5、偏差和⽅差
5.1 偏差
偏差⼜称为表观误差,是指个别测定值与实际值之差。
算法在训练集上的错误率。
5.2 ⽅差
随机变量和其均值之间的偏离程度。
算法在训练集上的表现低于测试集的程度。
6、过拟合和⽋拟合
6.1 过拟合
过拟合指的是训练数据拟合程度过⾼的情况,也就是说模型在训练集上表现的很好,但是在测试集
和新的数据集上表现的较差。
6.2 ⽋拟合
当模型在训练集和测试集表现的都不好的时候我们就称这种现象为⽋拟合。
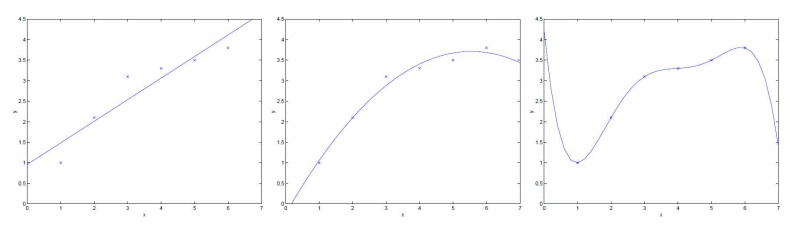
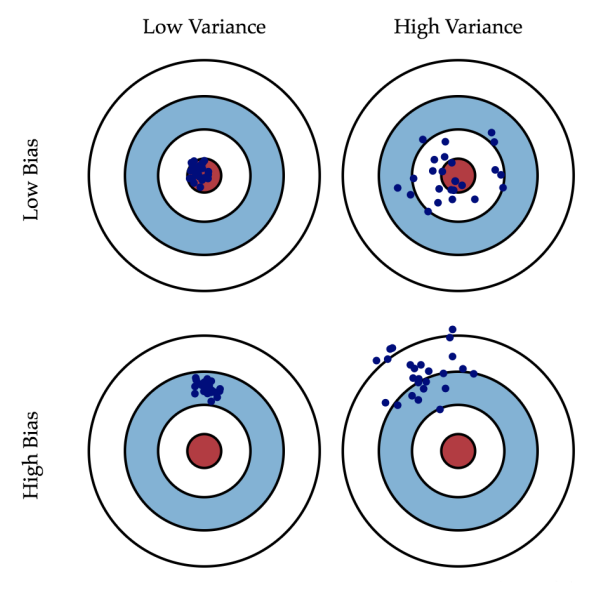
6.3 从⽅差和偏差的⻆度看
如果⼀个模型有低偏差,⾼⽅差便是过拟合,有⾼偏差,低⽅差便是⽋拟合。
6.4 过拟合和⽋拟合的解决办法
6.4.1 降低过拟合
增加数据量。更多的数据可以让模型学习到更多的有效特征,减⼩噪声的影响,从另⼀⽅⾯上讲,增加数据的数量也起到了减⼩⽅差的作⽤。
降低模型的复杂度。
神经⽹络:减少⽹络的层数,减少每⼀层⽹络的神经元个数。
树模型:剪枝,降低树的深度。
正则化
L1:绝对值之和,让⼀部分特征缩⼩到0,常⽤于特征选择。
L2:平⽅之和,让特征的系数都进⾏缩⼩,使求解稳定快速。
集成学习⽅法,多模型进⾏融合。
Boosting:该类模型中,后⼀个模型的输⼊会受到前⼀个模型的输出的影响。
Bagging:该模型中,模型之间相互独⽴,没有过⼤的影响。
6.4.2 降低⽋拟合
增加新的特征。
增加模型的复杂度。简单的模型学习能⼒较差,通过增加模型的复杂度可以使模型有更强的拟合能⼒。
减少正则化的系数。正则化是⽤来防⽌过拟合的,当模型⽋拟合时我们需要有针对的减少他们的系数。
六、总结
什么是随机变量
正态分布|伯努利分布
极⼤似然估计
偏差与⽅差
过拟合与⽋拟合