1、继承的概念
继承是一种新建类的方式,新建类可以创建一个或多个父类,父类又可以称之为基类或超类,新建的类称之为子类或派生类,继承描述的是一种遗传关系,子类可以重用父类的属性和方法。使用继承可以减少类与类之间代码冗余的问题。
在 Python 中类的继承分为单继承和多继承
class ParentClass1(): # 定义父类
pass
class ParentClass2(): # 定义父类
pass
class SubClass1(ParentClass1): # 定义子类继承父类, 单继承
pass
class SubClass2(ParentClass1, ParentClass2): # Python支持多继承, 用逗号分隔开多个继承的类
pass
2、查看所有继承的父类:__bases__


class ParentClass1():
pass
class ParentClass2():
pass
class SubClass1(ParentClass1):
pass
class SubClass2(ParentClass1, ParentClass2):
pass
print(SubClass1.__bases__)
print(SubClass2.__bases__)
print(ParentClass1.__bases__)
print(ParentClass2.__bases__)
# 运行结果
(<class '__main__.ParentClass1'>,)
(<class '__main__.ParentClass1'>, <class '__main__.ParentClass2'>)
(<class 'object'>,)
(<class 'object'>,)
如果没有指定父类,Python3 会默认继承 object 类,object 是所有类的父类
新式类:但凡继承 object 类的子类,以及该子类的子子类....,都称之为新式类
经典类:没有继承 object 类的子类,以及该子类的子子类....,都称之为经典类
只有在 Python2 中才区分新式类和经典类,Python3 全部默认是新式类
3、继承与抽象(先抽象后继承)
抽象:抽取相似的部分(也就是提取一类事物的特点,范围越来越大,共性越来越少),是从大范围到小范围的过程
继承:是基于抽象的过程,通过编程语言去实现它,肯定是先经历抽象这个过程,才能通过继承的方式去表达出抽象的结构,是从小范围到大范围的过程
4、派生
1)在父类的基础上产生子类,产生的子类就叫做派生类
2)父类中没有的方法,在子类中有,这样的方法就叫做派生方法
3)父类中有个方法,子类中也有这个方法,就叫做方法的重写(就是把父类里的方法重写了)
5、注意的几个概念
1)子类可以使用父类的所有属性和方法
2)如果子类有自己的方法,就执行自己的;如果子类没有自己的方法,就会找父类的
3)如果子类里面没有找到,父类里也没有找到,就会报错
6、在子类派生出新的功能中如何重用父类的功能
现在我定义一个学生类,隶属于学校 “湫兮如风” ,学生有姓名,年龄,性别,还可以选课;再创建教师类,也隶属于学校 “湫兮如风” ,教师有姓名,年龄,性别,等级,工资,教师可以给学生打分
class Student():
school = '湫兮如风学院'
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
def choose_course(self):
print('%s正在选课' %self.name)
class Teacher():
school = '湫兮如风学院'
def __init__(self, name, age, gender, level, salary):
self.name = name
self.age = age
self.gender = gender
self.level = level
self.salary = salary
def score(self, stu, num):
print('教师%s给学生%s打%s分' %(self.name, stu.name, num))
stu.num = num
但是这样写有很多重复的代码,分析一下条件,教师和学生都属于学院的人,于是可以定义出一个父类让教师和学生去继承这个父类
class People():
school = '湫兮如风学院'
class Student(People):
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
def choose_course(self):
print('%s正在选课' %self.name)
class Teacher(People):
def __init__(self, name, age, gender, level, salary):
self.name = name
self.age = age
self.gender = gender
self.level = level
self.salary = salary
def score(self, stu, num):
print('教师%s给学生%s打%s分' %(self.name, stu.name, num))
stu.num = num
这样的处理还不够彻底,因为还有 __init__ 里面还有部分重复的代码,可以将这些重复的代码放入父类,但是教师类中还有等级和工资无法处理,这两个对于父类来说就是多出来的,会报错
class People():
school = '湫兮如风学院'
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
class Student(People):
def choose_course(self):
print('%s正在选课' %self.name)
class Teacher(People):
def score(self, stu, num):
print('教师%s给学生%s打%s分' %(self.name, stu.name, num))
stu.num = num
stu = Student('qiu', 22, 'male')
tea = Teacher('xi', 20, 'male', 10, 3000)
# 运行
TypeError: __init__() takes 4 positional arguments but 6 were given
可以在教师类中派生新的 __init__ ,将教师的姓名,年龄,性别,等级,工资写入,但这又回到了上一步,又有了重复的代码,这就引入了需要解决的问题:在子类派生出新的功能中如何重用父类的功能?
在函数中我们介绍了调用的概念,在父类中有这个功能,在子类中不想再写,就可以调用这个功能
class People():
school = '湫兮如风学院'
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
class Student(People):
def choose_course(self):
print('%s正在选课' %self.name)
class Teacher(People):
def __init__(self, name, age, gender, level, salary):
# 注意: 这里不能使用self去调用__init__, 这样调用的永远是自己的__init__,
# 因为这里的self是Teacher的一个对象, 就是tea, tea先从自己去找__init__, 没有找到
# 再到Teacher中找__init__, 找到了, 于是永远在调用自己的__init__, 无法访问到父类的__init__
# 于是用类名去调, 这实际上就是一个普通函数, 没有自动传值的功能, 需要将参数一个不少的传入
People.__init__(self, name, age, gender)
self.level = level
self.salary = salary
def score(self, stu, num):
print('教师%s给学生%s打%s分' %(self.name, stu.name, num))
stu.num = num
stu = Student('qiu', 22, 'male')
tea = Teacher('xi', 20, 'male', 10, 3000)
这是第一种方式,指名道姓的访问某一个类中的函数,这实际上与面向对象无关,即便是 Teacher 和 Person 没有继承关系,也能够调用
在讲第二种方式之前,需要先了解在继承背景下,经典类与新式类的属性查找顺序
首先是单继承,在单继承背景下,无论是新式类还是经典类属性查找顺序都一样,都是先从对象中查找,对象中没有到类中,类中没有再到父类中。
而在多继承背景下,如果一个子类继承多个父类,但这些父类没有再继承同一个非 object 的父类,在这种情况下,新式类还是经典类属性查找顺序也是一样的,先在对象中查找,对象中没有再到对象所在的类中,再没有就会按照从左到右的顺序一个父类一个父类的找下去
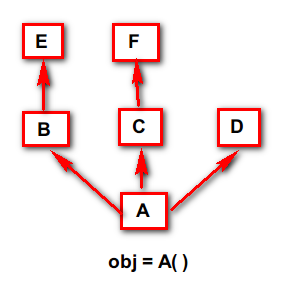
所以这里的查找顺序是:obj ---> A ---> B ---> E ---> C ---> F ---> D,D中没有再到 object 中查找,在这里 object 不在讨论范围之内,比如要查找 name 属性,object类 中不可能会去定义一个 name 属性。下面是代码实现
class E():
x = 'E'
pass
class F():
X = 'F'
pass
class B(E):
# x = 'B'
pass
class C(F):
x = 'C'
pass
class D():
x = 'D'
pass
class A(B, C, D):
# x = 'A'
pass
obj = A()
print(obj.x)
还有一种情况,被称之为 “菱形继承” ,可以抽象的想像到,最终的父类是汇聚到一点,继承了同一个父类,并且这个父类也不是 object 类。在这种情况下,新式类和经典类的属性查找顺序不同。
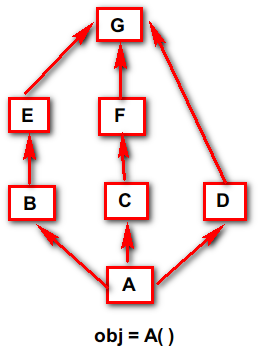
在新式类中,是按照广度优先查找,即:obj ---> A ---> B ---> E ---> C ---> F ---> D ---> G
在经典类中,是按照深度优先查找,即:obj ---> A ---> B ---> E ---> G ---> C ---> F ---> D
对于定义的每一个类,Python 会计算出一个方法解析顺序(MRO)列表,这个 MRO 列表就是用于保存继承顺序的一个列表
class G():
x = 'G'
pass
class E(G):
x = 'E'
pass
class F(G):
X = 'F'
pass
class B(E):
x = 'B'
pass
class C(F):
x = 'C'
pass
class D(G):
x = 'D'
pass
class A(B, C, D):
x = 'A'
pass
obj = A()
# print(obj.x)
print(A.mro())
# 运行结果
[<class '__main__.A'>, <class '__main__.B'>, <class '__main__.E'>, <class '__main__.C'>, <class '__main__.F'>, <class '__main__.D'>, <class '__main__.G'>, <class 'object'>]
为了实现继承,Python 会在 MRO 列表上从左到右开始查找父类,直到找到第一个匹配这个属性的类为止,而这个 MRO 列表的构造是通过一个 C3 线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的 MRO 列表并遵循如下三条准则:
1)子类会先于父类被检查
2)如果有多个父类,则根据继承语法在列表内的书写顺序被检查
3)如果多个类继承了同一个父类,则子类中只会选取继承语法括号中的第一个父类
了解了以上知识点,现在继续来说在子类派生出的新功能中如何重用父类功能的方式二
有一个叫做 super 的内置函数,调用该函数会得到一个特殊的对象,该对象是专门用来访问父类中属性和方法
class People():
school = '湫兮如风学院'
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
class Student(People):
def choose_course(self):
print('%s正在选课' %self.name)
class Teacher(People):
def __init__(self, name, age, gender, level, salary):
super(Teacher, self).__init__(name, age, gender)
self.level = level
self.salary = salary
def score(self, stu, num):
print('教师%s给学生%s打%s分' %(self.name, stu.name, num))
stu.num = num
stu = Student('qiu', 22, 'male')
tea = Teacher('xi', 20, 'male', 10, 3000)
强调:super 会严格参照类的 MRO 列表依次查找属性
这是子类在类里面调用父类方法,使用 super(子类类名,self).方法名() 或 super().__init__(参数),在 Python3 中 super 可以不传参数,Python2 中必须要传参数