7 Joining key columns on an index
join() takes an optional on argument which may be a column or multiple column names, which specifies that the passed DataFrame is to be aligned on that column in the DataFrame. These two function calls are completely equivalent:
left.join(right, on=key_or_keys) pd.merge( left, right, left_on=key_or_keys, right_index=True, how="left", sort=False )
Obviously you can choose whichever form you find more convenient. For many-to-one joins (where one of the DataFrame’s is already indexed by the join key), using join may be more convenient. Here is a simple example:
In [91]: left = pd.DataFrame( ....: { ....: "A": ["A0", "A1", "A2", "A3"], ....: "B": ["B0", "B1", "B2", "B3"], ....: "key": ["K0", "K1", "K0", "K1"], ....: } ....: ) ....: In [92]: right = pd.DataFrame({"C": ["C0", "C1"], "D": ["D0", "D1"]}, index=["K0", "K1"]) In [93]: result = left.join(right, on="key")
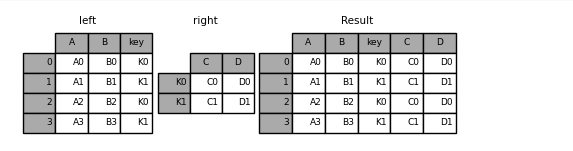
In [94]: result = pd.merge( ....: left, right, left_on="key", right_index=True, how="left", sort=False ....: ) ....:
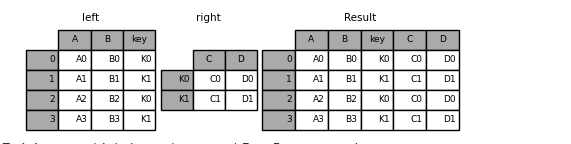
To join on multiple keys, the passed DataFrame must have a MultiIndex:
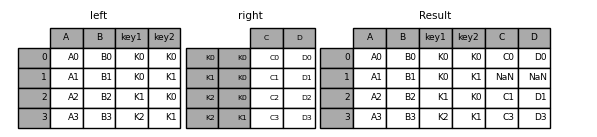
In [95]: left = pd.DataFrame( ....: { ....: "A": ["A0", "A1", "A2", "A3"], ....: "B": ["B0", "B1", "B2", "B3"], ....: "key1": ["K0", "K0", "K1", "K2"], ....: "key2": ["K0", "K1", "K0", "K1"], ....: } ....: ) ....: In [96]: index = pd.MultiIndex.from_tuples( ....: [("K0", "K0"), ("K1", "K0"), ("K2", "K0"), ("K2", "K1")] ....: ) ....: In [97]: right = pd.DataFrame( ....: {"C": ["C0", "C1", "C2", "C3"], "D": ["D0", "D1", "D2", "D3"]}, index=index ....: ) ....:
Now this can be joined by passing the two key column names:
In [98]: result = left.join(right, on=["key1", "key2"])
The default for DataFrame.join is to perform a left join (essentially a “VLOOKUP” operation, for Excel users), which uses only the keys found in the calling DataFrame. Other join types, for example inner join, can be just as easily performed:
In [99]: result = left.join(right, on=["key1", "key2"], how="inner")
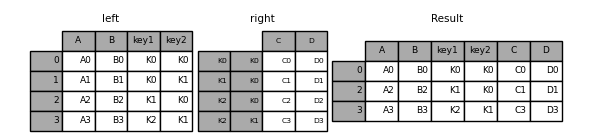
As you can see, this drops any rows where there was no match.
8 Joining a single Index to a MultiIndex
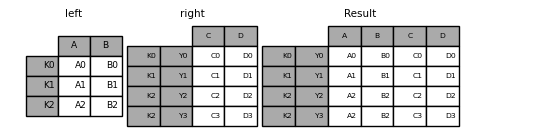
You can join a singly-indexed DataFrame with a level of a MultiIndexed DataFrame. The level will match on the name of the index of the singly-indexed frame against a level name of the MultiIndexed frame.
In [100]: left = pd.DataFrame( .....: {"A": ["A0", "A1", "A2"], "B": ["B0", "B1", "B2"]}, .....: index=pd.Index(["K0", "K1", "K2"], name="key"), .....: ) .....: In [101]: index = pd.MultiIndex.from_tuples( .....: [("K0", "Y0"), ("K1", "Y1"), ("K2", "Y2"), ("K2", "Y3")], .....: names=["key", "Y"], .....: ) .....: In [102]: right = pd.DataFrame( .....: {"C": ["C0", "C1", "C2", "C3"], "D": ["D0", "D1", "D2", "D3"]}, .....: index=index, .....: ) .....: In [103]: result = left.join(right, how="inner")
This is equivalent but less verbose and more memory efficient / faster than this.
In [104]: result = pd.merge( .....: left.reset_index(), right.reset_index(), on=["key"], how="inner" .....: ).set_index(["key","Y"]) .....:
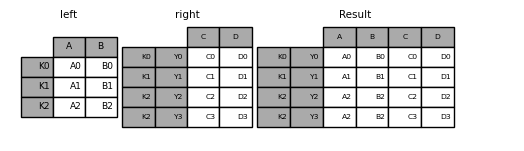
9 Joining with two MultiIndexes
This is supported in a limited way, provided that the index for the right argument is completely used in the join, and is a subset of the indices in the left argument, as in this example:
In [105]: leftindex = pd.MultiIndex.from_product( .....: [list("abc"), list("xy"), [1, 2]], names=["abc", "xy", "num"] .....: ) .....: In [106]: left = pd.DataFrame({"v1": range(12)}, index=leftindex) In [107]: left Out[107]: v1 abc xy num a x 1 0 2 1 y 1 2 2 3 b x 1 4 2 5 y 1 6 2 7 c x 1 8 2 9 y 1 10 2 11 In [108]: rightindex = pd.MultiIndex.from_product( .....: [list("abc"), list("xy")], names=["abc", "xy"] .....: ) .....: In [109]: right = pd.DataFrame({"v2": [100 * i for i in range(1, 7)]}, index=rightindex) In [110]: right Out[110]: v2 abc xy a x 100 y 200 b x 300 y 400 c x 500 y 600 In [111]: left.join(right, on=["abc", "xy"], how="inner") Out[111]: v1 v2 abc xy num a x 1 0 100 2 1 100 y 1 2 200 2 3 200 b x 1 4 300 2 5 300 y 1 6 400 2 7 400 c x 1 8 500 2 9 500 y 1 10 600 2 11 600
If that condition is not satisfied, a join with two multi-indexes can be done using the following code.
In [112]: leftindex = pd.MultiIndex.from_tuples( .....: [("K0", "X0"), ("K0", "X1"), ("K1", "X2")], names=["key", "X"] .....: ) .....: In [113]: left = pd.DataFrame( .....: {"A": ["A0", "A1", "A2"], "B": ["B0", "B1", "B2"]}, index=leftindex .....: ) .....: In [114]: rightindex = pd.MultiIndex.from_tuples( .....: [("K0", "Y0"), ("K1", "Y1"), ("K2", "Y2"), ("K2", "Y3")], names=["key", "Y"] .....: ) .....: In [115]: right = pd.DataFrame( .....: {"C": ["C0", "C1", "C2", "C3"], "D": ["D0", "D1", "D2", "D3"]}, index=rightindex .....: ) .....: In [116]: result = pd.merge( .....: left.reset_index(), right.reset_index(), on=["key"], how="inner" .....: ).set_index(["key", "X", "Y"]) .....:
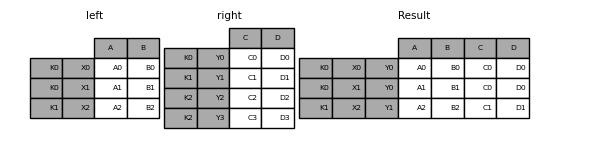
10 Merging on a combination of columns and index levels
Strings passed as the on, left_on, and right_on parameters may refer to either column names or index level names. This enables merging DataFrame instances on a combination of index levels and columns without resetting indexes.
In [117]: left_index = pd.Index(["K0", "K0", "K1", "K2"], name="key1") In [118]: left = pd.DataFrame( .....: { .....: "A": ["A0", "A1", "A2", "A3"], .....: "B": ["B0", "B1", "B2", "B3"], .....: "key2": ["K0", "K1", "K0", "K1"], .....: }, .....: index=left_index, .....: ) .....: In [119]: right_index = pd.Index(["K0", "K1", "K2", "K2"], name="key1") In [120]: right = pd.DataFrame( .....: { .....: "C": ["C0", "C1", "C2", "C3"], .....: "D": ["D0", "D1", "D2", "D3"], .....: "key2": ["K0", "K0", "K0", "K1"], .....: }, .....: index=right_index, .....: ) .....: In [121]: result = left.merge(right, on=["key1", "key2"])

11 Overlapping value columns
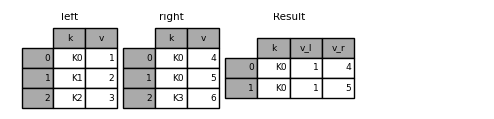
The merge suffixes argument takes a tuple of list of strings to append to overlapping column names in the input DataFrames to disambiguate the result columns:
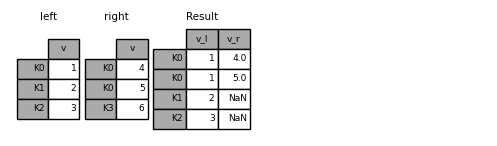
In [122]: left = pd.DataFrame({"k": ["K0", "K1", "K2"], "v": [1, 2, 3]})
In [123]: right = pd.DataFrame({"k": ["K0", "K0", "K3"], "v": [4, 5, 6]})
In [124]: result = pd.merge(left, right, on="k")

In [125]: result = pd.merge(left, right, on="k", suffixes=("_l", "_r"))
DataFrame.join() has lsuffix and rsuffix arguments which behave similarly.
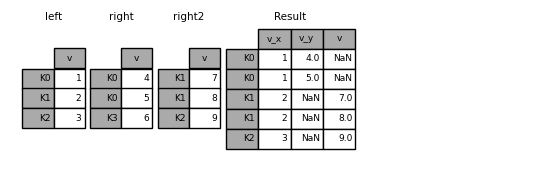
In [126]: left = left.set_index("k") In [127]: right = right.set_index("k") In [128]: result = left.join(right, lsuffix="_l", rsuffix="_r")
12 Joining multiple DataFrames
A list or tuple of DataFrames can also be passed to join() to join them together on their indexes.
In [129]: right2 = pd.DataFrame({"v": [7, 8, 9]}, index=["K1", "K1", "K2"])
In [130]: result = left.join([right, right2])
13 Merging together values within Series or DataFrame columns
Another fairly common situation is to have two like-indexed (or similarly indexed) Series or DataFrame objects and wanting to “patch” values in one object from values for matching indices in the other. Here is an example:
In [131]: df1 = pd.DataFrame( .....: [[np.nan, 3.0, 5.0], [-4.6, np.nan, np.nan], [np.nan, 7.0, np.nan]] .....: ) .....: In [132]: df2 = pd.DataFrame([[-42.6, np.nan, -8.2], [-5.0, 1.6, 4]], index=[1, 2])
For this, use the combine_first() method:
In [133]: result = df1.combine_first(df2)

Note that this method only takes values from the right DataFrame if they are missing in the left DataFrame. A related method, update(), alters non-NA values in place:
In [134]: df1.update(df2)
