聚类 (K均值、层次聚类分析、期望最大值)
- 可视化和降维度 (主成分分析、核主成分分析、局部线性嵌入、t-分布邻域嵌入算法)
- 关联性规则学习(Apriori算法、Eclat算法)
例如,假设你有一份关于你的博客访客的大量数据。你想运行一个聚类算法,检测相似访客的分组(图 1-8)。你不会告诉算法某个访客属于哪一类:它会自己找出关系,无需帮助。例如,算法可能注意到 40% 的访客是喜欢漫画书的男性,通常是晚上访问,20% 是科幻爱好者,他们是在周末访问等等。如果你使用层次聚类分析,它可能还会细分每个分组为更小的组。这可以帮助你为每个分组定位博文。
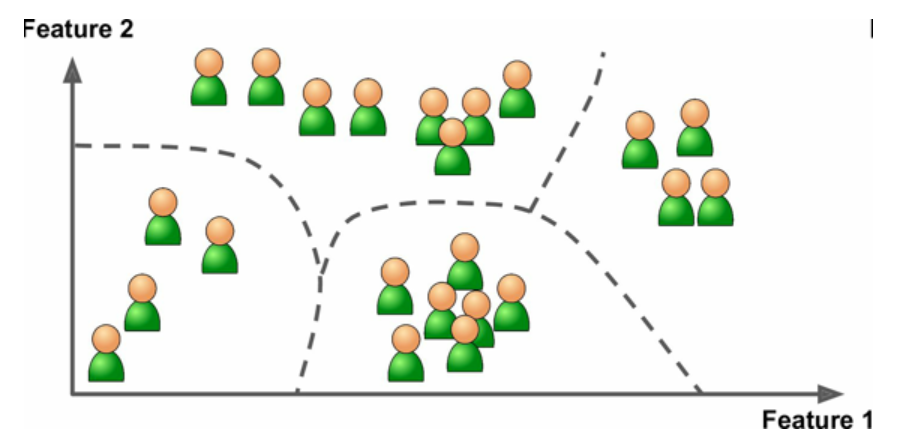
图4 聚类
可视化算法也是极佳的非监督学习案例:给算法大量复杂的且不加标签的数据,算法输出数据的2D或3D图像(图 1-9)。算法会试图保留数据的结构(即尝试保留输入的独立聚类,避免在图像中重叠),这样就可以明白数据是如何组织起来的,也许还能发现隐藏的规律。

图 5 t-SNE 可视化案例,突出了聚类(注:注意动物是与汽车分开的,马和鹿很近、与鸟距离远,以此类推)
与此有关联的任务是降维,降维的目的是简化数据、但是不能失去大部分信息。做法之一是合并若干相关的特征。例如,汽车的里程数和车龄高度相关,降维算法就会将他们合并为汽车的磨损,叫做特征提取。
注意:在用训练集训练机器学习算法(比如监督学习算法)时,最好对训练集进行降维。这样可以运行的更快,占用的硬盘和内存空间更少,有些情况下性能也更好。
另一个非常重要的非监督任务时异常检测(anomaly detection) —— 例如,检测异常的信用卡转账以防欺诈,检测制造缺陷,或者在训练之前自动从训练集中去除异常值,异常监测的系统是用正常值训练的,当它碰到一个新实例,可以判断这个新实例是正常值还是异常值。

图6 异常检测
最后,另一个很重要的非监督学习是关联规则学习,他的目标是挖掘大量数据以发现属性间有趣的关系。
例如,假设你拥有一个超市。在销售日志上运行关联规则,可能发现买了烧烤酱和薯片的人也会买牛排。因此,你可以将这些商品放在一起。
半监督学习
一些算法可以处理部分带标签的训练数据,通常是大量不带标签数据加上少量带标签数据,这种称为半监督学习。
一些图片存储服务,比如 Google Photos,是半监督学习的好例子。一旦你上传了所有家庭相片,它就能自动识别到人物 A 出现在了相片 1、5、11 中,另一个人 B 出现在了相片 2、5、7 中。这是算法的非监督部分(聚类)。现在系统需要的就是你告诉它这两个人是谁。只要给每个人一个标签,算法就可以命名每张照片中的每个人,特别适合搜索照片。
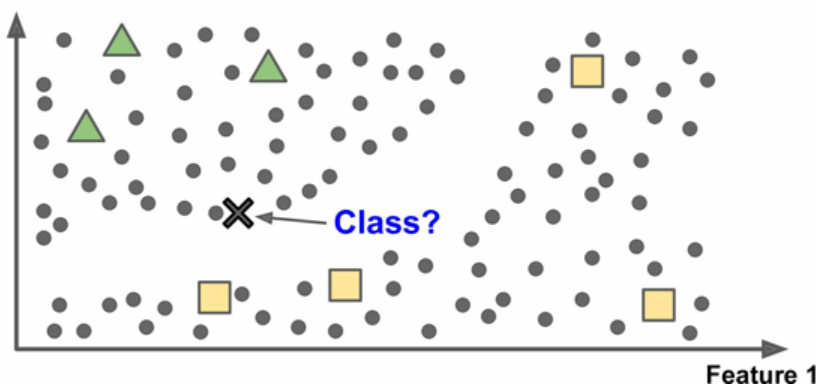
图7 半监督学习
多数半监督学习算法是半监督学习和监督学习的结合。例如,深度信念网络(deep belief networks)是基于被称为互相叠加的受限玻尔兹曼机(restricted Boltzmann machines,RBM)的非监督组件。RBM 是先用非监督方法进行训练,再用监督学习方法对整个系统进行微调。
强化学习
强化学习非常不同。学习系统在这里称为智能体,可以对环境进行观察、选择和执行动作(负奖励是惩罚),然后它必须自己学习哪个是最佳方法(称为策略),已获得长久的最大奖励。策略决定了智能体在给定情况下应采取的行动。
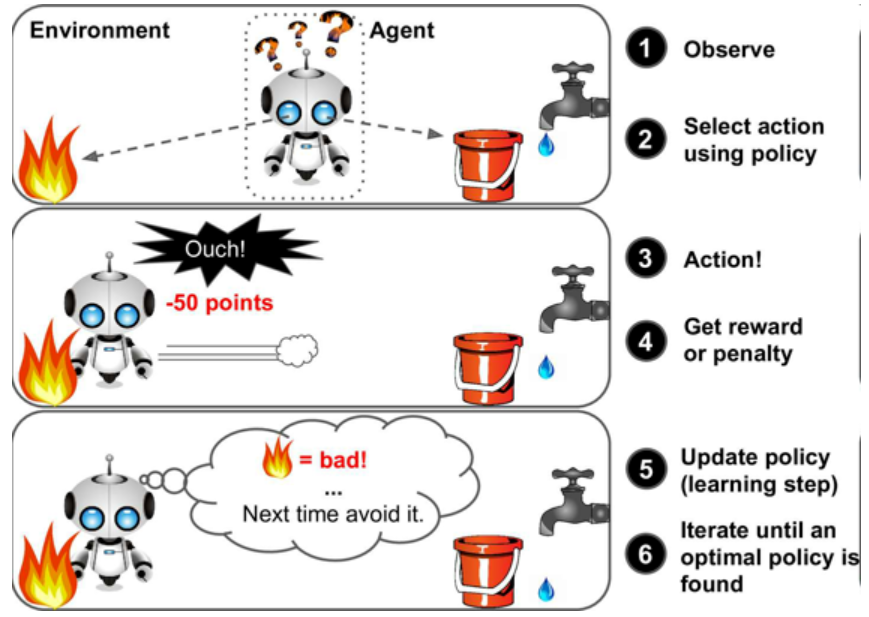
图8 强化学习
例如,许多机器人运行强化学习算法以学习如何行走。DeepMind 的 AlphaGo 也是强化学习的例子:它在 2016 年三月击败了世界围棋冠军李世石(译者注:2017 年五月,AlphaGo 又击败了世界排名第一的柯洁)。它是通过分析数百万盘棋局学习制胜策略,然后自己和自己下棋。要注意,在比赛中机器学习是关闭的;AlphaGo 只是使用它学会的策略。
批量和在线学习
另一个用来分类机器学习的准则是,它是否能从导入的数据流进行持续学习。
批量学习
在批量学习中,系统不能进行持续学习:必须用所有可用数据进行训练。这通常会占用大量时间和计算资源,所以一般是线下做的。首先是进行训练,然后部署在生产环境且停止学习,它只是使用已经学到的策略。这称为离线学习。
如果你想让一个批量学习系统明白新数据(例如垃圾邮件的新类型),就需要从头训练一个系统的新版本,使用全部数据集(不仅有新数据也有老数据),然后停掉老系统,换上新系统。
幸运的是,训练、评估、部署一套机器学习的系统的整个过程可以自动进行,所以即便是批量学习也可以适应改变。只要有需要,就可以方便地更新数据、训练一个新版本。
这个方法很简单,通常可以满足需求,但是用全部数据集进行训练会花费大量时间,所以一般是每 24 小时或每周训练一个新系统。如果系统需要快速适应变化的数据(比如,预测股价变化),就需要一个响应更及时的方案。
另外,用全部数据训练需要大量计算资源(CPU、内存空间、磁盘空间、磁盘 I/O、网络 I/O 等等)。如果你有大量数据,并让系统每天自动从头开始训练,就会开销很大。如果数据量巨大,甚至无法使用批量学习算法。
最后,如果你的系统需要自动学习,但是资源有限(比如,一台智能手机或火星车),携带大量训练数据、每天花费数小时的大量资源进行训练是不实际的。
幸运的是,对于上面这些情况,还有一个更佳的方案可以进行持续学习。
在线学习
在在线学习中,用数据实例可以持续进行训练 ,可以一次一个或一次几个实例(称为小批量)。每个学习步骤都很快且廉价,系统可以动态学习收到的新数据。
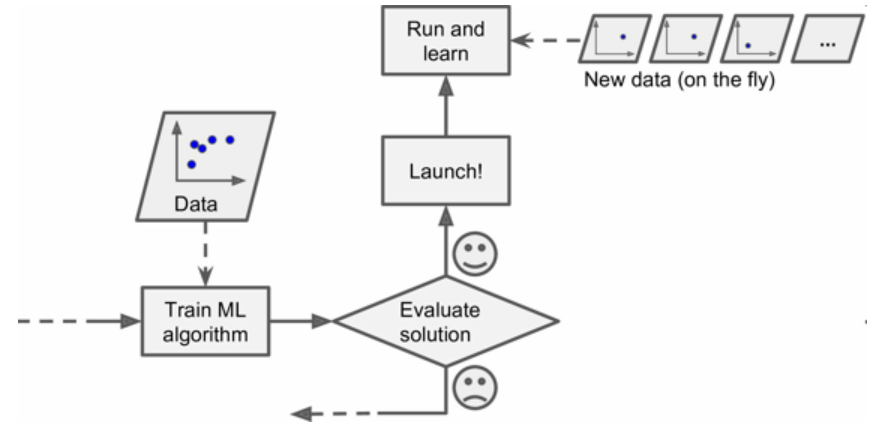
图9 在线学习
在线学习很适合系统接收连续流的数据(比如股票价格),且需要自动对改变做出调整,如果计算资源有限,在线学习是一个不错的方案:一旦在线学习系统学习了新的数据实例,它就不再需要这些数据了,所以扔掉这些数据(除非你想滚回到之前的一个状态,再次使用数据)。这样可以节省大量的空间。
在线学习算法也适合于超大数据集(一台计算机不足以存储它)上训练系统(这称作核外学习,out-of-core learning)。算法每次只加载部分数据,用这些数据进行训练,然后重复这个过程,直到使用完所有的数据。
警告:这个整个过程通常是离线完成的(即,不在部署的系统上),所以在线学习这个名字会让人疑惑。可以把它想成持续学习。
在线学习系统的一个重要参数是,它们可以多快地适应数据的改变:这被称为学习速率。如果你设定一个高学习速率,系统就可以快速适应新数据,但是也会快速忘记老数据(你可不想让垃圾邮件过滤器只标记最新的垃圾邮件种类)。相反的,如果你设定的学习速率低,系统的惰性就会强:即,它学的更慢,但对新数据中的噪声或没有代表性的数据点结果不那么敏感。
在线学习的挑战之一是,如果坏数据被用来进行训练,系统的性能就会逐渐下滑。如果这是一个部署的系统,用户就会注意到。例如,坏数据可能来自失灵的传感器或机器人,或某人向搜索引擎传入垃圾信息以提高搜索排名。要减小这种风险,你需要密集监测,如果检测到性能下降,要快速关闭(或是滚回到一个之前的状态)。你可能还要监测输入数据,对反常数据做出反应(比如,使用异常检测算法)。
基于实例VS基于模型学习
另一种分类机器学习是判断它们如何进行推广的,大多数机器学习是关于预测的。这意味着给定一定数量的训练样本,系统能够推广到没有见过的样本。对训练数据集有很好的预测还不够,真正的目标是对新实例预测的性能。有两种归纳方法:基于实例和基于模型学习。
基于实例学习
也许最简单的学习形式就是用记忆学习。如果用这种方法做一个垃圾邮件过滤器。只需要标记所有和用户标记的垃圾邮件相同的邮件----这个方法不差,但肯定不是最好的。
不仅能标记和已知的垃圾邮件相同的邮件,你的垃圾邮件过滤器也要能标记类似垃圾邮件的邮件。这就需要测量两封邮件的相似性。一个(简单的)相似度测量方法是统计两封邮件包含的相同单词的数量。如果一封邮件含有许多垃圾邮件中的词,就会被标记为垃圾邮件。
这被称作基于实例学习:系统先用记忆学习案例,然后使用相似度测量推广到新的例子

图10 基于实例学习
基于模型学习
另一种从样本集进行归纳的方法,是建立这些样本的模型,然后使用这个模型进行预测。这称作基于模型学习。
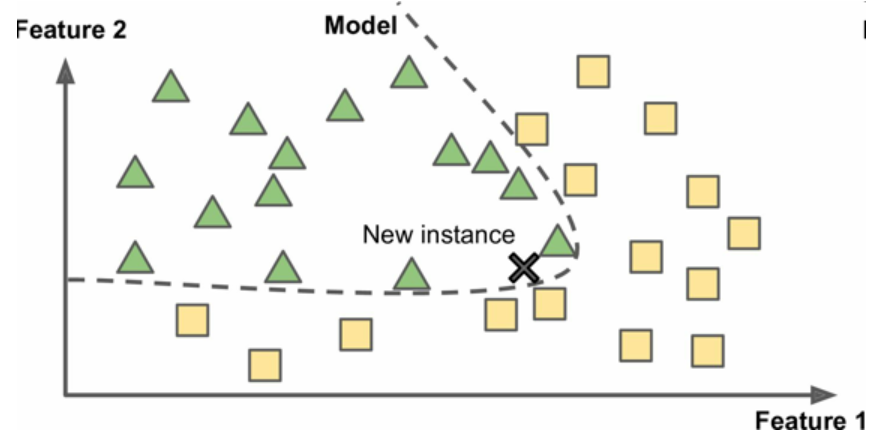
图11 基于模型学习
例如,你想知道钱是否能让人快乐,你从 OECD 网站下载了 Better Life Index 指数数据,还从 IMF 下载了人均 GDP 数据。表 1-1 展示了摘要。

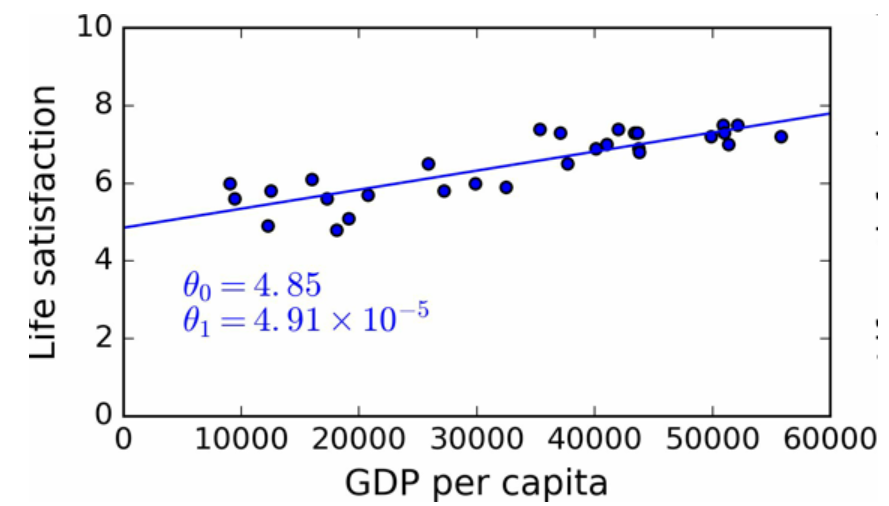
图12 最佳拟合训练数据的线性模型
最后,可以准备运行模型进行预测了。例如,假如你想知道塞浦路斯人有多幸福,但 OECD 没有它的数据。幸运的是,你可以用模型进行预测:查询塞浦路斯的人均 GDP,为 22587 美元,然后应用模型得到生活满意度,后者的值在4.85 + 22,587 × 4.91 × 10-5 = 5.96左右。
案例 1-1 展示了加载数据、准备、创建散点图的 Python 代码,然后训练线性模型并进行预测。
案例 1-1,使用 Scikit-Learn 训练并运行线性模型。
import matplotlib import matplotlib.pyplot as plt import numpy as np import pandas as pd import sklearn # 加载数据 oecd_bli = pd.read_csv("oecd_bli_2015.csv", thousands=',') gdp_per_capita = pd.read_csv("gdp_per_capita.csv",thousands=',',delimiter=' ', encoding='latin1', na_values="n/a") # 准备数据 country_stats = prepare_country_stats(oecd_bli, gdp_per_capita) X = np.c_[country_stats["GDP per capita"]] y = np.c_[country_stats["Life satisfaction"]] # 可视化数据 country_stats.plot(kind='scatter', x="GDP per capita", y='Life satisfaction') plt.show() # 选择线性模型 lin_reg_model = sklearn.linear_model.LinearRegression() # 训练模型 lin_reg_model.fit(X, y) # 对塞浦路斯进行预测 X_new = [[22587]] # 塞浦路斯的人均GDP print(lin_reg_model.predict(X_new)) # outputs [[ 5.96242338]]