1 背景
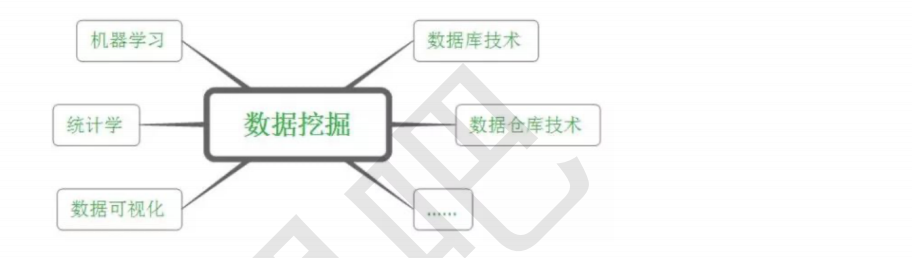
由于数据挖掘理论涉及到的面很广,它实际上起源于多个学科。如建模部分主要起源于统计学和机器学习。
统计学方法以模型为驱动,常常建立一个能够产生数据的模型:而机器学习则以算法为驱动,让计算机通过执行林法来发现知识。
仔细想想,”学习‘本身就有耳法的愈思在里面嘛
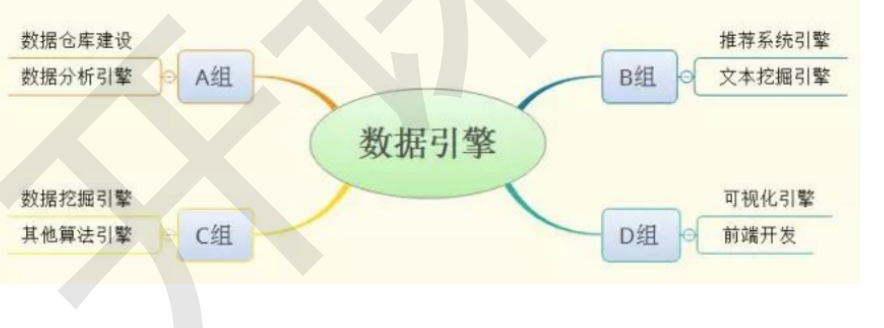
在大型公司数据引擎团队中,主要人员分为A,B,C,D四大组。四组的分工非常明确,如图
目前国内的数据挖掘人员工作领域大致可分为三类
数据分析师:在拥有行业数据的电商、金融、电信、咨询等行业里做业务咨询,商务智能,出分析报告。 ·
数据挖掘工程师:在多媒体、电商、搜索、社交等大数据相关行业里做机器学习算法实现和分析。 ·
科学研究方向:在高校、科研单位、企业研究院等高大上科研机构研究新算法效率改进及未来应用。
2 术语
2.1 什么是(监督式)机器学习?简单来说,它的定义如下: ·
机器学习系统通过学习如何组合输入信息来对从未见过的数据做出有用的预测

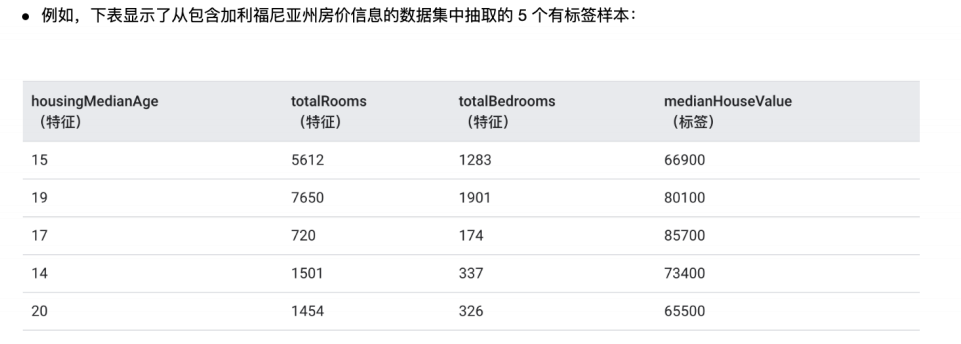
2.2 有标签样本、无标签样本。
样本是指数据的特定实例 X 记录的集合(无监份)样例的集合(有监份)我们将样本分为以下两类:
有标签样本、无标签样本。

2.3 回归模型与分类模型
回归模型可预洲连续值。
例如,回归模型做出的预测可回答如下问题:加利福尼亚州一栋房产的价值是多少?用户点击此广告的概率是多少?.
分类模型可预测离散值。
例如,分类模型做出的预测可回答如下问题:某个指定电子邮件是垃圾邮件还是非垃圾邮件?这是一张狗、猫还是仓鼠图片?
3 机器学习分类
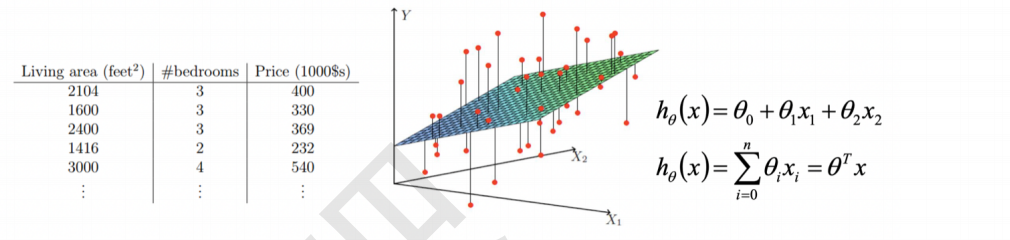
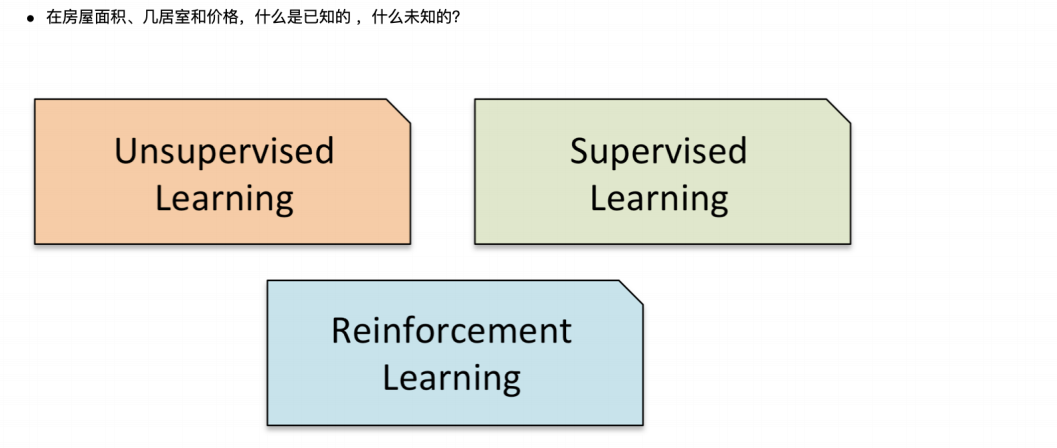
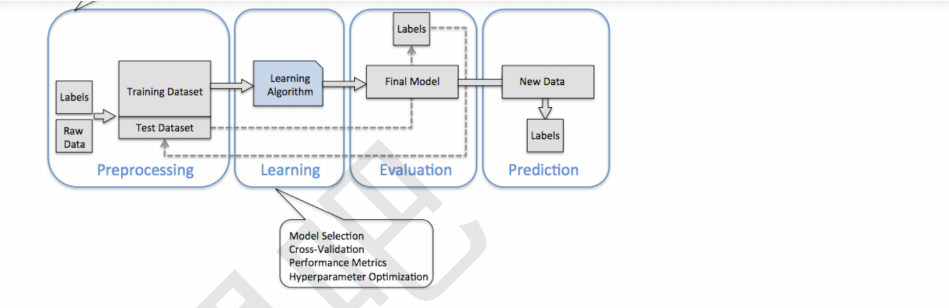
4 监督学习流程
机器学习的所有算法,系统都是学的是参数 theta; 咱们不仅要代码实现出来,在学习算法的时候呀.咱们也要进行“参数估计”;
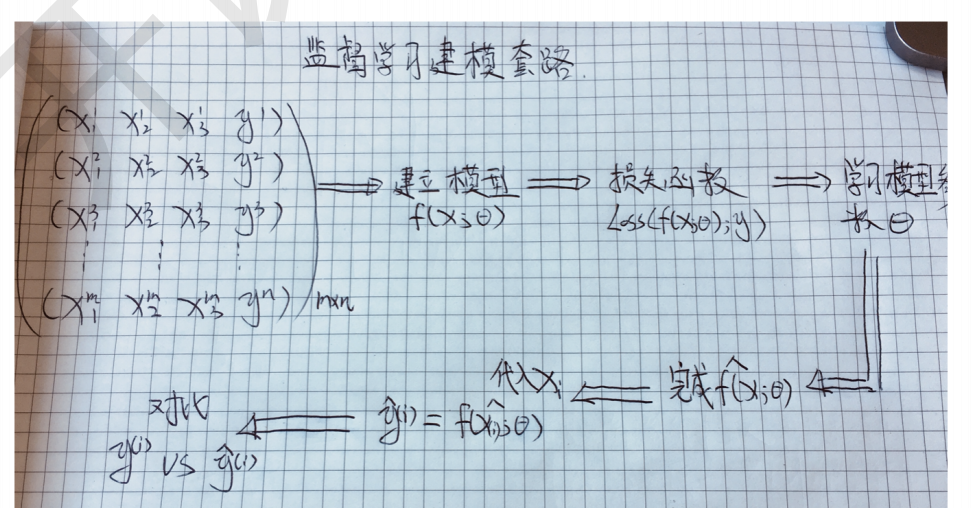

5 工业代码中的细节
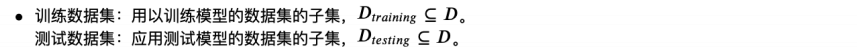
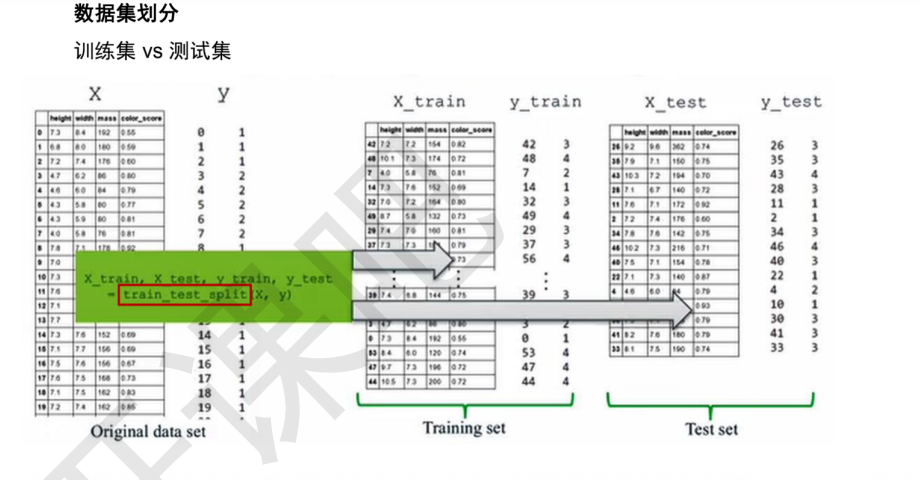

6 总结
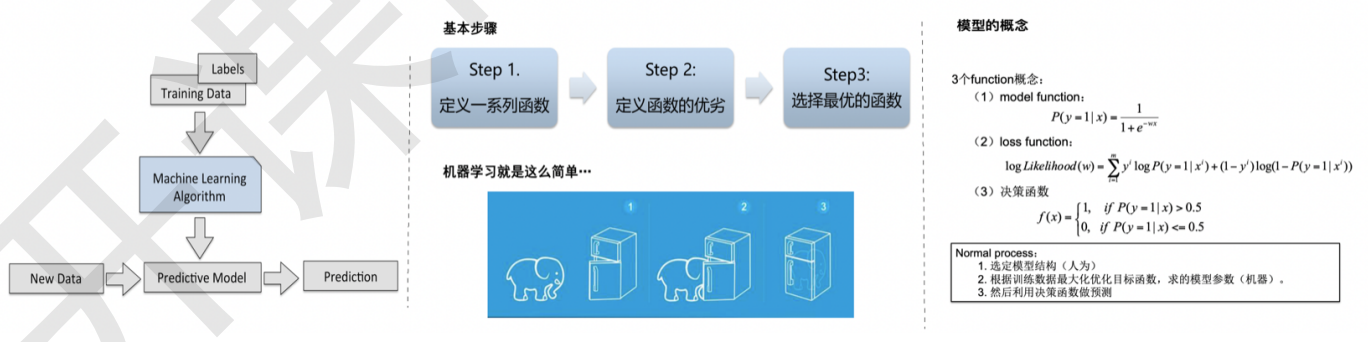
机器学习流程
模型(model)、目标(cost function)、优化算法
step1:对于一个问题,需要首先建立一个模型,如回归或分类模型
step2:通过最小分类误差、最大似然或最大后验概率建立模型的代价函数;
step3:最优化问题求解