ItemLoader
在我们执行scrapy爬取字段中,会有大量的CSS或是Xpath代码,当要爬取的网站多了,要维护起来很麻烦,为解决这类问题,我们可以根据scrapy提供的loader机制。
导入ItemLoader
from scrapy.loader import ItemLoader
实例化ItemLoader对象
要使用Itemloader,必须先将它实例化。查看一下ItemLoader的源码,有2个重要的传入参数,item和response

# 通过ItemLoader对象实例化item item_loader = ItemLoader(item=JobBoleArticleItem(), response=response) # 针对CSS选择器 item_loader.add_css('title', '.entry-header h1::text') item_loader.add_css('create_date', '.entry-meta .entry-meta-hide-on-mobile::text') item_loader.add_css('praise_num', '.vote-post-up h10::text') item_loader.add_css('collect_num', '.post-adds .bookmark-btn::text') item_loader.add_css('comment_num', '.post-adds .hide-on-480::text') # 针对直接取值的情况 item_loader.add_value('url', response.url) item_loader.add_value('url_object_id', get_md5(response.url)) item_loader.add_value('front_image_url', [front_image_url]) # 把结果返回给item对象 article_item = item_loader.load_item()
Debug调试查看情况
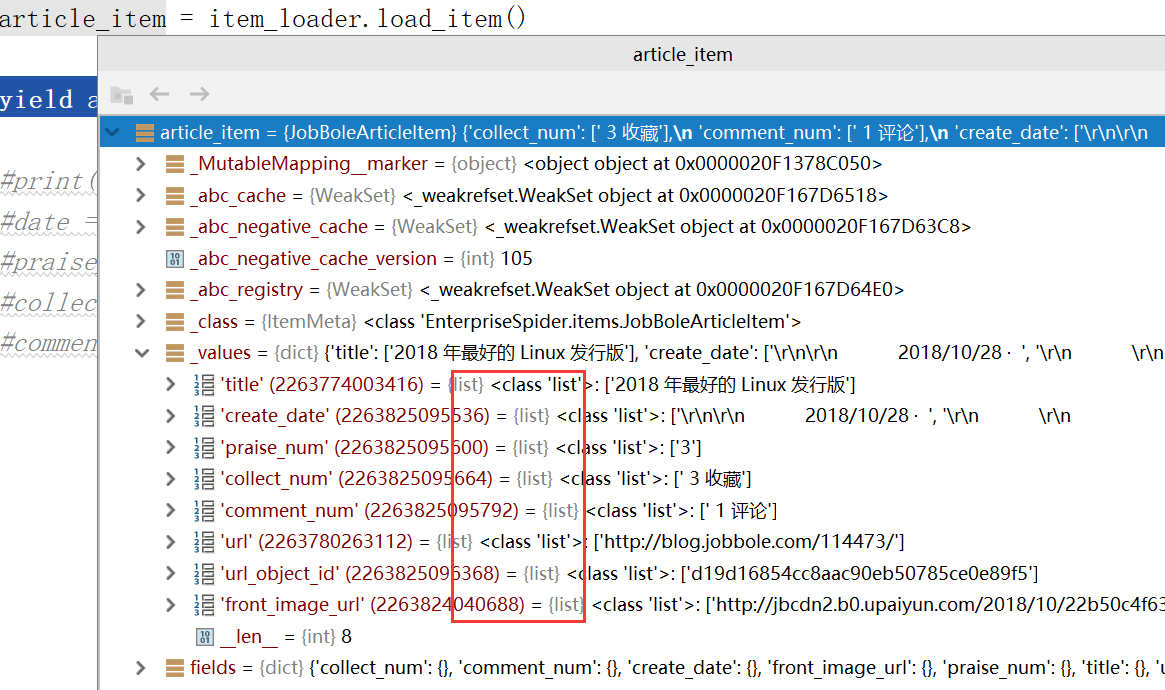
调用默认的item方法目前有2个问题:
(1)默认情况下传入的都是一些list
(2)像parise_num和comment_num传入的一些值我们还需要在进行一次过滤,加一些处理函数
MapCompose
如果解决上面两个问题?如何取list第一个值,如何在某些字段上加一些处理函数?为了解决这个问题,我们需要重新修改items.py,需要导入MapCompose类
from scrapy.loader.processors import MapCompose

MapCompose里面可以传入任意多的函数,也可以传入一些lambda表达式
title = scrapy.Field( # 代表当item传入值的时候,我们可以对这些值进行一些预处理,MapCompose可以传入任意多个函数 input_processor = MapCompose(lambda x:x+"-jobbole") )
此时在进行Debug调试,title上会添加-jobbole

我们可以在加入一个函数,现在MapCompose里面有一个lambda表达式,一个函数,Debug看是否能够连续处理

Debug

经测试可以从左到右依次连续进行处理
TakeFirst
那如何获取list中的第一个值,此时需要TakeFirst函数
导入
from scrapy.loader.processors import MapCompose, TakeFirst
调用
create_date = scrapy.Field( input_processor = MapCompose(date_convert), output_processor = TakeFirst() )
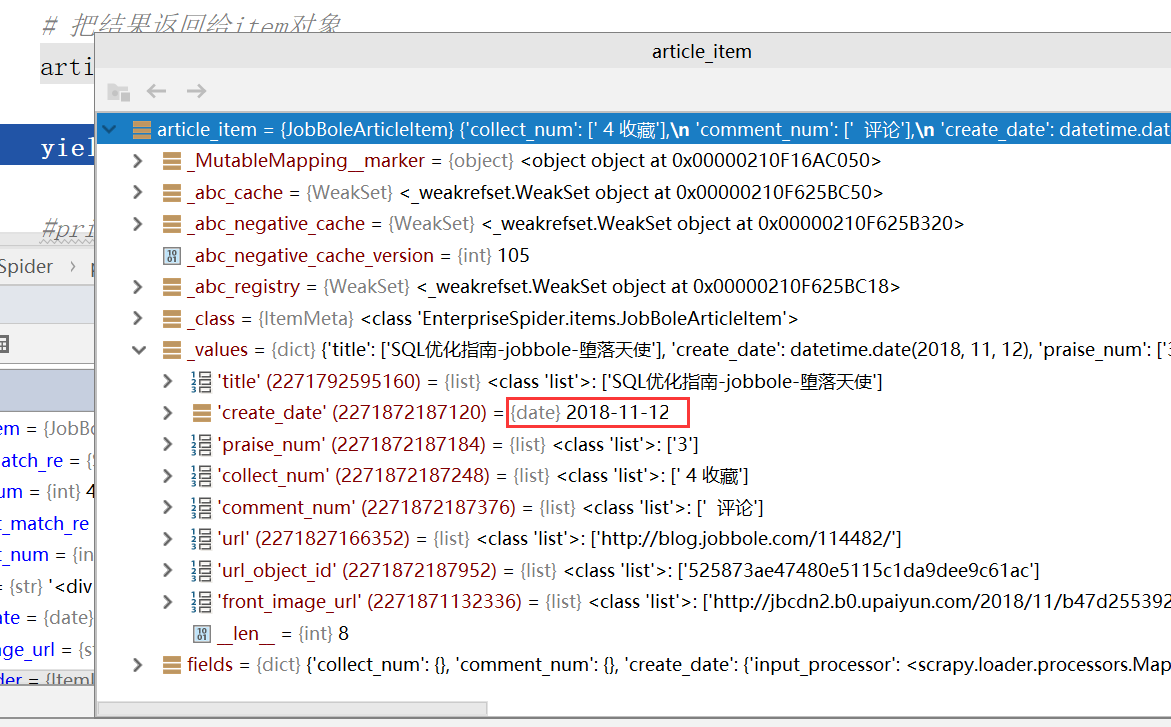
Debug调试,此时获取的create_time就是一个date类型的值了而不是一个list
自定义ItemLoader
如果所有的字段都去第一个值,是否每个字段都需要添加
output_processor = TakeFirst()
此时太麻烦,我们可以自己定义一个ItemLoader,需要继承scrapy的ItemLoader类
from scrapy.loader import ItemLoader class ArticleItemLoader(ItemLoader): pass
查看ItemLoader的源码,有一个默认的

修改默认的default_output_processor方法
class ArticleItemLoader(ItemLoader): default_output_processor = TakeFirst()
在修改我们爬虫里面ItemLoader为我们自定义的ItemLoader,在jobbole.py里面修改
from EnterpriseSpider.items import JobBoleArticleItem, ArticleItemLoader
# 通过ItemLoader对象实例化item item_loader = ArticleItemLoader(item=JobBoleArticleItem(), response=response)
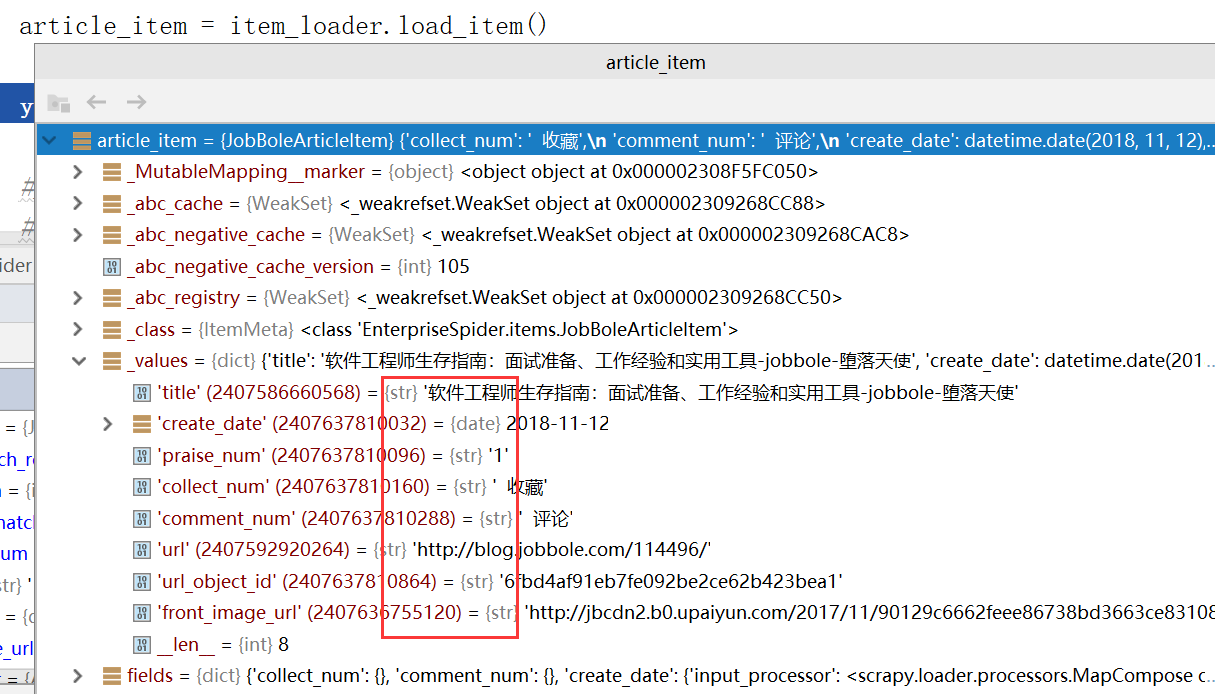
Debug调试,此时item返回的是单个的值而不是一个list
图片下载处理
此时返回的front_image_url是一个字符串,此时在交给ImagePipeline进行下载的时候就会抛出异常,我们必须覆盖掉默认的output_processor方法
def return_value(value): return value
front_image_url = scrapy.Field( output_processor=MapCompose(return_value) )
此时还需要修改插入数据库的语句,还需要修改ArticleImagePipeline
class ArticleImagePipeline(ImagesPipeline): def item_completed(self, results, item, info): if "front_image_url" in item: for ok, value in results: image_file_path = value["path"] item["front_image_url"] = image_file_path return item
default_output_processor