3 梯度下降:重要参数max_iter

3.1 梯度下降求解逻辑回归



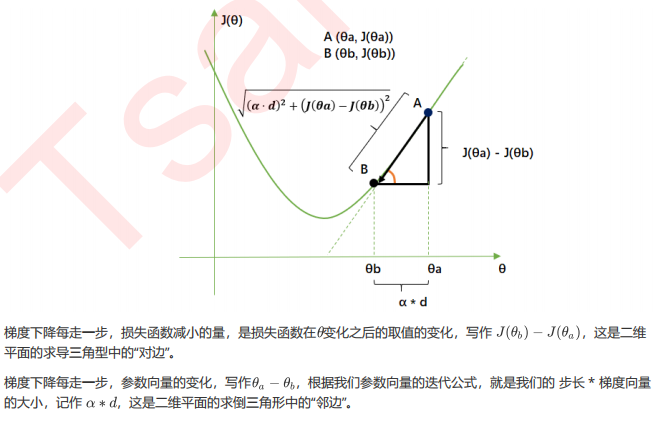
3.2 梯度下降的概念与解惑



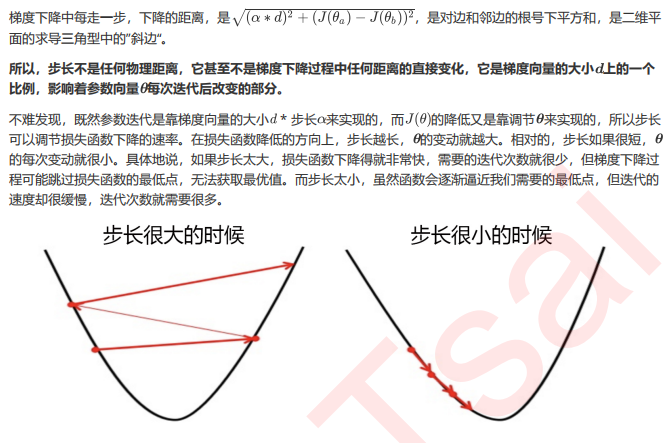
3.3 步长的概念与解惑


l2 = [] l2test = [] Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y,test_size=0.3,random_state=420) for i in np.arange(1,201,10): lrl2 = LR(penalty="l2",solver="liblinear",C=0.9,max_iter=i) lrl2 = lrl2.fit(Xtrain,Ytrain) l2.append(accuracy_score(lrl2.predict(Xtrain),Ytrain)) l2test.append(accuracy_score(lrl2.predict(Xtest),Ytest)) graph = [l2,l2test] color = ["black","gray"] label = ["L2","L2test"] plt.figure(figsize=(20,5)) for i in range(len(graph)): plt.plot(np.arange(1,201,10),graph[i],color[i],label=label[i]) plt.legend(loc=4) plt.xticks(np.arange(1,201,10)) plt.show() #我们可以使用属性.n_iter_来调用本次求解中真正实现的迭代次数 lr = LR(penalty="l2",solver="liblinear",C=0.9,max_iter=300).fit(Xtrain,Ytrain) lr.n_iter_

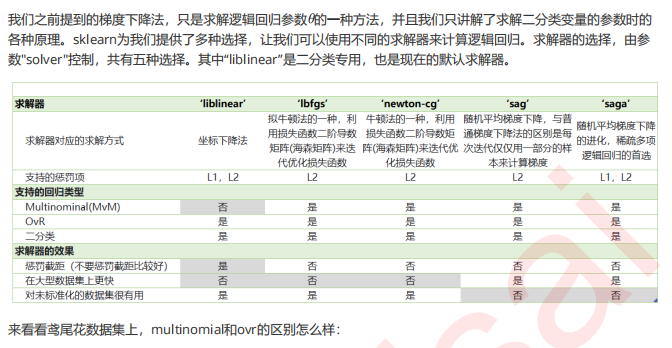
4 二元回归与多元回归:重要参数solver & multi_class

from sklearn.datasets import load_iris iris = load_iris() for multi_class in ('multinomial', 'ovr'): clf = LogisticRegression(solver='sag', max_iter=100, random_state=42, multi_class=multi_class).fit(iris.data, iris.target) #打印两种multi_class模式下的训练分数 #%的用法,用%来代替打印的字符串中,想由变量替换的部分。%.3f表示,保留三位小数的浮点数。%s表示,字符串。 #字符串后的%后使用元祖来容纳变量,字符串中有几个%,元祖中就需要有几个变量 print("training score : %.3f (%s)" % (clf.score(iris.data, iris.target), multi_class))
5 样本不平衡与参数class_weight

