0 简介
0.1 主题


0.2 目标

1 XGBoost的原理考虑使用二阶导信息
1.1 XGBoost简介




1.2 GDBT损失函数展开

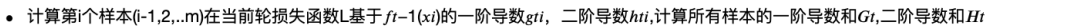
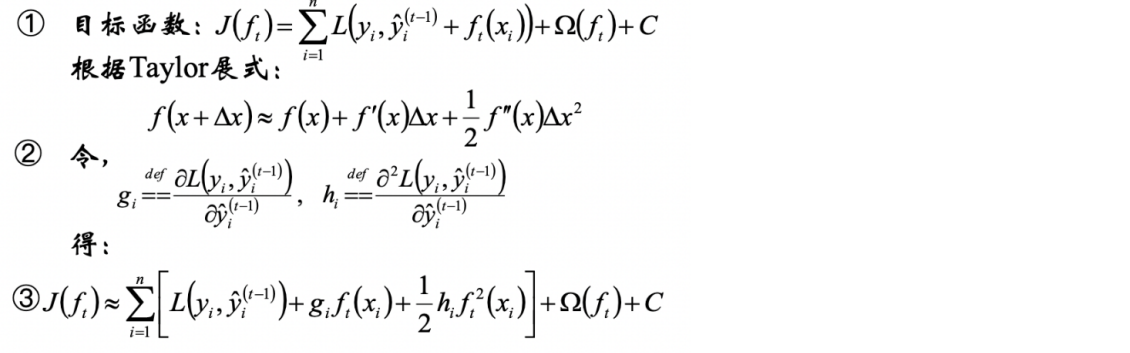
1.3 代码演示
# /usr/bin/python # -*- encoding:utf-8 -*- import xgboost as xgb import numpy as np from sklearn.model_selection import train_test_split # cross_validation def iris_type(s): it = {b'Iris-setosa': 0, b'Iris-versicolor': 1, b'Iris-virginica': 2} return it[s] if __name__ == "__main__": path = './data/iris.data' # 数据文件路径 data = np.loadtxt(path, dtype=float, delimiter=',', converters={4: iris_type}) x, y = np.split(data, (4,), axis=1) x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1, test_size=50) data_train = xgb.DMatrix(x_train, label=y_train) data_test = xgb.DMatrix(x_test, label=y_test) watch_list = [(data_test, 'eval'), (data_train, 'train')] param = {'max_depth': 4, 'eta': 0.1, 'objective': 'multi:softmax', 'num_class': 3} bst = xgb.train(param, data_train, num_boost_round=4, evals=watch_list) y_hat = bst.predict(data_test) result = y_test.reshape(1, -1) == y_hat print('正确率: ', float(np.sum(result)) / len(y_hat)) print('END..... ')
[0] eval-merror:0.02 train-merror:0.02 [1] eval-merror:0.02 train-merror:0.02 [2] eval-merror:0.02 train-merror:0.02 [3] eval-merror:0.02 train-merror:0.02 正确率: 0.98 END.....
2 决策树的描述
2.1 描述


2.2 代码
# /usr/bin/python # -*- encoding:utf-8 -*- import xgboost as xgb import numpy as np from sklearn.model_selection import train_test_split # cross_validation from sklearn.linear_model import LogisticRegression from sklearn.preprocessing import StandardScaler import warnings warnings.filterwarnings("ignore") def show_accuracy(a, b, tip): acc = a.ravel() == b.ravel() print(acc) print("----------------------") print(tip + '正确率: ', float(acc.sum()) / a.size) if __name__ == "__main__": data = np.loadtxt('./data/wine.data', dtype=float, delimiter=',') y, x = np.split(data, (1,), axis=1) x = StandardScaler().fit_transform(x) x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1, test_size=0.5) # Logistic回归 lr = LogisticRegression(penalty='l2') # LR正则 lr.fit(x_train, y_train.ravel()) y_hat = lr.predict(x_test) show_accuracy(y_hat, y_test, 'Logistic回归 ') # XGBoost y_train[y_train == 3] = 0 # 第3个类别标记为0 y_test[y_test == 3] = 0 data_train = xgb.DMatrix(x_train, label=y_train) data_test = xgb.DMatrix(x_test, label=y_test) watch_list = [(data_test, 'eval'), (data_train, 'train')] param = {'max_depth': 3, 'eta': 1, 'objective': 'multi:softmax', 'num_class': 3} bst = xgb.train(param, data_train, num_boost_round=4, evals=watch_list) y_hat = bst.predict(data_test) show_accuracy(y_hat, y_test, 'XGBoost ')
[ True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True False True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True] ---------------------- Logistic回归 正确率: 0.9887640449438202 [0] eval-merror:0.011236 train-merror:0 [1] eval-merror:0 train-merror:0 [2] eval-merror:0.011236 train-merror:0 [3] eval-merror:0.011236 train-merror:0 [ True True True True True True True True True True True True True True True True True True True True True True True False True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True] ---------------------- XGBoost 正确率: 0.9887640449438202
3 正则项的定义


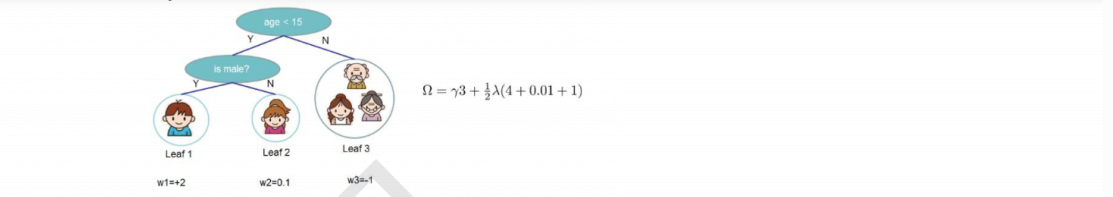
4 目标函数计算
4.1 目标函数计算
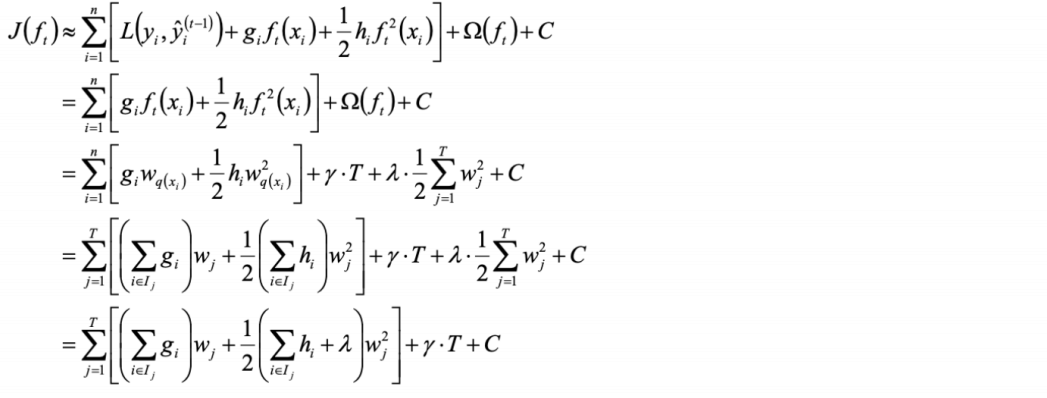
4.2 持续化简
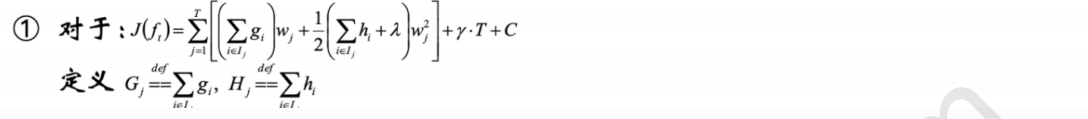
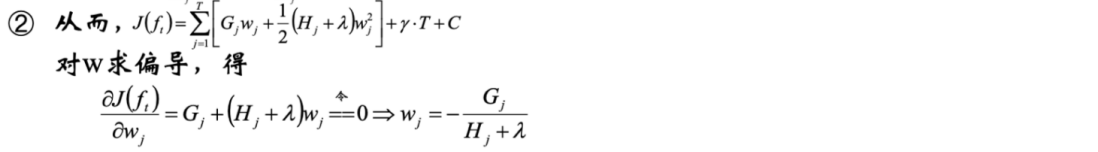




代码实战
# /usr/bin/python # -*- coding:utf-8 -*- import warnings warnings.filterwarnings("ignore") import xgboost as xgb import numpy as np import scipy.sparse from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression def read_data(path): y = [] row = [] col = [] values = [] r = 0 for d in open(path): d = d.strip().split() y.append(int(d[0])) d = d[1:] for c in d: key, value = c.split(':') row.append(r) col.append(int(key)) values.append(float(value)) r += 1 x = scipy.sparse.csr_matrix((values, (row, col))).toarray() y = np.array(y) return x, y def show_accuracy(a, b, tip): acc = a.ravel() == b.ravel() print(acc) print(tip + '正确率: ', float(acc.sum()) / a.size) if __name__ == '__main__': x, y = read_data('./data/agaricus_train.txt') x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1, train_size=0.6) # Logistic回归 lr = LogisticRegression(penalty='l2') lr.fit(x_train, y_train.ravel()) y_hat = lr.predict(x_test) show_accuracy(y_hat, y_test, 'Logistic回归 ') # XGBoost y_train[y_train == 3] = 0 y_test[y_test == 3] = 0 data_train = xgb.DMatrix(x_train, label=y_train) data_test = xgb.DMatrix(x_test, label=y_test) watch_list = [(data_test, 'eval'), (data_train, 'train')] param = {'max_depth': 3, 'eta': 1, 'silent': 0, 'objective': 'multi:softmax', 'num_class': 3} bst = xgb.train(param, data_train, num_boost_round=4, evals=watch_list) y_hat = bst.predict(data_test) show_accuracy(y_hat, y_test, 'XGBoost ')
[ True True True ... True True True] Logistic回归 正确率: 1.0 [0] eval-merror:0.035687 train-merror:0.040696 [1] eval-merror:0.007291 train-merror:0.009982 [2] eval-merror:0.000767 train-merror:0.000512 [3] eval-merror:0.000767 train-merror:0.000512 [ True True True ... True True True] XGBoost 正确率: 0.9992325402916347
5 拓展

6 总结
6.1 为什么xgboost要用泰勒展开,优势在哪里/

6.2 XGBoost和GBDT的区别

7 笔面试相关
7.1 XGBoost如何寻找最优特征?是又放回还是无放回的呢?

7.2 XGBoost为什么快?

7.3 XGBoost如何处理不平衡数据
