来源:https://blog.csdn.net/lujisen/article/details/105798504?utm_medium=distribute.wap_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.wap_blog_relevant_pic&depth_1-utm_source=distribute.wap_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.wap_blog_relevant_pic
一、概述
Flink流式计算的核心概念,就是将数据从Source输入流一个个传递给Operator进行链式处理,最后交给Sink输出流的过程。本篇文章主要讲解Sink端比较强大一个功能类StreamingFileSink,我们基于最新的Flink1.10.0版本进行讲解,之前版本可能使用BucketingSink,但是BucketingSink从Flink 1.9开始已经被废弃,并会在后续的版本中删除,这里只讲解StreamingFileSink相关特性。
二、StreamingFileSink相关特性
这个连接器提供了一个 Sink 来将分区文件写入到支持 Flink FileSystem 接口的文件系统中。
Streaming File Sink 会将数据写入到桶中。由于输入流可能是无界的,因此每个桶中的数据被划分为多个有限大小的文件。如何分桶是可以配置的,默认使用基于时间的分桶策略,这种策略每个小时创建一个新的桶,桶中包含的文件将记录所有该小时内从流中接收到的数据。
桶目录中的实际输出数据会被划分为多个部分文件(part file),每一个接收桶数据的 Sink Subtask ,至少包含一个部分文件(part file)。额外的部分文件(part file)将根据滚动策略创建,滚动策略是可以配置的。默认的策略是根据文件大小和超时时间来滚动文件。超时时间指打开文件的最长持续时间,以及文件关闭前的最长非活动时间。
重要:
使用 StreamingFileSink 时需要启用 Checkpoint ,每次做 Checkpoint 时写入完成。如果 Checkpoint 被禁用,部分文件(part file)将永远处于 'in-progress' 或 'pending' 状态,下游系统无法安全地读取。
1 part file生命周期
先来看一下官网的文件输出状态图:
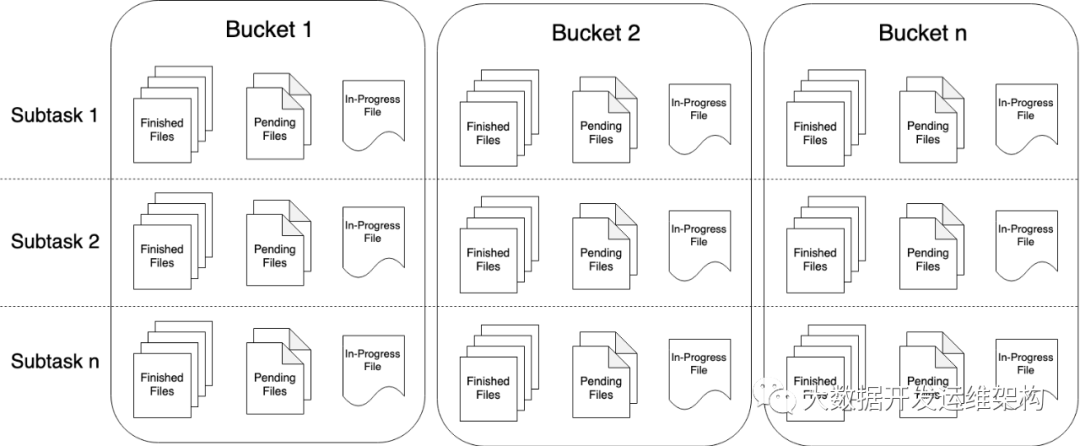
为了在下游系统中使用 StreamingFileSink 的输出,我们需要了解输出文件的命名规则和生命周期。由上图可知,部分文件(part file)可以处于以下三种状态之一:
1).In-progress :
当前文件正在写入中
2).Pending :
当处于 In-progress 状态的文件关闭(closed)了,就变为 Pending 状态
3).Finished :
在成功的 Checkpoint 后,Pending 状态将变为 Finished 状态,处于 Finished 状态的文件不会再被修改,可以被下游系统安全地读取。
重要:
部分文件的索引在每个 subtask 内部是严格递增的(按文件创建顺序)。但是索引并不总是连续的。当 Job 重启后,所有部分文件的索引从 `max part index + 1` 开始, 这里的 `max part index` 是所有 subtask 中索引的最大值。
2.文件编码格式
StreamingFileSink 支持行编码格式和批量编码格式,比如 Apache Parquet 。这两种变体可以使用以下静态方法创建:
1).Row-encoded sink:
StreamingFileSink.forRowFormat(basePath, rowEncoder)
2).Bulk-encoded sink:
StreamingFileSink.forBulkFormat(basePath, bulkWriterFactory)
//行编码 final StreamingFileSink<String> sink = StreamingFileSink .forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8")) .withRollingPolicy( DefaultRollingPolicy.builder() .withRolloverInterval(TimeUnit.MINUTES.toMillis(15)) .withInactivityInterval(TimeUnit.MINUTES.toMillis(5)) .withMaxPartSize(1024 * 1024 * 1024) .build()) .build(); //批量编码 final StreamingFileSink<GenericRecord> sink = StreamingFileSink .forBulkFormat(outputBasePath, ParquetAvroWriters.forGenericRecord(schema)) .build();
创建行或批量编码的 Sink 时,我们需要指定存储桶的基本路径和数据的编码逻辑,具体实现后面文章讲解。
重要:
批量编码模式仅支持 OnCheckpointRollingPolicy 策略, 在每次 checkpoint 的时候切割文件。
3.桶分配
桶分配逻辑定义了如何将数据结构化为基本输出目录中的子目录,行格式和批量格式都使用 DateTimeBucketAssigner 作为默认的分配器。默认情况下,DateTimeBucketAssigner 基于系统默认时区每小时创建一个桶,格式如下:yyyy-MM-dd--HH 。日期格式(即桶的大小)和时区都可以手动配置。
我们可以在格式构建器上调用 .withBucketAssigner(assigner) 来自定义 BucketAssigner 。
Flink 有两个内置的 BucketAssigners :
1).DateTimeBucketAssigner :默认基于时间的分配器
2).BasePathBucketAssigner :将所有部分文件(part file)存储在基本路径中的分配器(单个全局桶)
4.滚动策略
滚动策略 RollingPolicy 定义了指定的文件在何时关闭(closed)并将其变为 Pending 状态,随后变为 Finished 状态。处于 Pending 状态的文件会在下一次 Checkpoint 时变为 Finished 状态,通过设置 Checkpoint 间隔时间,可以控制部分文件(part file)对下游读取者可用的速度、大小和数量。
Flink 有两个内置的滚动策略:
1).DefaultRollingPolicy
2).OnCheckpointRollingPolicy
5.part file相关配置项
已经完成的文件和进行中的文件仅能通过文件名格式进行区分。
默认情况下,文件命名格式如下所示:
1).In-progress/Pending:
part-<subtaskIndex>-<partFileIndex>.inprogress.uid
2).FINISHED:
part-<subtaskIndex>-<partFileIndex>
Flink 允许用户通过 OutputFileConfig 指定部分文件名的前缀和后缀。举例来说,前缀设置为 “prefix” 以及后缀设置为 “.ext” 之后,Sink 创建的文件名如下所示:
└── 2019-08-25--12 ├── prefix-0-0.ext ├── prefix-0-1.ext.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334 ├── prefix-1-0.ext └── prefix-1-1.ext.inprogress.bc279efe-b16f-47d8-b828-00ef6e2fbd11
用户可以通过如下方式设置 OutputFileConfig:
OutputFileConfig config = OutputFileConfig .builder() .withPartPrefix("prefix") .withPartSuffix(".ext") .build(); StreamingFileSink<Tuple2<Integer, Integer>> sink = StreamingFileSink .forRowFormat((new Path(outputPath), new SimpleStringEncoder<>("UTF-8")) .withBucketAssigner(new KeyBucketAssigner()) .withRollingPolicy(OnCheckpointRollingPolicy.build()) .withOutputFileConfig(config) .build();
三、代码实战
下面就通过一个实例子分别来说明下StreamingFileSink各个特性的使用方法,请仔细阅读代码注释:
package com.hadoop.ljs.flink110.sink; import com.hadoop.ljs.flink110.source.CustomSource1; import com.hadoop.ljs.flink110.source.StudentInfo; import org.apache.flink.api.common.serialization.SimpleStringEncoder; import org.apache.flink.core.fs.Path; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.sink.filesystem.OutputFileConfig; import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink; import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.DateTimeBucketAssigner; import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy; import java.util.concurrent.TimeUnit; /** * @author: Created By lujisen * @company ChinaUnicom Software JiNan * @date: 2020-04-26 20:53 * @version: v1.0 * @description: com.hadoop.ljs.flink110.sink */ public class StreamingFileSinkTest { public static void main(String[] args) throws Exception { System.setProperty("HADOOP_USER_NAME","hdfs"); StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment(); senv.setParallelism(1); senv.enableCheckpointing(10 * 1000); /*指定source*/ DataStream<StudentInfo> source = senv.addSource(new CustomSource1()).setParallelism(1); /*自定义滚动策略*/ DefaultRollingPolicy<StudentInfo, String> rollPolicy = DefaultRollingPolicy.builder() .withRolloverInterval(TimeUnit.MINUTES.toMillis(2))/*每隔多长时间生成一个文件*/ .withInactivityInterval(TimeUnit.MINUTES.toMillis(5))/*默认60秒,未写入数据处于不活跃状态超时会滚动新文件*/ .withMaxPartSize(128 * 1024 * 1024)/*设置每个文件的最大大小 ,默认是128M*/ .build(); /*输出文件的前、后缀配置*/ OutputFileConfig config = OutputFileConfig .builder() .withPartPrefix("prefix") .withPartSuffix(".txt") .build(); StreamingFileSink<StudentInfo> streamingFileSink = StreamingFileSink /*forRowFormat指定文件的跟目录与文件写入编码方式,这里使用SimpleStringEncoder 以UTF-8字符串编码方式写入文件*/ .forRowFormat(new Path("hdfs://192.168.0.101:8020/tmp/hdfsSink"), new SimpleStringEncoder<StudentInfo>("UTF-8")) /*这里是采用默认的分桶策略DateTimeBucketAssigner,它基于时间的分配器,每小时产生一个桶,格式如下yyyy-MM-dd--HH*/ .withBucketAssigner(new DateTimeBucketAssigner<>()) /*设置上面指定的滚动策略*/ .withRollingPolicy(rollPolicy) /*桶检查间隔,这里设置为1s*/ .withBucketCheckInterval(1) /*指定输出文件的前、后缀*/ .withOutputFileConfig(config) .build(); /*指定sink*/ source.addSink(streamingFileSink); /*启动执行*/ senv.execute("StreamingFileSinkTest"); } }