在JDK1.6,1.7中,HashMap的实现都是用基础的“拉链法”去实现,即数组+链表的形式。如下图:通过不同的hash值,来对数据进行分配存储。
关于HashMap的Entry长度,可以参考http://wiki.jikexueyuan.com/project/java-collection/hashmap.html
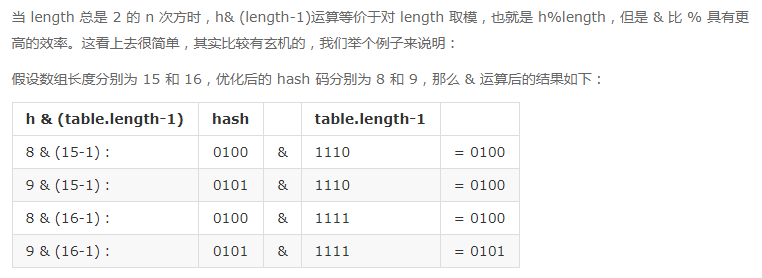
简要来说,要保证初始化时 HashMap 的容量总是 2 的 n 次方,即底层数组的长度总是为 2 的 n 次方。
那么 HashMap 什么时候进行扩容呢?当 HashMap 中的元素个数超过数组大小 *loadFactor时,就会进行数组扩容,loadFactor的默认值为 0.75,这是一个折中的取值。也就是说,默认情况下,数组大小为 16,那么当 HashMap 中元素个数超过 16*0.75=12 的时候,就把数组的大小扩展为 2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置。
HashMap 包含如下几个构造器:
- HashMap():构建一个初始容量为 16,负载因子为 0.75 的 HashMap。
- ashMap(int initialCapacity):构建一个初始容量为 initialCapacity,负载因子为 0.75 的 HashMap。
- HashMap(int initialCapacity, float loadFactor):以指定初始容量、指定的负载因子创建一个 HashMap。
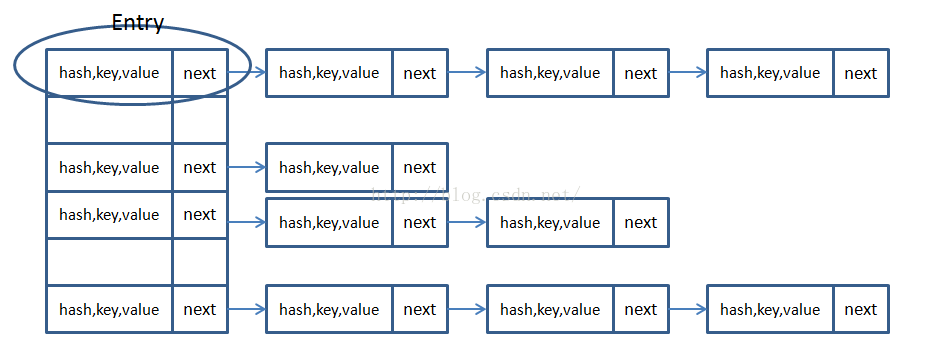
在JDK1.8中对HashMap的源码进行了优化,在jdk7中,HashMap处理“碰撞”的时候,都是采用链表来存储,当碰撞的结点很多时,查询时间是O(n)。
在jdk8中,HashMap处理“碰撞”增加了红黑树这种数据结构,当碰撞结点较少时,采用链表存储,当较大时(>8个),采用红黑树(特点是查询时间是O(logn))存储(有一个阀值控制,大于阀值(8个),将链表存储转换成红黑树存储)

关于红黑树的介绍,可以参考