问题导读:
1、Scheduler任务中Distributed Plan、Scan Range是什么?
2、Scheduler基本接口有哪些?
3、QuerySchedule这个类如何理解?
4、SimpleScheduler接口如何实现的?![]()
Scheduler的任务
1、相关概念:Distributed Plan
在Frontend中已经把SQL转换成了single node plan,然后又将其切分成了distributed plan。代码见Planner::createPlan和DistributedPlanner::createPlanFragments.
比如左图的single node plan会切成为右图的distributed plan(图片来源自impala官方PPT:Query Compilation in Impala)。在impala-shell中set explain_level=3后用explain可以看到distributed plan。
<ignore_js_op>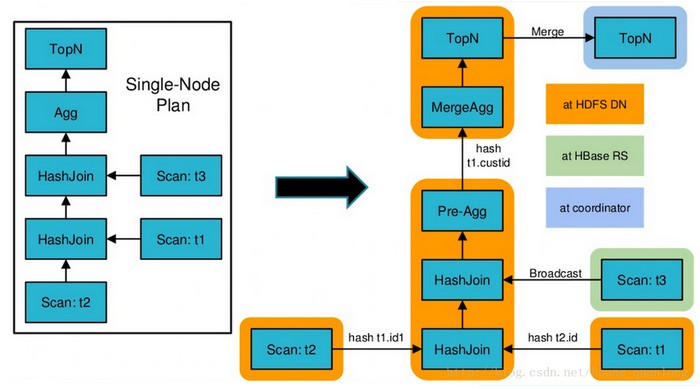
上图的Distributed Plan中,一个带颜色的圈是一个Plan Fragment。Plan Fragment间的箭头是Fragment间的数据流动,Plan Fragment内矩形间的箭头是Fragment内各个Plan Node的数据流动。上图其实省略了Distributed Plan中每个非叶子结点里的ExchangeNode,其是用来接收其它Plan Fragment的数据的。一个Plan Fragment会有一个或多个instance,运行在不同impalad上。
2、相关概念:Scan Range
在distributed plan中,每个scan node已经设置好要处理的scan ranges,即有哪些输入文件要处理,每个有哪些block。从Frontend传来的scan range对应一个block,由于一个block有多个replica,因此一个scan range会有多个location。了解scan range的概念非常重要,下面是相关的thrift定义:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
|
// PlanNodes.thriftstruct TScanRange { // one of these must be set for every TScanRange 1: optional THdfsFileSplit hdfs_file_split 2: optional THBaseKeyRange hbase_key_range}struct THdfsFileSplit { // File name (not the full path). The path is assumed to be the // 'location' of the THdfsPartition referenced by partition_id. 1: required string file_name 2: required i64 offset 3: required i64 length // ID of partition within the THdfsTable associated with this scan node 4: required i64 partition_id 5: required i64 file_length 6: required CatalogObjects.THdfsCompression file_compression 7: required i64 mtime // last modified time}struct THBaseKeyRange { 1: optional string startKey // inclusive 2: optional string stopKey // exclusive} |
一个ScanRange要么是HDFS文件上的一部分(用file_name,offset和length等来表示),要么是Hbase一片连续的rowKey(用[startKey, endKey)表示)。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
// Planer.thriftstruct TScanRangeLocation { // 对应HDFS上一个block位置,定位到硬盘编号 // Index into TQueryExecRequest.host_list. 1: required i32 host_idx; 2: optional i32 volume_id = -1 3: optional bool is_cached = false // If true, this block is cached on this server}struct TScanRangeLocations { // 一个ScanRange对应的各个replica的位置列表 1: required PlanNodes.TScanRange scan_range // non-empty list 2: list<TScanRangeLocation> locations} |
TScanRangeLocations就记录了Scan Range的位置列表,这个类型在TQueryExecRequest中会被用到。TQueryExecRequest的成员per_node_scan_ranges记录了每个ScanNode要处理的一系列ScanRange,每个ScanRange用TScanRangeLocations来表示。因此per_node_scan_ranges的类型是 map<Types.TPlanNodeId, list<Planner.TScanRangeLocations>>.
TQueryExecRequest是Frontend传给Backend的执行计划,Backend会生成 fragment 的执行计划发送给其它 impalad 去执行,这其中就包含了Scheduler的工作。impalad之间通信的数据结构定义在ImpalaInternalService.thrift中,关于ScanRange使用的是TScanRangeParams,此时已经确定了Scan任务要放在哪台机器上去执行(就是接收信息的impalad),因此不再需要location信息里的host_idx。
|
1
2
3
4
5
6
7
8
|
// ImpalaInternalService.thrift// A scan range plus the parameters needed to execute that scan.struct TScanRangeParams { 1: required PlanNodes.TScanRange scan_range 2: optional i32 volume_id = -1 3: optional bool is_cached = false 4: optional bool is_remote} |
3、Scheduler的任务
我们知道HDFS是有多备份的,一个block经常会有多于一个复本,因此在HDFS上的位置也会有多于一个。那么读取的时候到底在哪个复本上执行,这就是Scheduler要做的事情。另外其它的上层plan fragment也需要确定在哪些机器上执行。
代码注释如是说:
|
1
|
Given a list of resources and locations returns a list of hosts on which to execute plan fragments requiring those resources. |
这其实很像MapReduce里对mapper和reducer的调度。
Scheduler基本接口
|
1
|
virtual Status Init() = 0; |
该接口初始化本Scheduler,返回时表示已获取了做调试决策所需要的所有资源。
定义BackendList类型表示一列Backend描述符。
|
1
|
typedef std::vector<TBackendDescriptor> BackendList; |
|
1
|
virtual Status GetBackends(const std::vector<TNetworkAddress>& data_locations, BackendList* backends) = 0; |
该接口输入是一组 host/port 二元组表示的data location,输出是一组运行在那些机器上或附近(比如同机架)的Backend列表。
|
1
|
virtual Status GetBackend(const TNetworkAddress& data_location, TBackendDescriptor* backend) = 0; |
该接口输入是一个 host/port 二元组表示的 data location,输出是一个运行在该机器上或附近的Backend。
|
1
|
virtual bool HasLocalBackend(const TNetworkAddress& data_location) = 0; |
返回是否有Backend运行在资源所在的机器上。
|
1
|
virtual void GetAllKnownBackends(BackendList* backends) = 0; |
返回该scheduler知道的所有Backend
|
1
|
virtual Status Schedule(Coordinator* coord, QuerySchedule* schedule) = 0; |
该接口最主要的输入是QueryScheduler::request(),即一个TQueryExecRequest对象,描述了query的执行计划。参数里的Coordinator只提供一些全局的信息,比如user name等。TQueryExecRequest的per_node_scan_ranges记录了要处理的scan ranges。该接口将这些scan range分配到对应的机器上去,分配信息(即调度信息)记录在QuerySchedule的fragment_exec_params_中。
如果开启了资源管理,即impala运行在Yarn上时,该接口也会向resource manager(通过Llama)申请资源来执行query。该接口在资源申请被同意或拒绝前是阻塞的。
|
1
|
virtual Status Release(QuerySchedule* schedule) = 0; |
释放资源
下面的几个接口主要是Impala on Yarn要用到的回调函数,字面意思比较直观
|
1
2
3
|
virtual void HandlePreemptedReservation(const TUniqueId& reservation_id) = 0;virtual void HandlePreemptedResource(const TUniqueId& client_resource_id) = 0;virtual void HandleLostResource(const TUniqueId& client_resource_id) = 0; |
QuerySchedule
在读懂SimpleScheduler的代码前需要先过一下QuerySchedule这个类,SimpleScheduler的任务是把QueryScheduler对象补充完整。
一个QueryScheduler包含了coordinator生成fragment执行请求从而启动query执行所需要的所有信息。Coordinator根据QueryScheduler生成FragmentExecParams,发送给各个impalad去执行fragment instance。
如果开启了资源管理(即Impala on Yarn),则QueryScheduler中还会包含需要申请的资源和已经获得的资源。
query-schedule.h中首先定义了两个类型:
|
1
2
|
typedef std::map<TPlanNodeId, std::vector<TScanRangeParams> > PerNodeScanRanges;typedef boost::unordered_map<TNetworkAddress, PerNodeScanRanges> FragmentScanRangeAssignment; |
PerNodeScanRanges是ScanNode到ScanRange列表的映射,FragmentScanRangeAssignment是impalad到PerNodeScanRanges的映射。
每个Scan Node可能有多个scan range,分配到不同impalad上去执行。因此这里有个impalad到其任务的映射,即它要处理哪些scan node的哪些scan range。
QuerySchedule有几个重要的成员变量:
<ignore_js_op>
其中plan_node_to_fragment_idx_和plan_node_to_plan_node_idx_是在进入SimpleScheduler::Schedule前就生成好的了。Schedule函数最主要的任务是填充fragment_exec_params_和unique_hosts等成员变量。fragment_exec_params是一个FragmentExecParams数组,记录了每个fragment的执行请求,用来发送给其它impalad去运行fragment instance。FragmentExecParams的定义如下:
|
1
2
3
4
5
6
7
8
|
struct FragmentExecParams { std::vector<TNetworkAddress> hosts; // 将在哪些backend上执行,每个backend执行一个instance std::vector<TUniqueId> instance_ids; // 各个instance的id std::vector<TPlanFragmentDestination> destinations; // 所有输出目标,TPlanFragmentDestination是目标fragment的各个instance id及其所运行在的server std::map<PlanNodeId, int> per_exch_num_senders; // 本fragment里各个exchange node的输入instance总数 FragmentScanRangeAssignment scan_range_assignment; // scan range的调度信息,比如hdfs上replica的选择信息 int sender_id_base; // 本fragment作为一个sender时的base id}; |
这里的sender_id_base需要再解释一下。除了根fragment以外的每个fragment都有另一个fragment作为输出目标,除了叶子fragment外的所有fragment都有若干输入fragment。因此除了根fragment以外的每个fragment都需要扮演sender的角色,除了叶子fragment外的所有fragment也都要扮演receiver的角色。每一个fragment都有一个或多个instance,receiver会为自己的各个sender (instance)分配id用来区分,id从0开始。为了方便,我们给同一个fragment的不同instance分配连续的id,这样只需要记住起始id和该fragment的instance数目就够了。成员变量sender_id_base记录的就是自己作为sender时,由receiver分配的起始id。
SimpleScheduler接口实现
目前Impala on Yarn还不是很流行,我们可以先跳过跟resource management相关的代码,这样看起来会更容易些。最主要的逻辑还是Schedule接口:
|
1
|
Status SimpleScheduler::Schedule(Coordinator* coord, QuerySchedule* schedule) |
主要做三件事情:
- ComputeScanRangeAssignment(schedule->request(), schedule));
填充各个FragmentExecParams对象中的scan_range_assignment
- ComputeFragmentHosts(schedule->request(), schedule);
填充各个FragmentExecParams对象中的hosts,即计算每个fragment instance在哪个impalad上执行
- ComputeFragmentExecParams(schedule->request(), schedule);
填充各个FragmentExecParams对象中剩下的内容,即destinations、per_exch_num_senders和sender_id_base
调用完这三个函数后,QuerySchedule的fragment_exec_params_就被填充完整了。下面分别介绍这三部分。
ComputeScanRangeAssignment
|
1
|
Status SimpleScheduler::ComputeScanRangeAssignment(const TQueryExecRequest& exec_request, QuerySchedule* schedule) |
正如函数名所述,该函数主要处理scan range的分配,即每个scan range的data host的选择。这里主要是hdfs上的scan range需要处理,因为每个block有多个replica,有多个DataNode可供选择,而hbase上的region只归一个RegionServer(即这里的data host)管理。
exec_request.per_node_scan_ranges是一个map,记录了每个scan node对应的所有scan ranges。该函数的主体是一个for循环,每次处理一个scan node。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
for (entry = exec_request.per_node_scan_ranges.begin(); entry != exec_request.per_node_scan_ranges.end(); ++entry) { const TPlanNodeId node_id = entry->first; // 获取该scan node在整个执行计划树中的id int fragment_idx = schedule->GetFragmentIdx(node_id); // 获取该scan node所在的fragment的下标。 const TPlanFragment& fragment = exec_request.fragments[fragment_idx]; // 获取该scan node所在的fragment引用 bool exec_at_coord = (fragment.partition.type == TPartitionType::UNPARTITIONED); // 该scan node是否在Coordinator处执行 // 获取该scan node的引用。schedule->GetNodeIdx返回的是node在其fragment的执行计划树中的下标。 const TPlanNode& node = fragment.plan.nodes[schedule->GetNodeIdx(node_id)]; DCHECK_EQ(node.node_id, node_id); // 下面的TReplicaPreference类型是复本选择时的默认策略,是个枚举类型,总共有5种: // CACHE_LOCAL, CACHE_RACK, DISK_LOCAL, DISK_RACK, REMOTE const TReplicaPreference::type* node_replica_preference = node.__isset.hdfs_scan_node && node.hdfs_scan_node.__isset.replica_preference ? &node.hdfs_scan_node.replica_preference : NULL; // 如果scan node里有设置,就拿这个默认配置,否则记为NULL // random_replica表示当有几个复本各方面条件都一样时,是否随机选择。否则直接选第一个复本。 bool node_random_replica = node.__isset.hdfs_scan_node && node.hdfs_scan_node.__isset.random_replica && node.hdfs_scan_node.random_replica; // FragmentScanRangeAssignment类型记录一个fragment里所有scan range的分配,即选择哪些复本。实际是一个map: // typedef boost::unordered_map<TNetworkAddress, PerNodeScanRanges> FragmentScanRangeAssignment; // 上面的TNetworkAddress是impalad的地址(用host+port表示),PerNodeScanRanges也是一个map,记录每个scan node的所有scan range: // typedef std::map<TPlanNodeId, std::vector<TScanRangeParams> > PerNodeScanRanges; // 下面这行获取该fragment的assignment引用,所有fragment执行信息(即FragmentExecParams)在schedule->exec_params()数组中 FragmentScanRangeAssignment* assignment = &(*schedule->exec_params())[fragment_idx].scan_range_assignment; // 根据以上获取的对象进行实质的分配,并把结果写入assignment对象中 RETURN_IF_ERROR(ComputeScanRangeAssignment( node_id, node_replica_preference, node_random_replica, entry->second, exec_request.host_list, exec_at_coord, schedule->query_options(), assignment)); schedule->AddScanRanges(entry->second.size()); // 更新schedule对象中的scan range计数} |
ComputeScanRangeAssignment
|
1
2
3
4
5
|
Status SimpleScheduler::ComputeScanRangeAssignment( PlanNodeId node_id, const TReplicaPreference::type* node_replica_preference, bool node_random_replica, const vector<TScanRangeLocations>& locations, const vector<TNetworkAddress>& host_list, bool exec_at_coord, const TQueryOptions& query_options, FragmentScanRangeAssignment* assignment) |
逐个过下参数:
- node_id:要处理的scan node的id
- node_replica_preference:replica的默认选择策略,是个枚举类例,取值可以是CACHE_LOCAL、DISK_LOCAL等,没有的话就是NULL
- node_random_replica:对于条件相同的replica,是否随机选择。否的话就直接选第一个。
- locations:各个scan range(也即block)的location列表(replica列表)
- host_list:复本所在的host列表,即DataNode列表
- exec_at_coord:该scan node是否在Coordinator处运行
- query_options:各种查询参数,详见TQueryOption定义
- assignment:调度结果存储在该对象中
函数的主体是两层的for循环,第一层为每个scan range,第二层为该scan range的各个location,也即replica。
代码中比较难懂的局部变量是base_distance,所谓的distance不过是CACHE_LOCAL, CACHE_RACK, DISK_LOCAL, DISK_RACK, REMOTE中的一种,表示impalad和它要读取的数据的距离。base_distance是一个基准线,就是说距离比这个还小(优)的我们就当成一样的来对待了。
另一个局部变量random_non_cached_tiebreak意义与参数node_random_replica相同,就是条件都一样的replica中是随机挑一个还是直接选第一个。
除去profile和打log的代码,函数主体的伪代码如下:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
assigned_bytes_per_host是一个map,记录各个DataNode被分配的数据量,即有多少数据要从该DataNode读取foreach ScanRange in ScanNode //min_distance 记录replica到impalad的最小距离,初始值为REMOTE // min_assigned_bytes,该变量帮助我们找到被分配任务最少的DataNode。每个replica从属于一个DataNode,如果有几个replica的distance相等,则比较它们所在DataNode所要读取的数据量。 // 这几个局部变量记录最终的选择结果:data_host、volume_id、is_cached、remote_read //num_equivalent_replicas记录各方面条件都相同的replica数目 foreach Location in ScanRange // replica_host 是replica所在的DataNode //计算memory_distance,如果优于base_distance则折合成base_distance //assigned_bytes 是replica所在DataNode当前被分配的数据量 //bool变量found_new_replica表示是否选择该replica if (memory_distance < min_distance) { min_distance = memory_distance; num_equivalent_replicas = 1; found_new_replica = true; } else if (memory_distance == min_distance) { bool cached_replica = memory_distance == TReplicaPreference::CACHE_LOCAL; if (assigned_bytes < min_assigned_bytes) { num_equivalent_replicas = 1; found_new_replica = true; } else if (assigned_bytes == min_assigned_bytes && (random_non_cached_tiebreak || cached_replica)) { // 如果之前已经有k个相等的replica,则以1/(k+1)的概率决定是否采用本replica. // 这样前面的replica被选中的概率各是 1/k * k/(k+1) = 1/(k+1),从而实现随机挑选 ++num_equivalent_replicas; const int r = rand(); // make debugging easier. found_new_replica = (r % num_equivalent_replicas == 0); } } if (found_new_replica) { // 如果采用当前replica,则更新一系列值 min_assigned_bytes = assigned_bytes; data_host = &replica_host; volume_id = location.volume_id; is_cached = location.is_cached; remote_read = min_distance == TReplicaPreference::REMOTE; } } // end of each location (replica) 更新remote_bytes、remote_hosts、local_bytes、cached_bytes、assigned_bytes_per_host 为data_host找一个backend host(即exec_hostport),如果该DataNode所在机器上就有impalad,则选择该impalad, 否则以round robin(轮循)的方式在impalad列表中挑一个。另外,如果函数参数中exec_at_coord为true, 则该scan node只在Coordinator所在impalad上执行,也就是当前机器。 ///////////// 把结果存入assignment中 ///////////// PerNodeScanRanges* scan_ranges = FindOrInsert(assignment, exec_hostport, PerNodeScanRanges()); vector<TScanRangeParams>* scan_range_params_list = FindOrInsert(scan_ranges, node_id, vector<TScanRangeParams>()); // add scan range TScanRangeParams scan_range_params; scan_range_params.scan_range = scan_range_locations.scan_range; // Explicitly set the optional fields. scan_range_params.__set_volume_id(volume_id); scan_range_params.__set_is_cached(is_cached); scan_range_params.__set_is_remote(remote_read); scan_range_params_list->push_back(scan_range_params);} // end of each scan range |
回顾一下,assignment是一个映射,记录每个impalad的scan任务,存在一个PerNodeScanRanges对象中。每个PerNodeScanRanges对象也是一个映射,记录一个scan node在该impalad要读的数据,用vector表示。每个TScanRangeParams表示一个读任务,如果is_remote为false,则在所在impalad机器上的DataNode处读取,此时is_cached表示数据是否已缓存在该impalad中,volume_id记录了数据在哪块磁盘。如果is_remote为true,则根据PlanNodes.TScanRange去获取数据源来读取,使用hdfs或hbase的api。
ComputeFragmentHosts
|
1
2
|
void SimpleScheduler::ComputeFragmentHosts(const TQueryExecRequest& exec_request, QuerySchedule* schedule) { |
上一个Compute函数进行了replica的选取,接下来要给出每个fragment instance在哪个impalad上去执行。
这个函数的输出是schedule->exec_params()中各个FragmentExecParams的hosts部分,最后还会更新下schedule里的unique_hosts_,即整个query涉及到的其它impalad(除去本机)
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
vector<FragmentExecParams>* fragment_exec_params = schedule->exec_params(); // 拿出要修改的对象列表 TNetworkAddress coord = MakeNetworkAddress(FLAGS_hostname, FLAGS_be_port); // Coordinator地址即是本进程地址 DCHECK_EQ(fragment_exec_params->size(), exec_request.fragments.size()); vector<TPlanNodeType::type> scan_node_types; // 目前的scan node总共有三种类型 scan_node_types.push_back(TPlanNodeType::HDFS_SCAN_NODE); scan_node_types.push_back(TPlanNodeType::HBASE_SCAN_NODE); scan_node_types.push_back(TPlanNodeType::DATA_SOURCE_NODE); // 从后往前处理各个fragment,因为前面的fragment依赖于后面的输出,可能会调度到后面fragment同样的hosts上去, // 因此底层的fragment要先处理。 for (int i = exec_request.fragments.size() - 1; i >= 0; --i) { const TPlanFragment& fragment = exec_request.fragments[i]; [/i]FragmentExecParams& params = (*fragment_exec_params); if (fragment.partition.type == TPartitionType::UNPARTITIONED) { // all single-node fragments run on the coordinator host params.hosts.push_back(coord); continue; } // UnionNode会通过ExchangeNode接收其它fragment的输入,也会接收所在fragment的scan结果。 // 包含UnionNode的fragment不仅会被调度到scan range选择的replica所在机器上,也会被调度到所有输入fragment的instance所在的机器上。 // (使得以partitioned join或grouping aggregate为子结点的UnionNode所运行的机器数目,不小于其子结点的输入数目) if (ContainsNode(fragment.plan, TPlanNodeType::UNION_NODE)) { vector<TPlanNodeId> scan_nodes; FindNodes(fragment.plan, scan_node_types, &scan_nodes); // 取出该fragment的所有scan node vector<TPlanNodeId> exch_nodes; FindNodes(fragment.plan, vector<TPlanNodeType::type>(1, TPlanNodeType::EXCHANGE_NODE), &exch_nodes); // 取出该fragment的所有exchange node // 把scan nodes所选择的host加入进来 vector<TNetworkAddress> scan_hosts; for (int j = 0; j < scan_nodes.size(); ++j) { GetScanHosts(scan_nodes[j], exec_request, params, &scan_hosts); } unordered_set<TNetworkAddress> hosts(scan_hosts.begin(), scan_hosts.end()); // 把input fragments所选择的host加入进来 for (int j = 0; j < exch_nodes.size(); ++j) { // 处理每个exchange node int input_fragment_idx = FindSenderFragment(exch_nodes[j], i, exec_request); // 找到该exchange node的输入fragment // 获取该输入fragment的所有hosts,所有输入的fragment应该在处理本fragment之前就已经计算好hosts了 const vector<TNetworkAddress>& input_fragment_hosts = (*fragment_exec_params)[input_fragment_idx].hosts; hosts.insert(input_fragment_hosts.begin(), input_fragment_hosts.end()); } DCHECK(!hosts.empty()) << "no hosts for fragment " << i << " with a UnionNode"; params.hosts.assign(hosts.begin(), hosts.end()); continue; } // 查看最左结点是否是scan node. 注意传入的types是scan_node_types PlanNodeId leftmost_scan_id = FindLeftmostNode(fragment.plan, scan_node_types); if (leftmost_scan_id == g_ImpalaInternalService_constants.INVALID_PLAN_NODE_ID) { // 如果最左节点不是scan node,那只能是exchange node。我们把本fragment调度到其对应的输入fragment所在的所有机器上。 // 从而像分布式aggregation这类的fragment可以在本机获得输入fragment的数据 int input_fragment_idx = FindLeftmostInputFragment(i, exec_request); params.hosts = (*fragment_exec_params)[input_fragment_idx].hosts; continue; } // 找到了最左的scan node,本fragment将在其scan ranges选定的各个replica机器上去执行 GetScanHosts(leftmost_scan_id, exec_request, params, ¶ms.hosts); } // 最后再填一下schedule对象中的unique_hosts,即把所有用到的hosts集合的并集 unordered_set<TNetworkAddress> unique_hosts; BOOST_FOREACH(const FragmentExecParams& exec_params, *fragment_exec_params) { unique_hosts.insert(exec_params.hosts.begin(), exec_params.hosts.end()); } schedule->SetUniqueHosts(unique_hosts);} |
ComputeFragmentExecParams
|
1
2
|
void SimpleScheduler::ComputeFragmentExecParams(const TQueryExecRequest& exec_request, QuerySchedule* schedule) |
这是SimpleSchedule::Schedule里调用的最后一个Compute函数,用来把各个FragmentExecParams剩下的内容填补完。
函数主体有两部分:先为各个fragment instance分配id,都有了id之后就可以指明各个instance的输入输出,把它们串成一个有向无环图。
这段代码不难了,有以下两点需要解释:
- 根fragment没有输出,其它的每个fragment都会输出到另一个fragment中的exchange node去,因此需要把目标fragment的各个instance id记录下来,也就是记录本fragment要有几个sender来发送数据,各发到哪些instance去。另外,每个exchange node也要知道有多少个instance会给自己发数据,即sender数目。
- 每个instance的id是一个128位整数(由两个64位整数表示,类型为TUniqueId),其中的高64位与query id的高64位一样,低64位是query id的低64位加上其是第几个instance。
总结
读懂SimpleScheduler的代码对后续阅读Impala更底层的代码很有帮助。在这里可以弄明白很多基本概念,如Plan Fragment Instance、Scan Range、Exchange Node等。
SimpleScheduler的调度策略很直接,把包含Scan Node的Plan Fragment Instance优先调度到数据所在的机器上去运行,同时会考虑均摊对HDFS DataNode的负载。如果数据所在机器上没有impalad,则用round robin的方式选一个远程的impalad。另外上层的Plan Fragment会尽量在其依赖的Plan Fragment所在机器上去运行。